#osmdata #spatialanalysis
История из OSM или где "развиваются" в Кувейте
Дано: страна Кувейт- маленькая страна на берегу Персидского залива, зажатая между Саудовской Аравией и Ираком. 90% страны - пустыня, есть один крупный город и несколько растущих маленьких городов.
Задача: нужно найти самые быстро застраиваемые, а значит, перспективные для бизнеса, районы страны на основе открытых данных.
Данные:
- берём данные по дорогам, зданиям и POIs из OSM
- не берём building footprints - Microsoft не хранит историю, только актуальный срез
- не берём снимки со спутника, так никто в команде никогда не делал image recognition, а на задачу 2 дня
- Не берем worldpop, kontur - там нет истории и есть большая погрешность
Решение:
1. Загрузить историю изменений инфраструктуры за последние несколько лет, пересечь с гексагональной сеткой
2. Посчитать абсолютную дельту за последние 3 года, 1 год и 6 месяцев; посчитать ежемесячную скорость прироста за последние 3 года, 1 год и 6 месяцев
3. Сделать вывод: район не развивается/ район был застроен год назад и нет новой застройки/ район все еще активно застраивается
4. Нанести результаты на карту. Найти 3-ий тип районов
5. Подтвердить картинку с помощью Local Moran's I - найти наиболее позитивно выделяющиеся кластеры
Инсайты из решения:
1. Можно верить только дорогам )
Если вы думаете что в России мало OSM данных, то вы точно никогда не занимались Кувайтом. Согласно OSM в Кувайте только в 1/4 главного города есть здания (way/relations=building), остальные люди видимо живут в шатрах🤷♀️. Тоже самое для POIs.
Остаются только дороги: они обновляются по спутникам,и поэтому отражают реальность (иногда с небольшой задержкой)
2. API Ohsome- самый удобный способ загружать историю OSM из Python. Подходит, если размер территории не большой, Иначе проще работать с архивами датасетов.
Документация: тут
Мой пример скрипта на загрузку дорог: тут
3. В странах, где мало данных, длина сегментов дороги варьируется от 1 м до 36 км, когда обычно сегмент не превышает 1 км. Поэтому при сцепке с сеткой гексагонов надо помнить, что одна дорога пересекает несколько гексов
4. Для расчета дельты изменений суммарная длина дорог подошла лучше количества из-за неоднородности длины сегментов.
5. Такой анализ помогает найти города, застраиваемые с нуля, но не помогает выявить уплотняемые территории (сравнение со спутником).
6. Данные о перемещении людей не помогают в такой задаче, поскольку появляются с лагом во времени - когда квартал уже застроен.
История из OSM или где "развиваются" в Кувейте
Дано: страна Кувейт- маленькая страна на берегу Персидского залива, зажатая между Саудовской Аравией и Ираком. 90% страны - пустыня, есть один крупный город и несколько растущих маленьких городов.
Задача: нужно найти самые быстро застраиваемые, а значит, перспективные для бизнеса, районы страны на основе открытых данных.
Данные:
- берём данные по дорогам, зданиям и POIs из OSM
- не берём building footprints - Microsoft не хранит историю, только актуальный срез
- не берём снимки со спутника, так никто в команде никогда не делал image recognition, а на задачу 2 дня
- Не берем worldpop, kontur - там нет истории и есть большая погрешность
Решение:
1. Загрузить историю изменений инфраструктуры за последние несколько лет, пересечь с гексагональной сеткой
2. Посчитать абсолютную дельту за последние 3 года, 1 год и 6 месяцев; посчитать ежемесячную скорость прироста за последние 3 года, 1 год и 6 месяцев
3. Сделать вывод: район не развивается/ район был застроен год назад и нет новой застройки/ район все еще активно застраивается
4. Нанести результаты на карту. Найти 3-ий тип районов
5. Подтвердить картинку с помощью Local Moran's I - найти наиболее позитивно выделяющиеся кластеры
Инсайты из решения:
1. Можно верить только дорогам )
Если вы думаете что в России мало OSM данных, то вы точно никогда не занимались Кувайтом. Согласно OSM в Кувайте только в 1/4 главного города есть здания (way/relations=building), остальные люди видимо живут в шатрах🤷♀️. Тоже самое для POIs.
Остаются только дороги: они обновляются по спутникам,и поэтому отражают реальность (иногда с небольшой задержкой)
2. API Ohsome- самый удобный способ загружать историю OSM из Python. Подходит, если размер территории не большой, Иначе проще работать с архивами датасетов.
Документация: тут
Мой пример скрипта на загрузку дорог: тут
3. В странах, где мало данных, длина сегментов дороги варьируется от 1 м до 36 км, когда обычно сегмент не превышает 1 км. Поэтому при сцепке с сеткой гексагонов надо помнить, что одна дорога пересекает несколько гексов
4. Для расчета дельты изменений суммарная длина дорог подошла лучше количества из-за неоднородности длины сегментов.
5. Такой анализ помогает найти города, застраиваемые с нуля, но не помогает выявить уплотняемые территории (сравнение со спутником).
6. Данные о перемещении людей не помогают в такой задаче, поскольку появляются с лагом во времени - когда квартал уже застроен.
GitHub
all_geodata_scripts/ohsome-historical-roads-example.ipynb at main · Ines2607/all_geodata_scripts
Contribute to Ines2607/all_geodata_scripts development by creating an account on GitHub.
Артём тут написал об особенностях работы в одной из ведущих мировых лабораторий городского анализа. Читаешь и понимаешь, почему они "ведущие".
Интересно, что я поймала похожие ощущения, работая с испанцам, вот только камеры мы не включаем- всё интроверты🤷♀
Интересно, что я поймала похожие ощущения, работая с испанцам, вот только камеры мы не включаем- всё интроверты🤷♀
Forwarded from Артем в ЮК (artemvuk)
Топ-5 отличий работы в британской урбан-компании от российской
Спустя почти год работы со Space Syntax могу обозначить основные моменты, по которым британский подход отличается от российского.
