
У Meta вышла громкая работа о новом способе токенизации
Токенизация – вообще одна из ключевых проблем LLM. Именно из-за токенизации модели плохо справляются с математикой. Токенайзер может токенизировать 380 как "380", а 381 как "38" и "1", то есть модель на самом деле просто не понимает, что представляет из себя число. При этом токен != слово и токен != слог. Токен – это вообще нечто нечеткое. Отсюда проблемы с элементарными фонетическими задачами вроде подсчета количества букв r в слове strawberry (больше примеров, в которых модельки фейлятся из-за токенизации см. здесь).
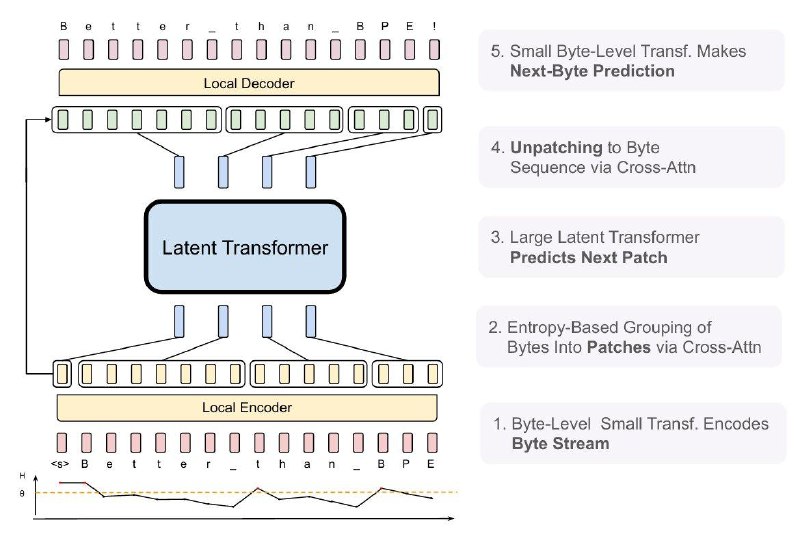
Чтобы попытаться решить эти проблемы, Meta предложили в качестве альтернативы токенам обычные байты. Тут надо сказать, что идея вообще-то не новая, еще давно уже выходила похожая token-free LM MambaByte. Но у Meta, во избежании слишком длинных последовательностей битов, впервые повляется динамический энкодинг в патчи.
Эти патчи и служат основными единицами вычисления, и внутри модели решается задача предсказания следующего патча. Патчи сегментируются динамически на основе энтропии следующего байта. Получается, если данные более "предсказуемы", то патчи получаются подлиннее, и наоборот. Однако перед группировкой байты все равно обрабатываются локальным энкодером, аналогично после предсказания следующего патча приходится подключать декодер.
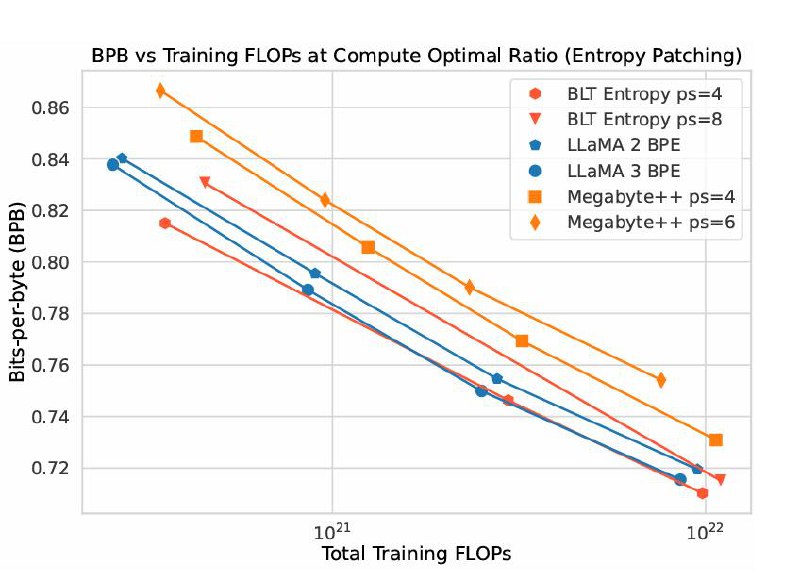
На бечмарках все очень многообещающе: BLT (Byte Latent Transformer) находится на одном уровне или даже немного выше LLama 3 с BPE по перплексии (BPB на графике – это метрика перплексии, не зависяща от токенизатора). При этом подход масштабируется, и исследователям даже удалось обучить токен-фри Llama-3 8B на датасете 1Т токенов, и она оказалась в среднем немного лучше, чем Llama-3 с BPE.
Обязательно почитайте полностью, это очень интересно
Токенизация – вообще одна из ключевых проблем LLM. Именно из-за токенизации модели плохо справляются с математикой. Токенайзер может токенизировать 380 как "380", а 381 как "38" и "1", то есть модель на самом деле просто не понимает, что представляет из себя число. При этом токен != слово и токен != слог. Токен – это вообще нечто нечеткое. Отсюда проблемы с элементарными фонетическими задачами вроде подсчета количества букв r в слове strawberry (больше примеров, в которых модельки фейлятся из-за токенизации см. здесь).
