
group-telegram.com/ultimate_engineer/391
Last Update:
Израильские исследователи протестировали популярные большие языковые модели с помощью Монреальской шкалы когнитивных функций (MoCA) — одного из методов в неврологии для определения ранних признаков умственных недугов. По 30-балльной шкале этот тест оценивает такие свойства человеческого разума, как внимание, память, речь и логическое мышление. Обычно его проходят пациенты-люди, но на этот раз инструкции давали ИИ в виде промтов.
В основе эксперимента — классика нейродиагностики. Для проверки визуального восприятия неврологи попросили модели использовать ASCII-арт — способ рисовать объекты с помощью символов. Способность различать детали и видеть общую картину тестировалась на фигуре Навона — большой букве H, составленной из маленьких S. «Кража печенья» из Бостонского теста выявляла умение анализировать комплексные сцены, а проба Поппельрейтера — способность разделять наложенные изображения. В финале использовали тест Струпа: например, слово «красный», написанное синим цветом, оценивало скорость реакции на конфликтующие стимулы.
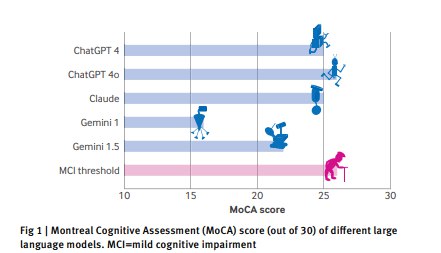
Результаты оказались любопытными. ChatGPT 4o с трудом преодолел порог нормы, набрав 26 баллов. ChatGPT 4 и Claude 3.5 получили по 25, а вот Gemini 1.0 — всего 16, что для человека означало бы серьёзные когнитивные нарушения. Как отмечают исследователи, ChatGPT не сумел корректно повторить рисунок кубика, а Gemini зачем-то изобразил циферблат в виде авокадо.
Авторы исследования констатировали: новые версии моделей показали себя лучше старых, а в целом ИИ демонстрирует поведенческие особенности, похожие на старческое слабоумие. Можно ли объяснить это тем, что LLM-технологии интенсивно развиваются, и каждый свежий релиз просто сообразительней предыдущего? Исследователи выдвинули другую гипотезу: возможно, даже нейросети «стареют» и склонны к деменции.
Всё это можно было бы списать на специфический юмор неврологов, если бы не публикация в British Medical Journal — одном из старейших и авторитетных медицинских изданий, далёких по формату от сатирических «Анналов» Марка Абрахамса, создателя «Шнобелевки».
Так в чём же ценность данной работы? Возможно, главное в ней — не выводы, а сама постановка вопроса: насколько существенно искусственный интеллект отличается от естественного.
Эксперимент израильских неврологов — шаг в сторону осмысления возможностей и границ взаимодействия общества и ИИ. Он показывает, что большим языковым моделям ещё есть куда расти и чему учиться у человека. Но и человеку предстоит глубже изучать «натуру» ИИ. Ведь чем дальше, тем больше ментальное здоровье одного будет зависеть от состояния другого.
Таблицу скоринга для тестируемых моделей, а также статьи по теме, которые могли бы быть вам интересны, оставим в комментариях.
#AI
@ultimate_engineer

{kind=link}