1. Все делают всё. Не знаю, зависит ли это от размера компании, но Space Syntax, например, на 90% состоит из специалистов. На 30 сотрудников приходится всего три менеджера: офис, операционный и финансовый директоры. Я сейчас на позиции Associate, т.е. отвечаю за все, что происходит с набором конкретных проектов, в которых я занят как Project Leader. Значит - веду бюджет и график проекта, модерирую переговоры с клиентом и подрядчиками, готовлю отчеты, руковожу джунами, вместе с директором проекта определяю направление разработки. У нас нет графических дизайнеров, аккаунтов и эйчаров. Все делаем своими руками. Не знаю, хорошо это или плохо, но иногда хочется скинуть часть работы на менеджеров, которых нет.
2. Рабочая этика. Британцы не опаздывают н и к о г д а, а если опаздывают больше чем на минуту - предупреждают заранее. Британцы всегда включают камеры в зумах, а если не включают - значит зум проходит во время ланча. В России я однажды наблюдал обратную ситуацию: одна из известных в среде градостроительниц во время проектного брифинга с включенной камерой готовила борщ, пробовала его из поварешки, нарезала мяско. Про опоздания руководителей, выключенные камеры, звонки за рулем молчу.
3. 9-5 mentality. За все время в Space Syntax я перерабатывал два раза: уходил из офиса не в 6, а в 7-7:30 вечера. Ни разу не работал на выходных. В России у меня получалось так жить, только если я сам был руководителем проекта. В остальных случаях бывала и работа по 24 часа подряд. Здесь nine-to-five - это просто норма. Правда, до Швеции нам еще далеко 🙂
4. Прозрачность. В Space Syntax каждый сотрудник - это employee owner. Это значит, что у всех есть доля собственности компании, которая возрастает по мере выслуги лет, а также право голоса в принятии стратегических решений. У каждого, начиная с джунов, есть доступ к любым документам по любому проекту или работе офиса, бюджетам, расходам, business growth plan etc. За кадром остаются только личные ревью на других сотрудников.
5. Attitude. Этот пункт я могу раскрыть в двух словах - спокойное достоинство. Почти все директора в РФ были суетологами, многие с синдромом самозванца. Здесь совершенно другой общий вайб у всех коллег, начиная с джунов и заканчивая главой компании. Сразу понимаешь, что любая задача решаема. Если в ступоре - можно договориться с клиентом и партнерами о продлении срока, чтобы повысить качество работ. Методы исследований отработаны дсятилетиями, это тоже добавляет уверенности. Вдобавок ко всему, все между собой на равных: недавно директор возбужденно презентовал мне свои идеи о том, как классифицировать улицы новым методом и жадно требовал мой фидбек. Наверное, можно сказать, что компания больше ориентирована на процесс и его качество, в результате которого наверняка будет хороший результат. Раньше у меня чаще был другой опыт: сначала придумать результат, а потом уже разбираться с процессом.
Это основные пункты о том, как устроена работа в Space Syntax. Позже напишу, в чем специфика проектов и их разработки.
Спустя почти год работы со Space Syntax могу обозначить основные моменты, по которым британский подход отличается от российского.
1. Все делают всё. Не знаю, зависит ли это от размера компании, но Space Syntax, например, на 90% состоит из специалистов. На 30 сотрудников приходится всего три менеджера: офис, операционный и финансовый директоры. Я сейчас на позиции Associate, т.е. отвечаю за все, что происходит с набором конкретных проектов, в которых я занят как Project Leader. Значит - веду бюджет и график проекта, модерирую переговоры с клиентом и подрядчиками, готовлю отчеты, руковожу джунами, вместе с директором проекта определяю направление разработки. У нас нет графических дизайнеров, аккаунтов и эйчаров. Все делаем своими руками. Не знаю, хорошо это или плохо, но иногда хочется скинуть часть работы на менеджеров, которых нет.
2. Рабочая этика. Британцы не опаздывают н и к о г д а, а если опаздывают больше чем на минуту - предупреждают заранее. Британцы всегда включают камеры в зумах, а если не включают - значит зум проходит во время ланча. В России я однажды наблюдал обратную ситуацию: одна из известных в среде градостроительниц во время проектного брифинга с включенной камерой готовила борщ, пробовала его из поварешки, нарезала мяско. Про опоздания руководителей, выключенные камеры, звонки за рулем молчу.
3. 9-5 mentality. За все время в Space Syntax я перерабатывал два раза: уходил из офиса не в 6, а в 7-7:30 вечера. Ни разу не работал на выходных. В России у меня получалось так жить, только если я сам был руководителем проекта. В остальных случаях бывала и работа по 24 часа подряд. Здесь nine-to-five - это просто норма. Правда, до Швеции нам еще далеко 🙂
4. Прозрачность. В Space Syntax каждый сотрудник - это employee owner. Это значит, что у всех есть доля собственности компании, которая возрастает по мере выслуги лет, а также право голоса в принятии стратегических решений. У каждого, начиная с джунов, есть доступ к любым документам по любому проекту или работе офиса, бюджетам, расходам, business growth plan etc. За кадром остаются только личные ревью на других сотрудников.
5. Attitude. Этот пункт я могу раскрыть в двух словах - спокойное достоинство. Почти все директора в РФ были суетологами, многие с синдромом самозванца. Здесь совершенно другой общий вайб у всех коллег, начиная с джунов и заканчивая главой компании. Сразу понимаешь, что любая задача решаема. Если в ступоре - можно договориться с клиентом и партнерами о продлении срока, чтобы повысить качество работ. Методы исследований отработаны дсятилетиями, это тоже добавляет уверенности. Вдобавок ко всему, все между собой на равных: недавно директор возбужденно презентовал мне свои идеи о том, как классифицировать улицы новым методом и жадно требовал мой фидбек. Наверное, можно сказать, что компания больше ориентирована на процесс и его качество, в результате которого наверняка будет хороший результат. Раньше у меня чаще был другой опыт: сначала придумать результат, а потом уже разбираться с процессом.
Это основные пункты о том, как устроена работа в Space Syntax. Позже напишу, в чем специфика проектов и их разработки.
{kind=link}
Хотя мой фокус в урбанистике - это применение математических подходов в городских исследованиях, я стараюсь читать о разных аспектах этой науки.
