
🥥 Training Large Language Models to Reason in a Continuous Latent Space
Только что был выпущен код для нового подхода в обучении LLM ризонингу - "Coconut"(Chain of Continuous Thought).
Coconut позволяет LLM рассуждать более эффективно и результативно, особенно при комплексных задачах планирования.
Основная идея алгоритма - это улучшения рассуждений моделей с использованием латентного пространства, вместо выходных лексем
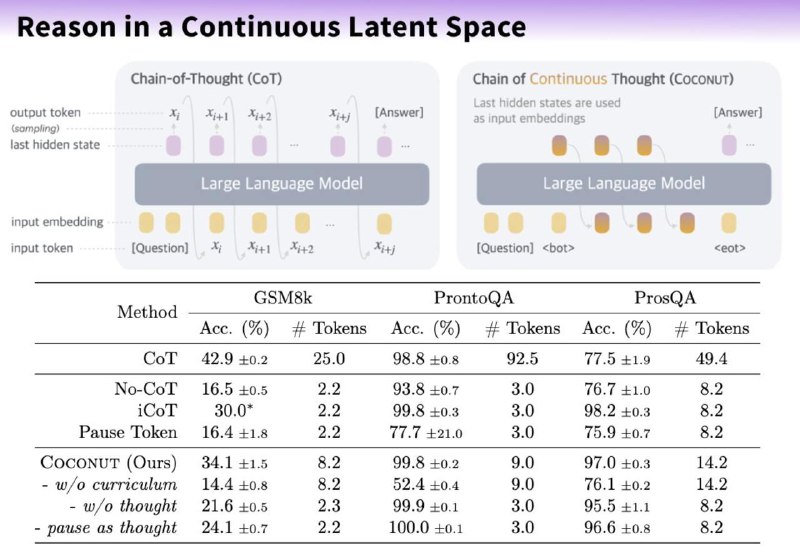
При таком подходе - цепочка мыслей генерирует не в виде текстовых токенов, а в виде эмбеддингов, а затем циклично подаются обратно в LLM.
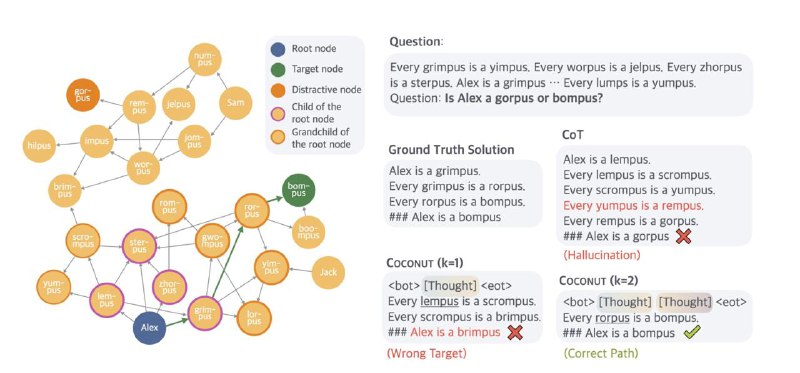
В «Coconut» у LLM есть два режима. Языковой режим работает как обычная языковая модель, генерируя текст и латентный режим, который использует скрытые состояния в качестве следующего входного сигнала, обозначенного специальными токенами
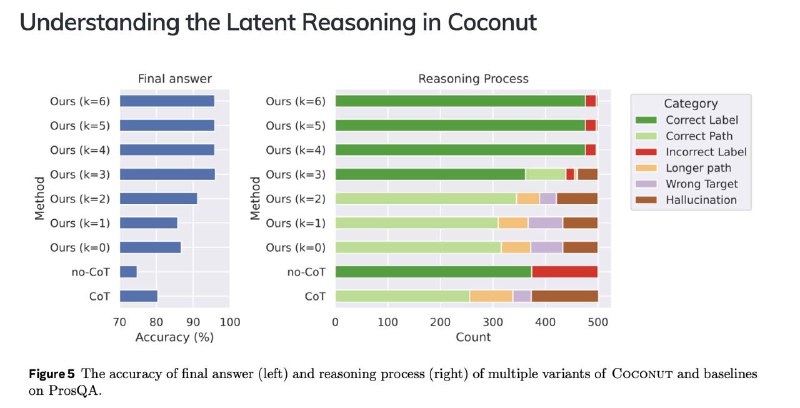
Скрытые состояния Coconut работают как дерево поиска, а не как линейная цепочка рассуждений, что позволяет модели исследовать несколько потенциальных путей одновременно.
На каждом шаге модель отдает приоритет перспективным узлам, отсекая менее релевантные.
Это помогает эффективнее справляться с задачами планирования и логики, по сравнению с традиционным методом работы CoT.
Как это работает:
1️⃣ Сначала модели подается промпт, за которым следует специальный токен <bot>, чтобы инициировать скрытое рассуждение.
