group-telegram.com/ai_machinelearning_big_data/7329
Last Update:
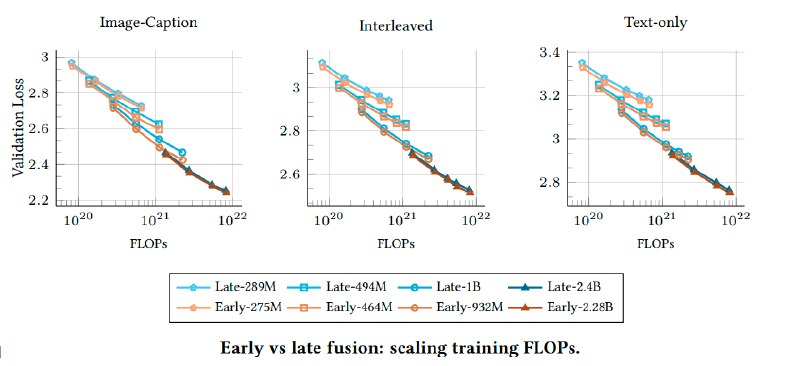
Исследование, проведенное Apple и Университетом Сорбонны в котором были проанализировали 457 архитектур, чтобы выяснить, действительно ли позднее слияние модальностей (late-fusion — когда изображения и текст обрабатываются отдельно до объединения ) имеет преимущества перед ранним слиянием (early-fusion). Оказалось, что early-fusion не только не уступают, но и превосходятlate-fusion при ограниченных ресурсах, требуя меньше параметров и быстрее обучаясь.
Early-fusion, где данные разных модальностей объединяются на начальных этапах, показал более высокую эффективность на небольших моделях. На модели с 300 млн. параметров такие архитектуры достигают лучших результатов с меньшими вычислительными затратами. Плюс, их проще развертывать — отсутствие отдельных визуальных энкодеров сокращает требования к инфраструктуре.
Оптимальное соотношение параметров и данных для обучения почти одинаково, но early-fusion требует меньше параметров при том же бюджете: при увеличении вычислительных ресурсов late-fusion вынуждена наращивать размер модели, тогда как early-fusion эффективнее использует дополнительные токены.
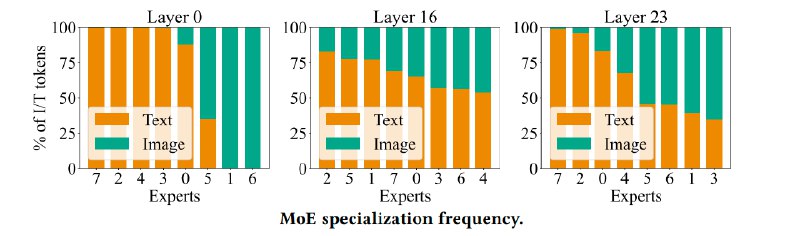
Авторы также проверили, как влияет на результаты внедрение MoE — техники, где модель динамически распределяет специализированные «эксперты» для разных типов данных.
Оказалось, MoE значительно улучшает производительность: разреженные модели с 8 экспертами сокращают потери на 15-20% по сравнению с плотными аналогами. При этом эксперты неявно специализируются — часть обрабатывает текст, другая фокусируется на изображениях, особенно в начальных и финальных слоях.
@ai_machinelearning_big_data
#AI #ML #MMLM #ScalingLaw #MoE