Один из моих источников информации - это канал Лены Пудовой. В своем канале автор рассказывает об актуальном и прикладном в российской урбанистике.
Мои любимые темы - то, что не найти в других каналах об урбанистике:
- анонсы конференций и последние события - среди них даже новая реклама девелоперов
- стримы и интервью с интересными персоналиями из мира урбанистики
Отдельный респект автору за качество подачи информации: идеи структурированы, текст легко читается. Например, для того, чтобы помочь читателю найти работу автор написала алгоритм, которому легко следовать👌
Кстати, если вдруг вы надумали искать работу, Лена собрала список из 80 арх бюро, работающих в урбанистике: смотреть тут
Еще периодически автор собирает тусовки урбанистов, так что следите за анонсами😉
Один из моих источников информации - это канал Лены Пудовой. В своем канале автор рассказывает об актуальном и прикладном в российской урбанистике.
Мои любимые темы - то, что не найти в других каналах об урбанистике:
- анонсы конференций и последние события - среди них даже новая реклама девелоперов
- стримы и интервью с интересными персоналиями из мира урбанистики
Отдельный респект автору за качество подачи информации: идеи структурированы, текст легко читается. Например, для того, чтобы помочь читателю найти работу автор написала алгоритм, которому легко следовать👌
Кстати, если вдруг вы надумали искать работу, Лена собрала список из 80 арх бюро, работающих в урбанистике: смотреть тут
Еще периодически автор собирает тусовки урбанистов, так что следите за анонсами😉
Сегодня первый из постов по мотивам финальных проектов в рамках курса по геоаналитике.
В рамках курса у слушателей была возможность применить полученные знания для решения интересующих их городских проблем, и часть воспользовалась такой возможностью, сделав за короткий срок содержательные и качественные проекты.
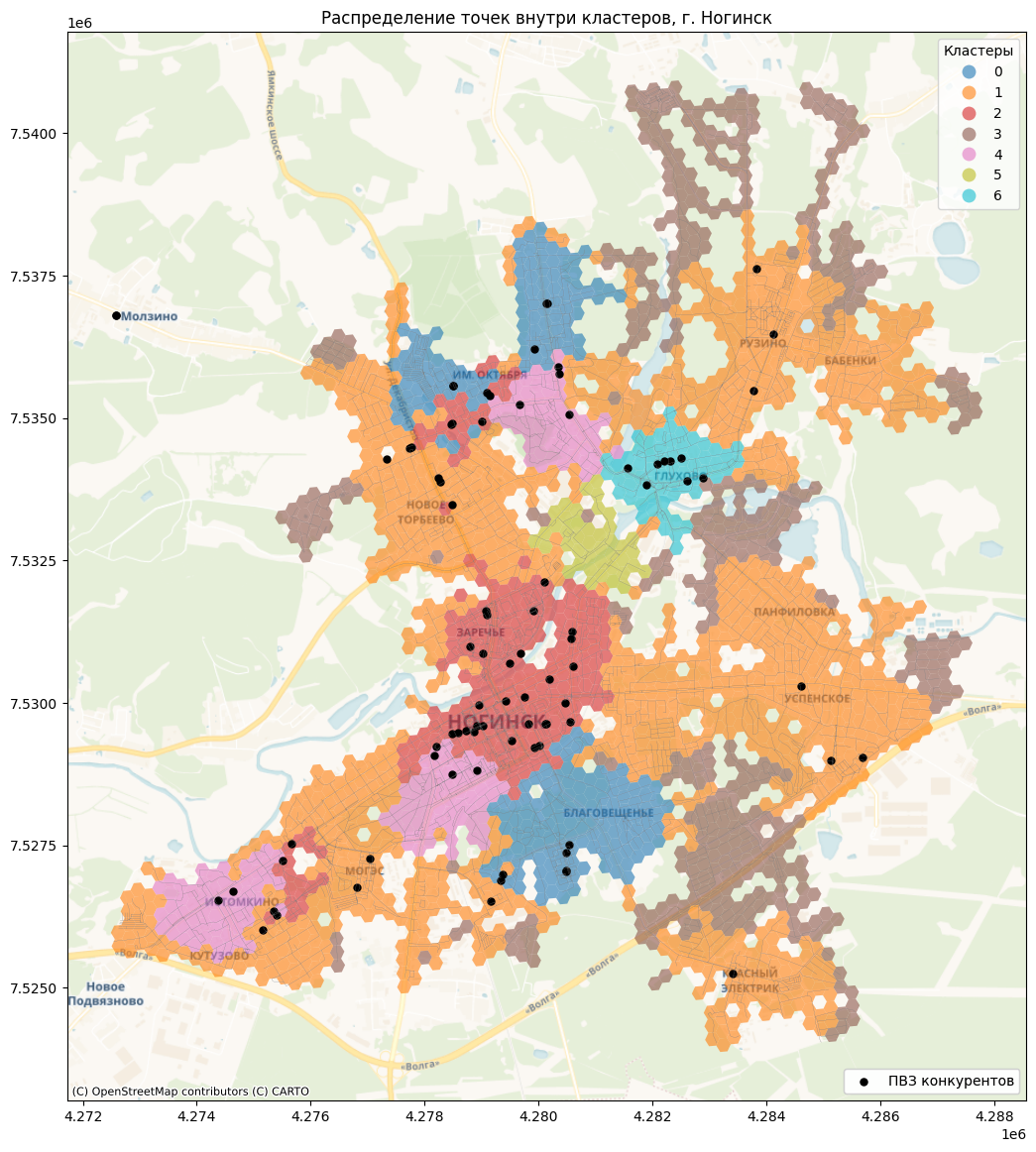
Автор сегодняшнего проекта @yulia_kor решала задачу развития сети в новом для бизнеса городе, в условиях, когда единственное доступное знание о конкурентах - это их локации.
#geoanalytics #geocourse #geopython
В рамках курса у слушателей была возможность применить полученные знания для решения интересующих их городских проблем, и часть воспользовалась такой возможностью, сделав за короткий срок содержательные и качественные проекты.
Автор сегодняшнего проекта @yulia_kor решала задачу развития сети в новом для бизнеса городе, в условиях, когда единственное доступное знание о конкурентах - это их локации.