2️⃣ Последнее скрытое состояние LLM после обработки <bot> используется в качестве первой "непрерывной мысли"
3️⃣ Непрерывная мысль подается обратно в модель как новый вход, генерируя новое скрытое состояние (новую мысль). Это повторяется в течение K итераций → цепочка непрерывных мыслей.
4️⃣ Далее добавляется маркер <eot> после последней непрерывной мысли, чтобы завершить скрытое рассуждение.
5️⃣ Последняя непрерывная мысль и <eot> затем используются для генерации ответа.
Такой подход, разумеется, требует большого количества ресурсов при обучении модели.
Плюсы такого подхода:
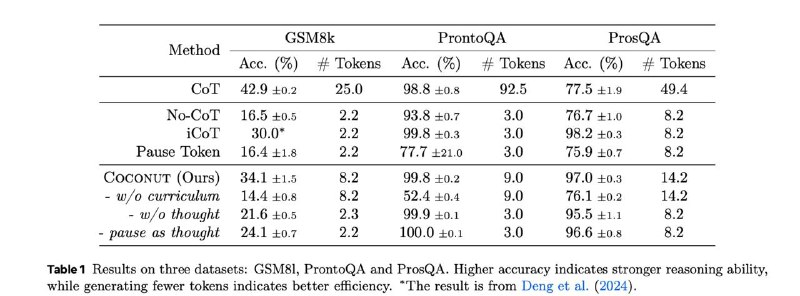
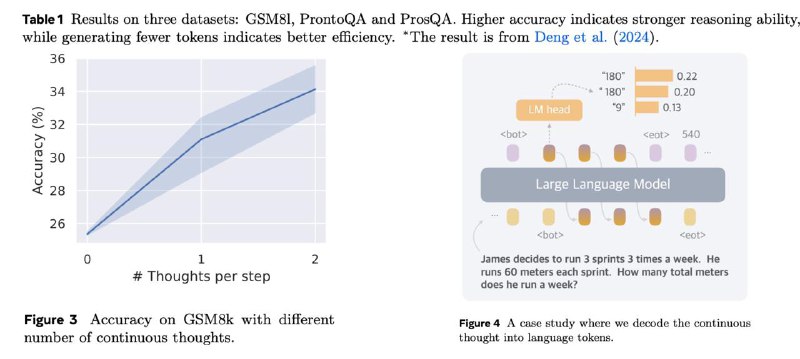
🏅 Превосходит CoT в задачах, где требуется планирования и сложные рассуждения, таких как ProntoQA и ProsQA
📉 Генерирует значительно меньше лексем во время размышлений по сравнению с CoT
🔀 Может выполнять поиск с широким охватом (BFS), кодируя одновременно несколько альтернативных следующих шагов
▪Github
▪Paper
@ai_machinelearning_big_data
#deeplearning #nlp #reasoning #llm #ml
Только что был выпущен код для нового подхода в обучении LLM ризонингу - "Coconut"(Chain of Continuous Thought).
Coconut позволяет LLM рассуждать более эффективно и результативно, особенно при комплексных задачах планирования.
Основная идея алгоритма - это улучшения рассуждений моделей с использованием латентного пространства, вместо выходных лексем
При таком подходе - цепочка мыслей генерирует не в виде текстовых токенов, а в виде эмбеддингов, а затем циклично подаются обратно в LLM.
В «Coconut» у LLM есть два режима. Языковой режим работает как обычная языковая модель, генерируя текст и латентный режим, который использует скрытые состояния в качестве следующего входного сигнала, обозначенного специальными токенами
<bot> и <eot>. Скрытые состояния Coconut работают как дерево поиска, а не как линейная цепочка рассуждений, что позволяет модели исследовать несколько потенциальных путей одновременно.
На каждом шаге модель отдает приоритет перспективным узлам, отсекая менее релевантные.
Это помогает эффективнее справляться с задачами планирования и логики, по сравнению с традиционным методом работы CoT.
Как это работает:
1️⃣ Сначала модели подается промпт, за которым следует специальный токен <bot>, чтобы инициировать скрытое рассуждение.
2️⃣ Последнее скрытое состояние LLM после обработки <bot> используется в качестве первой "непрерывной мысли"
3️⃣ Непрерывная мысль подается обратно в модель как новый вход, генерируя новое скрытое состояние (новую мысль). Это повторяется в течение K итераций → цепочка непрерывных мыслей.
4️⃣ Далее добавляется маркер <eot> после последней непрерывной мысли, чтобы завершить скрытое рассуждение.
5️⃣ Последняя непрерывная мысль и <eot> затем используются для генерации ответа.
Такой подход, разумеется, требует большого количества ресурсов при обучении модели.
Плюсы такого подхода:
🏅 Превосходит CoT в задачах, где требуется планирования и сложные рассуждения, таких как ProntoQA и ProsQA
📉 Генерирует значительно меньше лексем во время размышлений по сравнению с CoT
🔀 Может выполнять поиск с широким охватом (BFS), кодируя одновременно несколько альтернативных следующих шагов
git clone [email protected]:facebookresearch/coconut.git
cd coconut▪Github
▪Paper
@ai_machinelearning_big_data
#deeplearning #nlp #reasoning #llm #ml
group-telegram.com/ai_machinelearning_big_data/6563
Create:
Last Update:
Last Update:
🥥 Training Large Language Models to Reason in a Continuous Latent Space
Только что был выпущен код для нового подхода в обучении LLM ризонингу - "Coconut"(Chain of Continuous Thought).
