
⭐️ Mistral AI только что дропнули Small 3!
Вот все, что вам нужно знать:
- 24B параметров
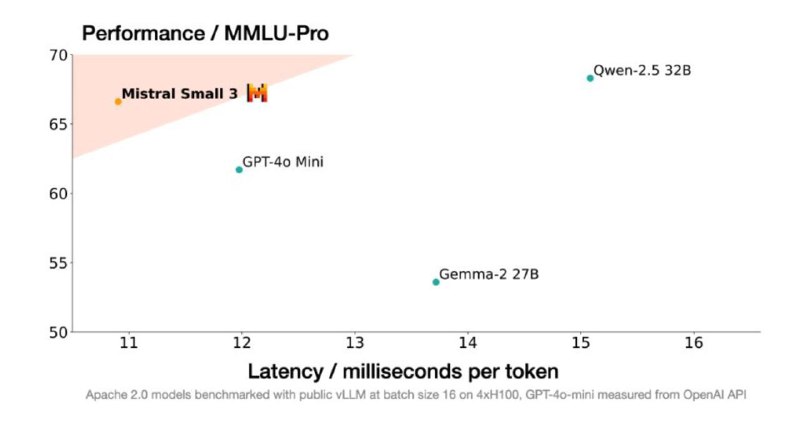
- 81% точности на MMLU и задержка 150 токенов/с
- Позиционируется как замена GPT-40-mini
- Конкурирует с Llama 3.3 70B и Qwen 32B
- в 3 раза быстрее, чем Llama 3.3 70B
- Лицензия Apache 2.0
- Доступны как предварительно обученные, так и настроенные контрольные точки
- без RL и без синтетических данных
- Доступно на la Plateforme, HF и других провайдерах
Великолепная маленькая модель, которая дополняет другие более крупные модели, такие как DeepSeek-R1.
▪HF: https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501
▪Blog: https://mistral.ai/news/mistral-small-3/
@ai_machinelearning_big_data
#mistral #llm #ml #ai
Вот все, что вам нужно знать:
- 24B параметров
- 81% точности на MMLU и задержка 150 токенов/с
- Позиционируется как замена GPT-40-mini
- Конкурирует с Llama 3.3 70B и Qwen 32B
- в 3 раза быстрее, чем Llama 3.3 70B
- Лицензия Apache 2.0
- Доступны как предварительно обученные, так и настроенные контрольные точки
- без RL и без синтетических данных
- Доступно на la Plateforme, HF и других провайдерах
Великолепная маленькая модель, которая дополняет другие более крупные модели, такие как DeepSeek-R1.
▪HF: https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501
▪Blog: https://mistral.ai/news/mistral-small-3/
@ai_machinelearning_big_data
#mistral #llm #ml #ai
group-telegram.com/ai_machinelearning_big_data/6678
Create:
Last Update:
Last Update:
⭐️ Mistral AI только что дропнули Small 3!
Вот все, что вам нужно знать:
- 24B параметров
- 81% точности на MMLU и задержка 150 токенов/с
- Позиционируется как замена GPT-40-mini
- Конкурирует с Llama 3.3 70B и Qwen 32B
- в 3 раза быстрее, чем Llama 3.3 70B
- Лицензия Apache 2.0
- Доступны как предварительно обученные, так и настроенные контрольные точки
- без RL и без синтетических данных
- Доступно на la Plateforme, HF и других провайдерах
Великолепная маленькая модель, которая дополняет другие более крупные модели, такие как DeepSeek-R1.
▪HF: https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501
▪Blog: https://mistral.ai/news/mistral-small-3/
@ai_machinelearning_big_data
#mistral #llm #ml #ai
Вот все, что вам нужно знать:
- 24B параметров
- 81% точности на MMLU и задержка 150 токенов/с
- Позиционируется как замена GPT-40-mini
- Конкурирует с Llama 3.3 70B и Qwen 32B
- в 3 раза быстрее, чем Llama 3.3 70B
- Лицензия Apache 2.0
- Доступны как предварительно обученные, так и настроенные контрольные точки
- без RL и без синтетических данных
- Доступно на la Plateforme, HF и других провайдерах
Великолепная маленькая модель, которая дополняет другие более крупные модели, такие как DeepSeek-R1.
▪HF: https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501
▪Blog: https://mistral.ai/news/mistral-small-3/
@ai_machinelearning_big_data
#mistral #llm #ml #ai
BY Machinelearning

Share with your friend now:
group-telegram.com/ai_machinelearning_big_data/6678