#geoanalytics #geocourse #geopython
Дано:
Бизнес хочет расширить свою логистическую сеть объектов и начать развивать формат ПВЗ — пункты выдачи заказов. У бизнеса еще нет открытых ПВЗ и, следовательно, нет операционной статистики по таким объектам.
Задача:
Необходимо найти оптимальные места для размещения ПВЗ в городе N
Гипотеза:
Предположим, что конкуренты, как рациональные агенты, выбирают оптимальные места для размещения своих объектов. Исходя из этого предположения можно найти места в городе, которые похожи хотя бы на одно из мест, где расположены ПВЗ конкурентов.
Ограничение:
Решение можно использовать, если считать допущение выше верным. Но в обычной жизни другие агенты рынка не всегда размещают ПВЗ оптимально.
Когда применимо?
Когда нужно верхнеуровнево определить поисковые зоны для размещения объектов. После определения зоны можно исследовать рынок объявлений об аренде и искать подходящие помещения.
Данные:
1. данные о существующих ПВЗ конкурентов с сайта wildberries и ozon.
2. население (реформа ЖКХ, расчетная численность жителей в ИЖС, исходя из среднего размера д/х)
3. объекты инфраструктуры (OSM)
4. дорожный граф и OSM
Получившееся решение:
Комментарий: из-за неоднородности пространства сначала необходимо кластеризовать территорию, а затем искать похожие места внутри каждого из кластеров.
1. Создать гексогональную сетку.
2. Отфильтровать сетку так, чтобы остались только гексы, где есть дома и дороги
3. Построить 10-мин изохроны на основе центройдов гексогональной сетки
4. Рассчитать метрики центральности на основе графа УДС
5. Агрегировать данные инфраструктуры и населения по изохроне
6. Стандартизировать данные
Уменьшить размерность данных, используя PCA
7. Провести кластерный анализ методом k-средних
8. Посчитать количество ПВЗ в каждом кластере. Исключить из анализа кластеры, где нет ПВЗ.
9. В каждом из кластеров выделить гексы, где еще нет ПВЗ. Посчитать их степень схожести на основе косинусного расстояния с гексами, где расположены ПВЗ.
10. Отобрать с помощью фильтра локации с косинусным расстоянием больше 0,95.
Выводы по использованным методам:
1. Агрегация по гексам может быть слишком усредненной — дом на углу перекрестка и в глубине района может иметь одинаковый вес. Чтобы сделать инструмент более точным, можно попробовать агрегировать параметры по домам вместо гексагонов (побочный эффект: длительность расчетов увеличится в разы)
2. Даже без привязки к поиску потенциальных мест размещения ПВЗ, инструмент дает понимание, где находится центральная часть города, что может пригодится для ряда других задач.
3. Если у города достаточно однородная пространственная структура (например, равномерно распределено население, инфраструктура), то в результате применения инструмента для размещения ПВЗ может подойти большая часть города. В этом случае эффективность инструмента будет крайне низкая
4. Одной из гипотез было, что локации ПВЗ значимо зависят от пешеходного потока. Однако из-за недоступности данных, были рассчитаны метрики центральности (можно также попробовать использовать метрики Space Syntax). На этих мет гипотеза подтвердилась - чем больше плотность УДС, betweenness centrality, тем больше ПВЗ можно наблюдать в локации.
Бизнес хочет расширить свою логистическую сеть объектов и начать развивать формат ПВЗ — пункты выдачи заказов. У бизнеса еще нет открытых ПВЗ и, следовательно, нет операционной статистики по таким объектам.
Задача:
Необходимо найти оптимальные места для размещения ПВЗ в городе N
Гипотеза:
Предположим, что конкуренты, как рациональные агенты, выбирают оптимальные места для размещения своих объектов. Исходя из этого предположения можно найти места в городе, которые похожи хотя бы на одно из мест, где расположены ПВЗ конкурентов.
Ограничение:
Решение можно использовать, если считать допущение выше верным. Но в обычной жизни другие агенты рынка не всегда размещают ПВЗ оптимально.
Когда применимо?
Когда нужно верхнеуровнево определить поисковые зоны для размещения объектов. После определения зоны можно исследовать рынок объявлений об аренде и искать подходящие помещения.
Данные:
1. данные о существующих ПВЗ конкурентов с сайта wildberries и ozon.
2. население (реформа ЖКХ, расчетная численность жителей в ИЖС, исходя из среднего размера д/х)
3. объекты инфраструктуры (OSM)
4. дорожный граф и OSM
Получившееся решение:
Комментарий: из-за неоднородности пространства сначала необходимо кластеризовать территорию, а затем искать похожие места внутри каждого из кластеров.
1. Создать гексогональную сетку.
2. Отфильтровать сетку так, чтобы остались только гексы, где есть дома и дороги
3. Построить 10-мин изохроны на основе центройдов гексогональной сетки
4. Рассчитать метрики центральности на основе графа УДС
5. Агрегировать данные инфраструктуры и населения по изохроне
6. Стандартизировать данные
Уменьшить размерность данных, используя PCA
7. Провести кластерный анализ методом k-средних
8. Посчитать количество ПВЗ в каждом кластере. Исключить из анализа кластеры, где нет ПВЗ.
9. В каждом из кластеров выделить гексы, где еще нет ПВЗ. Посчитать их степень схожести на основе косинусного расстояния с гексами, где расположены ПВЗ.
10. Отобрать с помощью фильтра локации с косинусным расстоянием больше 0,95.
Выводы по использованным методам:
1. Агрегация по гексам может быть слишком усредненной — дом на углу перекрестка и в глубине района может иметь одинаковый вес. Чтобы сделать инструмент более точным, можно попробовать агрегировать параметры по домам вместо гексагонов (побочный эффект: длительность расчетов увеличится в разы)
2. Даже без привязки к поиску потенциальных мест размещения ПВЗ, инструмент дает понимание, где находится центральная часть города, что может пригодится для ряда других задач.