Coconut позволяет LLM рассуждать более эффективно и результативно, особенно при комплексных задачах планирования.
Основная идея алгоритма - это улучшения рассуждений моделей с использованием латентного пространства, вместо выходных лексем
При таком подходе - цепочка мыслей генерирует не в виде текстовых токенов, а в виде эмбеддингов, а затем циклично подаются обратно в LLM.
В «Coconut» у LLM есть два режима. Языковой режим работает как обычная языковая модель, генерируя текст и латентный режим, который использует скрытые состояния в качестве следующего входного сигнала, обозначенного специальными токенами
Скрытые состояния Coconut работают как дерево поиска, а не как линейная цепочка рассуждений, что позволяет модели исследовать несколько потенциальных путей одновременно.
На каждом шаге модель отдает приоритет перспективным узлам, отсекая менее релевантные.
Это помогает эффективнее справляться с задачами планирования и логики, по сравнению с традиционным методом работы CoT.
Как это работает:
1️⃣ Сначала модели подается промпт, за которым следует специальный токен <bot>, чтобы инициировать скрытое рассуждение.
2️⃣ Последнее скрытое состояние LLM после обработки <bot> используется в качестве первой "непрерывной мысли"
3️⃣ Непрерывная мысль подается обратно в модель как новый вход, генерируя новое скрытое состояние (новую мысль). Это повторяется в течение K итераций → цепочка непрерывных мыслей.
4️⃣ Далее добавляется маркер <eot> после последней непрерывной мысли, чтобы завершить скрытое рассуждение.
5️⃣ Последняя непрерывная мысль и <eot> затем используются для генерации ответа.
Такой подход, разумеется, требует большого количества ресурсов при обучении модели.
Плюсы такого подхода:
🏅 Превосходит CoT в задачах, где требуется планирования и сложные рассуждения, таких как ProntoQA и ProsQA
📉 Генерирует значительно меньше лексем во время размышлений по сравнению с CoT
🔀 Может выполнять поиск с широким охватом (BFS), кодируя одновременно несколько альтернативных следующих шагов
▪Github
▪Paper
@ai_machinelearning_big_data
#deeplearning #nlp #reasoning #llm #ml
Только что был выпущен код для нового подхода в обучении LLM ризонингу - "Coconut"(Chain of Continuous Thought).
Coconut позволяет LLM рассуждать более эффективно и результативно, особенно при комплексных задачах планирования.
Основная идея алгоритма - это улучшения рассуждений моделей с использованием латентного пространства, вместо выходных лексем
При таком подходе - цепочка мыслей генерирует не в виде текстовых токенов, а в виде эмбеддингов, а затем циклично подаются обратно в LLM.
В «Coconut» у LLM есть два режима. Языковой режим работает как обычная языковая модель, генерируя текст и латентный режим, который использует скрытые состояния в качестве следующего входного сигнала, обозначенного специальными токенами
<bot> и <eot>. Скрытые состояния Coconut работают как дерево поиска, а не как линейная цепочка рассуждений, что позволяет модели исследовать несколько потенциальных путей одновременно.
На каждом шаге модель отдает приоритет перспективным узлам, отсекая менее релевантные.
Это помогает эффективнее справляться с задачами планирования и логики, по сравнению с традиционным методом работы CoT.
Как это работает:
1️⃣ Сначала модели подается промпт, за которым следует специальный токен <bot>, чтобы инициировать скрытое рассуждение.
2️⃣ Последнее скрытое состояние LLM после обработки <bot> используется в качестве первой "непрерывной мысли"
3️⃣ Непрерывная мысль подается обратно в модель как новый вход, генерируя новое скрытое состояние (новую мысль). Это повторяется в течение K итераций → цепочка непрерывных мыслей.
4️⃣ Далее добавляется маркер <eot> после последней непрерывной мысли, чтобы завершить скрытое рассуждение.
5️⃣ Последняя непрерывная мысль и <eot> затем используются для генерации ответа.
Такой подход, разумеется, требует большого количества ресурсов при обучении модели.
Плюсы такого подхода:
🏅 Превосходит CoT в задачах, где требуется планирования и сложные рассуждения, таких как ProntoQA и ProsQA
📉 Генерирует значительно меньше лексем во время размышлений по сравнению с CoT
🔀 Может выполнять поиск с широким охватом (BFS), кодируя одновременно несколько альтернативных следующих шагов
git clone [email protected]:facebookresearch/coconut.git
cd coconut▪Github
▪Paper
@ai_machinelearning_big_data
#deeplearning #nlp #reasoning #llm #ml
BY Machinelearning

Share with your friend now:
group-telegram.com/ai_machinelearning_big_data/6563