Чтобы попытаться решить эти проблемы, Meta предложили в качестве альтернативы токенам обычные байты. Тут надо сказать, что идея вообще-то не новая, еще давно уже выходила похожая token-free LM MambaByte. Но у Meta, во избежании слишком длинных последовательностей битов, впервые повляется динамический энкодинг в патчи.
Эти патчи и служат основными единицами вычисления, и внутри модели решается задача предсказания следующего патча. Патчи сегментируются динамически на основе энтропии следующего байта. Получается, если данные более "предсказуемы", то патчи получаются подлиннее, и наоборот. Однако перед группировкой байты все равно обрабатываются локальным энкодером, аналогично после предсказания следующего патча приходится подключать декодер.
На бечмарках все очень многообещающе: BLT (Byte Latent Transformer) находится на одном уровне или даже немного выше LLama 3 с BPE по перплексии (BPB на графике – это метрика перплексии, не зависяща от токенизатора). При этом подход масштабируется, и исследователям даже удалось обучить токен-фри Llama-3 8B на датасете 1Т токенов, и она оказалась в среднем немного лучше, чем Llama-3 с BPE.
Обязательно почитайте полностью, это очень интересно
👍83🤯27❤14🔥7🤔3
group-telegram.com/data_secrets/5702
Create:
Last Update:
Last Update:
У Meta вышла громкая работа о новом способе токенизации
Токенизация – вообще одна из ключевых проблем LLM. Именно из-за токенизации модели плохо справляются с математикой. Токенайзер может токенизировать 380 как "380", а 381 как "38" и "1", то есть модель на самом деле просто не понимает, что представляет из себя число. При этом токен != слово и токен != слог. Токен – это вообще нечто нечеткое. Отсюда проблемы с элементарными фонетическими задачами вроде подсчета количества букв r в слове strawberry (больше примеров, в которых модельки фейлятся из-за токенизации см. здесь).
Чтобы попытаться решить эти проблемы, Meta предложили в качестве альтернативы токенам обычные байты. Тут надо сказать, что идея вообще-то не новая, еще давно уже выходила похожая token-free LM MambaByte. Но у Meta, во избежании слишком длинных последовательностей битов, впервые повляется динамический энкодинг в патчи.
Эти патчи и служат основными единицами вычисления, и внутри модели решается задача предсказания следующего патча. Патчи сегментируются динамически на основе энтропии следующего байта. Получается, если данные более "предсказуемы", то патчи получаются подлиннее, и наоборот. Однако перед группировкой байты все равно обрабатываются локальным энкодером, аналогично после предсказания следующего патча приходится подключать декодер.
На бечмарках все очень многообещающе: BLT (Byte Latent Transformer) находится на одном уровне или даже немного выше LLama 3 с BPE по перплексии (BPB на графике – это метрика перплексии, не зависяща от токенизатора). При этом подход масштабируется, и исследователям даже удалось обучить токен-фри Llama-3 8B на датасете 1Т токенов, и она оказалась в среднем немного лучше, чем Llama-3 с BPE.
Обязательно почитайте полностью, это очень интересно
Токенизация – вообще одна из ключевых проблем LLM. Именно из-за токенизации модели плохо справляются с математикой. Токенайзер может токенизировать 380 как "380", а 381 как "38" и "1", то есть модель на самом деле просто не понимает, что представляет из себя число. При этом токен != слово и токен != слог. Токен – это вообще нечто нечеткое. Отсюда проблемы с элементарными фонетическими задачами вроде подсчета количества букв r в слове strawberry (больше примеров, в которых модельки фейлятся из-за токенизации см. здесь).
Чтобы попытаться решить эти проблемы, Meta предложили в качестве альтернативы токенам обычные байты. Тут надо сказать, что идея вообще-то не новая, еще давно уже выходила похожая token-free LM MambaByte. Но у Meta, во избежании слишком длинных последовательностей битов, впервые повляется динамический энкодинг в патчи.
Эти патчи и служат основными единицами вычисления, и внутри модели решается задача предсказания следующего патча. Патчи сегментируются динамически на основе энтропии следующего байта. Получается, если данные более "предсказуемы", то патчи получаются подлиннее, и наоборот. Однако перед группировкой байты все равно обрабатываются локальным энкодером, аналогично после предсказания следующего патча приходится подключать декодер.
На бечмарках все очень многообещающе: BLT (Byte Latent Transformer) находится на одном уровне или даже немного выше LLama 3 с BPE по перплексии (BPB на графике – это метрика перплексии, не зависяща от токенизатора). При этом подход масштабируется, и исследователям даже удалось обучить токен-фри Llama-3 8B на датасете 1Т токенов, и она оказалась в среднем немного лучше, чем Llama-3 с BPE.
Обязательно почитайте полностью, это очень интересно
BY Data Secrets


Share with your friend now:
group-telegram.com/data_secrets/5702