3. Если у города достаточно однородная пространственная структура (например, равномерно распределено население, инфраструктура), то в результате применения инструмента для размещения ПВЗ может подойти большая часть города. В этом случае эффективность инструмента будет крайне низкая
4. Одной из гипотез было, что локации ПВЗ значимо зависят от пешеходного потока. Однако из-за недоступности данных, были рассчитаны метрики центральности (можно также попробовать использовать метрики Space Syntax). На этих мет гипотеза подтвердилась - чем больше плотность УДС, betweenness centrality, тем больше ПВЗ можно наблюдать в локации.
{kind=link}
Сегодня 2-ой пост по мотивам финальных проектов в рамках курса по геоаналитике.
Автор проекта @HelenSkrebkova изучала пространственное развитие Дубая с помощью анализа цен на рынке недвижимости. Получилось интересно, а если вы вдруг в Дубае и думаете, в каком районе выгодно снять квартиру, то может быть и еще и полезно.
Читать тут
Автор проекта @HelenSkrebkova изучала пространственное развитие Дубая с помощью анализа цен на рынке недвижимости. Получилось интересно, а если вы вдруг в Дубае и думаете, в каком районе выгодно снять квартиру, то может быть и еще и полезно.
Читать тут
Telegraph
ДУБАЙ: ВЫЯВЛЕНИЕ ПЕРСПЕКТИВНЫХ ДЛЯ ДЕВЕЛОПМЕНТА РАЙОНОВ
0 :: КОНТЕКСТ Экономика Дубая активно развивается и сфокусирована на таких отраслях, как туризм, торговля и операции с недвижимостью. Минувший 2022 год стал абсолютно рекордным по числу совершенных сделок с жилой недвижимостью, по данным Земельного департамента…
Forwarded from Канал Алексея Радченко
В сервисе DataLens от Яндекса есть возможность посмотреть и выгрузить данные по ДТП, которые отметили сами пользователи сервиса (не данные от ГИБДД). Работает немного криво (иногда пропадает кнопка выгрузки и нет фильтра на прошлые периоды, хотя данные есть), но все равно отличные данные для курсового проекта или небольшого исследования вашего района - напишите если будете что-то делать, посмотрим вместе.
P.S. Все жду когда скачать данные можно будет и на московском Продвижении.
P.S. Все жду когда скачать данные можно будет и на московском Продвижении.
Тут ребята из 2ГИС выпустили новый пост о работе дизайнеров карт. Если в первом они рассказали про работу «в полях», то в этом — больше про роль дизайнера при создании карты, чей вклад, как пользователи, мы скорее всего редко замечаем.
Когда ты пользователь, ты не задумываешься о сложном выборе дизайнера "между лавочкой и Большим театром", но когда тебя, как аналитика просят разместить на карте результаты работы для заказчика, то начинаешь понимать всю сложность процесса: что главное для клиента, как передать разницу с помощью цветов и форм, как сделать карту понятной для человека без опыта в географии или аналитики.
Вобщем респект ребятам за хорошую работу
Когда ты пользователь, ты не задумываешься о сложном выборе дизайнера "между лавочкой и Большим театром", но когда тебя, как аналитика просят разместить на карте результаты работы для заказчика, то начинаешь понимать всю сложность процесса: что главное для клиента, как передать разницу с помощью цветов и форм, как сделать карту понятной для человека без опыта в географии или аналитики.
Вобщем респект ребятам за хорошую работу
Сегодня 3-ий пост по мотивам финальных проектов в рамках курса по геоаналитике.
Автор проекта @DrozdovLev исследовал, что влияет на решение людей добираться на работу на общественном транспорте. Результаты проекта планируется использовать для разработки стратегии по его улучшению и популяризации, в сотрудничестве с муниципалитетами и крупными компаниями.
Презентацию с красивыми картинками смотреть тут, описание проекта в посте ниже👇👇
Автор проекта @DrozdovLev исследовал, что влияет на решение людей добираться на работу на общественном транспорте. Результаты проекта планируется использовать для разработки стратегии по его улучшению и популяризации, в сотрудничестве с муниципалитетами и крупными компаниями.
Презентацию с красивыми картинками смотреть тут, описание проекта в посте ниже👇👇
Google Docs
Использование общественного транспорта для поездок на работу. Предсказательная модель на основе опроса и дополнительных геоданных
Использование общественного транспорта для поездок на работу. Предсказательная модель на основе опроса и дополнительных геоданных финальный проект курса "Пространственный анализ и моделирование в Python" Лев Дроздов [email protected]
Цель проекта: найти значимые факторы, влияющие на выбор общественного транспорта для поездок на работу, для разработки стратегии по его улучшению и популяризации.
Забегая вперед, скажу, что в целом подтвердилась важность доступности ж/д станции и гибкого графика работы в офисе - есть что порекомендовать муниципалитетам и крупным фирмам, чтобы улучшить опыт пользователей общественного транспорта и предоставить им большую транспортную гибкость. Через муниципалитеты - инфраструктурно или оптимизацией маршрутов, через частные компании - организацией шаттлов до станции.
Гипотеза: выбор транспорта зависит не только от личных данных работника, но также от географических и транспортных/городских данных.
Данные: проект основан на опросе ~800 работников бизнес-парков в Израиле, проведенном НКО "15 minutes", а также на дополнительных геоданных из открытых источников (список в презентации).
Методы:
1. XGBClassifier - для прогноза выбора вида транспорта работником. Для простоты оставил два варианта: на личном авто и на общественном транспорте.
2. Lasso (регрессия) - для того же самого. Точность получилась сопоставимая, хотя использовал его не по прямому назначению. У Lasso на выходе получается диапазон, я же категоризировал с помощью порогового значения. Альтернативный вариант - использовать Logistic Regression, в ней выбор порога встроен по умолчанию.
3. Global & Local Moran - для расчета пространственной корреляции остатков модели Lasso: в каких локациях модель ошибалась в классификации и в какую сторону.
Выводы:
• Global Moran для всей выборки получился совсем низкий, только для Тель Авива чуть больше - 0.17: корреляция низкая, ожидаемо выделяется южная часть города.
• Точность модели XGBoost (accuracy) - 0.75
• Сильнейшие предикторы выбора транспорта:
1. Расстояние до работы / время в пути - из-за дальних поездок по ж/д большее расстояние значит больше вероятность О.Т.
