
group-telegram.com/llmsecurity/169
Create:
Last Update:
Last Update:
Refusal in Language Models Is Mediated by a Single Direction
Arditi et al, 2024
Статья, блог, код
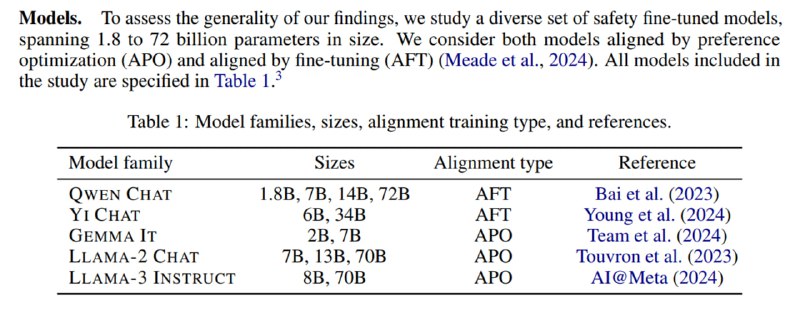
Захватывающий препринт про то, что происходит внутри моделей, которые учат отказываться следовать вредоносным инструкциям. Оказывается (почему-то задним умом это кажется геометрически очевидным – ведь мы по сути учим бинарный классификатор), что генерация отказа в пространстве активаций представлена единым направлением, и если его в процессе генерации из активаций вычесть, то можно получить безотказную модель – и это работает для 13 разных открытых моделей из пяти семейств размером до 72 миллиардов параметров.
BY llm security и каланы
Share with your friend now:
group-telegram.com/llmsecurity/169