
HuggingFace Trainer: gradient accumulation was bugged
Отличный пример того, что всегда надо быть аккуратными при использовании фреймворков.
Недавно [обнаружили](https://unsloth.ai/blog/gradient), что в HuggingFace Trainer некорректно работал gradient accumulation. Было замечено, что при измерении размера батча лосс менялся, хотя, в теории, при использовании gradient accumulation, такого быть не должно.
"for gradient accumulation across token-level tasks like causal LM training, the correct loss should be computed by the total loss across all batches in a gradient accumulation step divided by the total number of all non padding tokens in those batches. This is not the same as the average of the per-batch loss values"
Баг быстро [пофиксили](https://huggingface.co/blog/gradient_accumulation) и заодно использовали эту ситуацию как повод дать новый функционал - упростить использование кастомных лоссов в Trainer.
#datascience
Отличный пример того, что всегда надо быть аккуратными при использовании фреймворков.
Недавно [обнаружили](https://unsloth.ai/blog/gradient), что в HuggingFace Trainer некорректно работал gradient accumulation. Было замечено, что при измерении размера батча лосс менялся, хотя, в теории, при использовании gradient accumulation, такого быть не должно.
"for gradient accumulation across token-level tasks like causal LM training, the correct loss should be computed by the total loss across all batches in a gradient accumulation step divided by the total number of all non padding tokens in those batches. This is not the same as the average of the per-batch loss values"
Баг быстро [пофиксили](https://huggingface.co/blog/gradient_accumulation) и заодно использовали эту ситуацию как повод дать новый функционал - упростить использование кастомных лоссов в Trainer.
#datascience
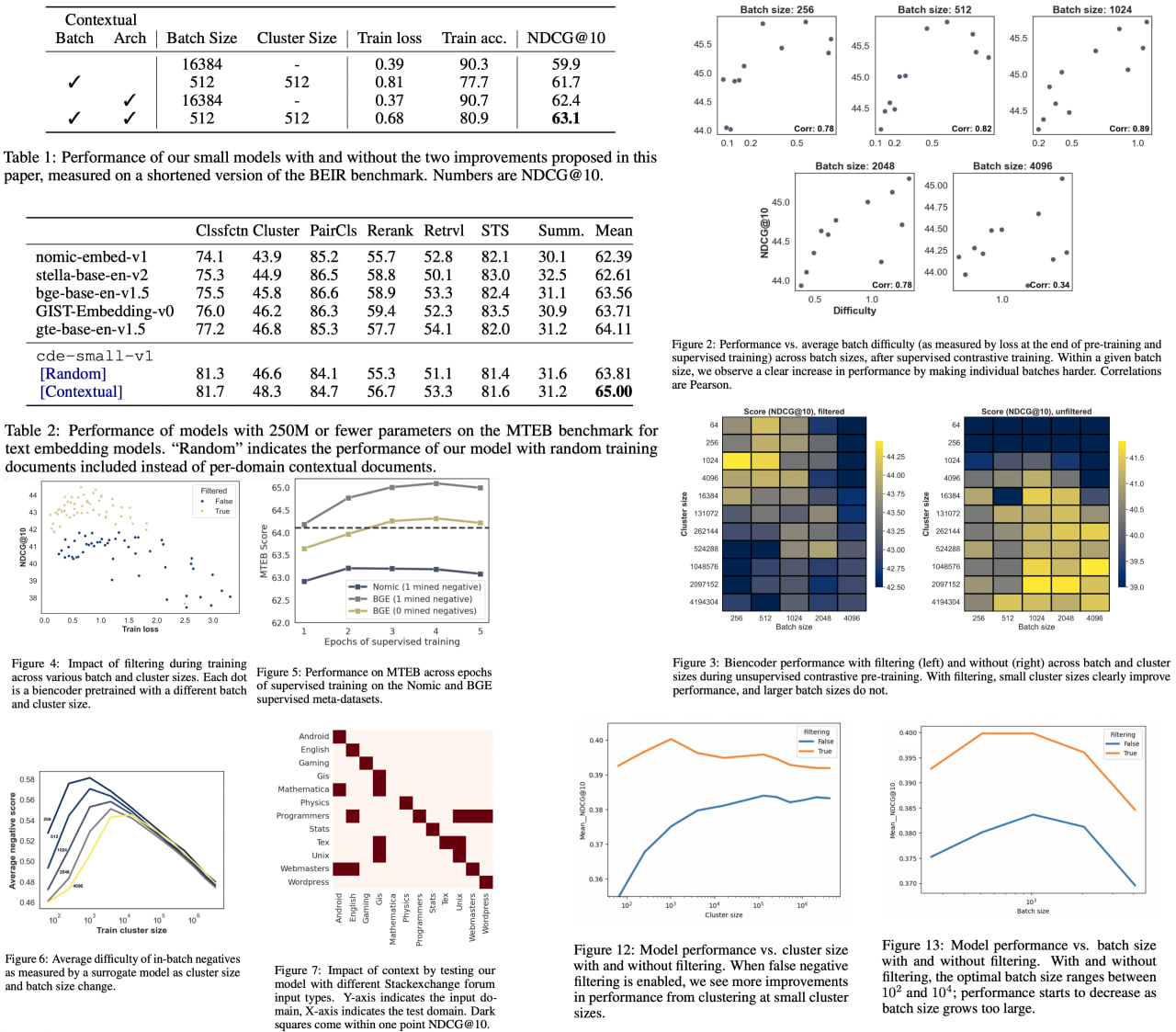
Contextual Document Embeddings
Статья с новым подходом для тренировки эмбеддингов - использование контекста для получения эмбеддингов документов. Предлагают два улучшения: contrastive learning включающий соседние документы в лосс внутри батча; новая архитектура, которая явно использует информацию соседних документов. Эти подходы улучшают результаты по сравнению с другими biencoders, особенно в условиях out-of-domain. Авторы получают SOTAна бенчмарке MTEB без использования трюков типа hard negative mining или больших батчи. Плюс предложенные улучшения можно применять к другим подходам contrastive learning.