2. Часы работы - чем раньше начинается рабочий день, тем выше вероятность использования авто. Возможно из-за утренних пробок работники с машиной предпочитают начать рабочий день пораньше (утренние “часы пик” плотнее). Или же автомобиль удобнее из-за ранних часов начала работы.
3. Возраст работника - чем меньше, тем вероятнее О.Т.
4. Количество дней работы в офисе - чем меньше, тем вероятнее О.Т.
5. Среда вокруг дома на основе walk score index (он выше, если сетка дорог плотнее и больше POIs доступно). Высокий индекс - вероятнее использование О.Т
Пока не оправдавшие ожидания признаки (с 6-ти опрошенных территорий):
• транспортная доступность
• количество рейсов автобусов
• процент пользователей О.Т.
• плотность расположения остановок
• количество работников на км³
Эти признаки, к сожалению, только ухудшают модель, хотя так моделью мог бы учитываться “последний километр” до работы. “Первый километр”, со стороны дома, модель учитывает через walk score. Нужна выборка по разным территориям для большей точности модели.
Компонент пространства позволяет выявить территории с отклонениями в прогнозе. Вероятно, добавление какого-то характерного признака таких мест в модель улучшит результат. Может быть там какая-то повышенная плотность остановок или наоборот - больше парковок, чем в соседних районах.
Отмечу, что в Lasso в отличие от XGboostClassifier “количество дней в офисе” не стало значительным предиктором - какой-то другой параметр “объяснил” все за него - полагаю “расстояние”. По остальным признакам модели солидарны.
На будущее:
• хочется попробовать модель на большем количестве бизнес территорий
• выделить пользователей поезда в отдельную категорию - они едут издалека и могут продуктивно использовать это время
• заменить Lasso на Logistic Regression
Забегая вперед, скажу, что в целом подтвердилась важность доступности ж/д станции и гибкого графика работы в офисе - есть что порекомендовать муниципалитетам и крупным фирмам, чтобы улучшить опыт пользователей общественного транспорта и предоставить им большую транспортную гибкость. Через муниципалитеты - инфраструктурно или оптимизацией маршрутов, через частные компании - организацией шаттлов до станции.
Гипотеза: выбор транспорта зависит не только от личных данных работника, но также от географических и транспортных/городских данных.
Данные: проект основан на опросе ~800 работников бизнес-парков в Израиле, проведенном НКО "15 minutes", а также на дополнительных геоданных из открытых источников (список в презентации).
Методы:
1. XGBClassifier - для прогноза выбора вида транспорта работником. Для простоты оставил два варианта: на личном авто и на общественном транспорте.
2. Lasso (регрессия) - для того же самого. Точность получилась сопоставимая, хотя использовал его не по прямому назначению. У Lasso на выходе получается диапазон, я же категоризировал с помощью порогового значения. Альтернативный вариант - использовать Logistic Regression, в ней выбор порога встроен по умолчанию.
3. Global & Local Moran - для расчета пространственной корреляции остатков модели Lasso: в каких локациях модель ошибалась в классификации и в какую сторону.
Выводы:
• Global Moran для всей выборки получился совсем низкий, только для Тель Авива чуть больше - 0.17: корреляция низкая, ожидаемо выделяется южная часть города.
• Точность модели XGBoost (accuracy) - 0.75
• Сильнейшие предикторы выбора транспорта:
1. Расстояние до работы / время в пути - из-за дальних поездок по ж/д большее расстояние значит больше вероятность О.Т.
2. Часы работы - чем раньше начинается рабочий день, тем выше вероятность использования авто. Возможно из-за утренних пробок работники с машиной предпочитают начать рабочий день пораньше (утренние “часы пик” плотнее). Или же автомобиль удобнее из-за ранних часов начала работы.
3. Возраст работника - чем меньше, тем вероятнее О.Т.
4. Количество дней работы в офисе - чем меньше, тем вероятнее О.Т.
5. Среда вокруг дома на основе walk score index (он выше, если сетка дорог плотнее и больше POIs доступно). Высокий индекс - вероятнее использование О.Т
Пока не оправдавшие ожидания признаки (с 6-ти опрошенных территорий):
• транспортная доступность
• количество рейсов автобусов
• процент пользователей О.Т.
• плотность расположения остановок
• количество работников на км³
Эти признаки, к сожалению, только ухудшают модель, хотя так моделью мог бы учитываться “последний километр” до работы. “Первый километр”, со стороны дома, модель учитывает через walk score. Нужна выборка по разным территориям для большей точности модели.
Компонент пространства позволяет выявить территории с отклонениями в прогнозе. Вероятно, добавление какого-то характерного признака таких мест в модель улучшит результат. Может быть там какая-то повышенная плотность остановок или наоборот - больше парковок, чем в соседних районах.
Отмечу, что в Lasso в отличие от XGboostClassifier “количество дней в офисе” не стало значительным предиктором - какой-то другой параметр “объяснил” все за него - полагаю “расстояние”. По остальным признакам модели солидарны.
На будущее:
• хочется попробовать модель на большем количестве бизнес территорий
• выделить пользователей поезда в отдельную категорию - они едут издалека и могут продуктивно использовать это время
• заменить Lasso на Logistic Regression
Wikipedia
Moran's I
In statistics, Moran's I is a measure of spatial autocorrelation developed by Patrick Alfred Pierce Moran. Spatial autocorrelation is characterized by a correlation in a signal among nearby locations in space. Spatial autocorrelation is more complex than…
📈Тут у классных ребят появилась вакансия гис-аналитика 😍
В отделе продуктов и исследований лаборатории пространственных данных при МИИГАиК открылась вакансия гис-аналитика. Они делают стартап в сфере PropTech и сейчас расширяют команду. В команде уже работают студенты прошлых потоков моего курса)
Что нужно делать
- Собирать, обрабатывать и анализировать геоданные
- Писать новые и оптимизировать существующие пайплайны получения и обработки геоданных
- Поддерживать и развивать базу геоданных
- Автоматизировать и оптимизировать рабочие процессы, разрабатывать новые инструментов для анализа данных (Python)
- Выполнять запросы от смежных команд
Навыки
- Уверенное владение QGIS
- Владение Python (numpy, pandas, geopandas, shapely, osmnx/networkx, requests)
- Умение работать с базами данных (PostgreSQL)
- Базовые знания математики и статистики
- Знание основ HTML
- Понимание принципов работы DS и ML
- Базовая визуализация пространственных данных
- Умение видеть за числами и картами физический смысл и способность находить причины явлений
Условия
- Официальное трудоустройство по ТК РФ
- Уютный офис в центре Москвы (м. Курская)
- Сильная и классная команда, с которой можно быстро расти
- Гибридный график работы
- Интересные и нестандартные задачи
- Отсутствие дресс-кода
Пишите в лс @dorozhnij
В отделе продуктов и исследований лаборатории пространственных данных при МИИГАиК открылась вакансия гис-аналитика. Они делают стартап в сфере PropTech и сейчас расширяют команду. В команде уже работают студенты прошлых потоков моего курса)
Что нужно делать
- Собирать, обрабатывать и анализировать геоданные
- Писать новые и оптимизировать существующие пайплайны получения и обработки геоданных
- Поддерживать и развивать базу геоданных
- Автоматизировать и оптимизировать рабочие процессы, разрабатывать новые инструментов для анализа данных (Python)
- Выполнять запросы от смежных команд
Навыки
- Уверенное владение QGIS
- Владение Python (numpy, pandas, geopandas, shapely, osmnx/networkx, requests)
- Умение работать с базами данных (PostgreSQL)
- Базовые знания математики и статистики
- Знание основ HTML
- Понимание принципов работы DS и ML
- Базовая визуализация пространственных данных
- Умение видеть за числами и картами физический смысл и способность находить причины явлений
Условия
- Официальное трудоустройство по ТК РФ
- Уютный офис в центре Москвы (м. Курская)
- Сильная и классная команда, с которой можно быстро расти
- Гибридный график работы
- Интересные и нестандартные задачи
- Отсутствие дресс-кода
Пишите в лс @dorozhnij
У меня новости😊.
Полгода пролетели, и я открываю регистрацию на 3-ий поток онлайн-курса по пространственному анализу и моделированию в Python.
Второй запуск еще раз подтвердил актуальность материалов курса для специалистов с (неожиданно!) очень разным бекгруандом, а некоторым даже помог найти работу. По запросу участников курса мы решали задачи от прогноза лесных пожаров и рынка недвижимости в Дубае до размещения остановок каршеринга и складов доставки. Честно признаюсь,мне очень понравилось это разнообразие, так что я в предвкушении, какие еще кейсы мы сможем вместе решить с новыми участниками😁.
Важное
Темы, особенности курса, отзывы, тарифы: на сайте
Старт курса: 14 сентября 2023
Есть обязательный вступительный тест - ссылки на сайте.
Доступ получают первые, кто прошли тест и внесли предоплату.
Зачем тест
Знание python и основ мат статистики важно для вашего комфортного обучения и понимания тем. Курс интенсивный - времени на погружение в базу у вас не останется.
Что после теста
После теста вы получите или письмо с положительным решением и ссылкой на чат курса или письмо с дополнительными материалами и шансом подтянуть знания и попробовать ещё раз!)
До встречи на курсе😊
P.S. В чате канала есть ребята с первого и второго потока - маякните там, если у вас есть к ним вопросы - подскажут:)
Полгода пролетели, и я открываю регистрацию на 3-ий поток онлайн-курса по пространственному анализу и моделированию в Python.
Второй запуск еще раз подтвердил актуальность материалов курса для специалистов с (неожиданно!) очень разным бекгруандом, а некоторым даже помог найти работу. По запросу участников курса мы решали задачи от прогноза лесных пожаров и рынка недвижимости в Дубае до размещения остановок каршеринга и складов доставки. Честно признаюсь,мне очень понравилось это разнообразие, так что я в предвкушении, какие еще кейсы мы сможем вместе решить с новыми участниками😁.
Важное
Темы, особенности курса, отзывы, тарифы: на сайте
Старт курса: 14 сентября 2023
Есть обязательный вступительный тест - ссылки на сайте.
Доступ получают первые, кто прошли тест и внесли предоплату.
Зачем тест
Знание python и основ мат статистики важно для вашего комфортного обучения и понимания тем. Курс интенсивный - времени на погружение в базу у вас не останется.
Что после теста
После теста вы получите или письмо с положительным решением и ссылкой на чат курса или письмо с дополнительными материалами и шансом подтянуть знания и попробовать ещё раз!)
До встречи на курсе😊
P.S. В чате канала есть ребята с первого и второго потока - маякните там, если у вас есть к ним вопросы - подскажут:)
geopython.tilda.ws
Онлайн-курсы Пространственный анализ и моделирование на Python
Итак, 3-ий поток почти набран - ну и скорость у вас😃💪👌
Осталось несколько мест на "Необходимую базу" и пара дней, чтобы решиться:)
Если вы хотели погрузиться в геоанализ, советую не откладывать, потому как если и будет 4 поток, то не раньше следующего июня- PhD само себя не напишет))
Осталось несколько мест на "Необходимую базу" и пара дней, чтобы решиться:)
Если вы хотели погрузиться в геоанализ, советую не откладывать, потому как если и будет 4 поток, то не раньше следующего июня- PhD само себя не напишет))
Forwarded from Канал Алексея Радченко
Меня тут зацепил пост Ивана Бегтина про то, какие данные собирают производители автомобилей (советую читать статью, а не пост, она более взвешенная). Общий смысл, что данных собирается очень много, включая данные про про все перемещения и даже сексуальную жизнь. И хотя сначала я был разочарован что вся аналитика там строиться лишь по пользовательским соглашениям, мне стало любопытно что в пользовательских соглашениях в России, причем именно в сфере общественного транспорта. Вот что получилось:
1. Московский транспорт - ссылка на лицензионное соглашение ведет на https://api.mosgorpass.ru/license_agreement - у меня не открылось. Посмотреть не смог.
2. Помощник Москвы - тоже не открылось. Ведет на https://pakpm.mos.ru/api/help/privacy_policy.
3. Метро Москвы - Ссылка ведет на https://www.mosmetro.ru/app/oferta/new_oferta.pdf. Сайт выдает ошибку 404.
4. Моя Тройка - приложение Сбера по управлению картой тройка. Пишет что данных не собирается совсем - но описания снова нет - ошибка 404.
5. Приложение ЦППК (официальное?) - тут документ есть, но датирован аж 2018 годом и ведется от лица неизвестной компании Айтифорс, сайт которой уже не работает. Из еще более странного - это соглашение об обработке пользовательских данных, которое лежит в самом приложении - это явно внутренний документ описывающий взаимоотношения работодателя и его сотрудников, но никак не пользователей приложения.
6. Транспорт Подмосковья - соглашение с ООО ДатаПакс есть, но довольно формальное. Передача третьим лицам есть.
7. Яндекс Такси - самое подробное и детальное соглашение, нормально описывающее что именно будет собрано, с уточнением юрисдикций.
8. Социальное такси - тоже от московского дептранса. Тут соглашение есть, но максимально формальное и обезличенное. Документ в гуглдоке не имеет даже имени компании или адреса от лица кого это соглашение.
9. Транспорт Перми - приложения о персданных нет, ссылка на сайт разработчика.
10. Парковки Краснодара - ссылка битая - документа нет. Как впрочем и у 99% других приложений из регионов.
Вывод по общественному транспорту в итоге еще страшнее, чем с автомобилями. В случае тех, приложений, что вам предлагаю государственные органы власти и аффилированные компании вы даже не сможете узнать что и как делают с вашими персональными данными. Чем дальше от государства тем лучше и честнее представлена информация и тем прозрачнее политика работы с персональными данными.
1. Московский транспорт - ссылка на лицензионное соглашение ведет на https://api.mosgorpass.ru/license_agreement - у меня не открылось. Посмотреть не смог.
2. Помощник Москвы - тоже не открылось. Ведет на https://pakpm.mos.ru/api/help/privacy_policy.
3. Метро Москвы - Ссылка ведет на https://www.mosmetro.ru/app/oferta/new_oferta.pdf. Сайт выдает ошибку 404.
4. Моя Тройка - приложение Сбера по управлению картой тройка. Пишет что данных не собирается совсем - но описания снова нет - ошибка 404.
5. Приложение ЦППК (официальное?) - тут документ есть, но датирован аж 2018 годом и ведется от лица неизвестной компании Айтифорс, сайт которой уже не работает. Из еще более странного - это соглашение об обработке пользовательских данных, которое лежит в самом приложении - это явно внутренний документ описывающий взаимоотношения работодателя и его сотрудников, но никак не пользователей приложения.
6. Транспорт Подмосковья - соглашение с ООО ДатаПакс есть, но довольно формальное. Передача третьим лицам есть.
7. Яндекс Такси - самое подробное и детальное соглашение, нормально описывающее что именно будет собрано, с уточнением юрисдикций.
8. Социальное такси - тоже от московского дептранса. Тут соглашение есть, но максимально формальное и обезличенное. Документ в гуглдоке не имеет даже имени компании или адреса от лица кого это соглашение.
9. Транспорт Перми - приложения о персданных нет, ссылка на сайт разработчика.
10. Парковки Краснодара - ссылка битая - документа нет. Как впрочем и у 99% других приложений из регионов.
Вывод по общественному транспорту в итоге еще страшнее, чем с автомобилями. В случае тех, приложений, что вам предлагаю государственные органы власти и аффилированные компании вы даже не сможете узнать что и как делают с вашими персональными данными. Чем дальше от государства тем лучше и честнее представлена информация и тем прозрачнее политика работы с персональными данными.
Telegram
Ivan Begtin
Команда Mozilla опубликовала очередное интересное исследование по приватности, на сей раз приватности при использовании автомобилей 25 брендов и о том как вендоры собирают информацию [1] из которого можно узнать что:
- все без исключения вендоры собирают…
- все без исключения вендоры собирают…
Делюсь с вами подборкой источников геоданных, великодушно собранной для вас @Denis_Murataev.
Этими источниками Денис с коллегами регулярно пользуются в Институте Генплана, так что тут только проверенное. Если вы делаете исследования по России, возможно, в этом списке вы найдете ссылки на недостающие источники информации.
Краткое описание от автора
Что есть?
социально-демографические данные и геоданные, покрывающие всю территорию РФ.
Зачем?
Большинство данных используются как прокси на имеющиеся закрытые данные, для их верификации и при отсутствии официальных данных пропорциональной замены данных при анализе территории.
Все ли источники содержат готовые датасеты?
Нет, для некоторых источников данных необходимо написать парсеры.
Как пользоваться данными?
Все данные хранятся в базе и при исследовании территории агрегируются в минимальную территориальную единицу и ее “зону влияния” (throughput radius, KNN)
Этими источниками Денис с коллегами регулярно пользуются в Институте Генплана, так что тут только проверенное. Если вы делаете исследования по России, возможно, в этом списке вы найдете ссылки на недостающие источники информации.
Краткое описание от автора
Что есть?
социально-демографические данные и геоданные, покрывающие всю территорию РФ.
Зачем?
Большинство данных используются как прокси на имеющиеся закрытые данные, для их верификации и при отсутствии официальных данных пропорциональной замены данных при анализе территории.
Все ли источники содержат готовые датасеты?
Нет, для некоторых источников данных необходимо написать парсеры.
Как пользоваться данными?
Все данные хранятся в базе и при исследовании территории агрегируются в минимальную территориальную единицу и ее “зону влияния” (throughput radius, KNN)
glamorous-ambert-bd8 on Notion
Открытые данные | Notion
ДТП
А вот новость от одного из подписчиков про мероприятие по теме канала:
"Коллеги проводят вебинар 21 сентября в 15:00
"Маркетинг и аналитика на основе геоданных" Подробности по ссылке: https://webinar.platforma.id/
"Коллеги проводят вебинар 21 сентября в 15:00
"Маркетинг и аналитика на основе геоданных" Подробности по ссылке: https://webinar.platforma.id/
webinar.platforma.id
Маркетинг и аналитика на основе геоданных
Научитесь открывать, анализировать и расширять свой бизнес, основываясь на объективных данных