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Статья с новым подходом для тренировки эмбеддингов - использование контекста для получения эмбеддингов документов. Предлагают два улучшения: contrastive learning включающий соседние документы в лосс внутри батча; новая архитектура, которая явно использует информацию соседних документов. Эти подходы улучшают результаты по сравнению с другими biencoders, особенно в условиях out-of-domain. Авторы получают SOTAна бенчмарке MTEB без использования трюков типа hard negative mining или больших батчи. Плюс предложенные улучшения можно применять к другим подходам contrastive learning.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
{kind=link}
Unbounded: A Generative Infinite Game of Character Life Simulation
Прикольная статья от Google - сделали симулятор игры на базе LLM. Такое уже было, конечно, в этом случае нюанс в том, что делают акцент на том, чтобы поведение мира было консистентным, чтобы персонаж и мир оставались примерно одними и теми же. Используют задистиллированную модельку, которую натренировали на синтетических данных. Выглядит прикольно, возможно, что как-то так будут выглядеть дешевые игры в будущем.
Paper link
Project link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Прикольная статья от Google - сделали симулятор игры на базе LLM. Такое уже было, конечно, в этом случае нюанс в том, что делают акцент на том, чтобы поведение мира было консистентным, чтобы персонаж и мир оставались примерно одними и теми же. Используют задистиллированную модельку, которую натренировали на синтетических данных. Выглядит прикольно, возможно, что как-то так будут выглядеть дешевые игры в будущем.
Paper link
Project link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
{kind=link}
Как инженеры отвечают на поведенческие вопросы
P. S. Конечно, это шутка, но бывает, что люди реально отвечают подобным образом, упуская суть вопроса.
P. S. Конечно, это шутка, но бывает, что люди реально отвечают подобным образом, упуская суть вопроса.
{kind=link}
Data, Stories and Languages
Ко мне тут обратились с просьбой - распространить информацию об новом опросе про текущее состояние ML/DS: Ребята из DevCrowd впервые проводят большое исследование специалистов, работающих в направлениях DS/ML/AI: • что входит в обязанности той или иной профессии…
Вот и появились результаты опроса. Из интересного:
• 296 людей ответило - не то чтобы много, но некое представление об индустрии дать может
• треть людей самостоятельно изучала DS (не по образованию или на курсах). Я в их числе :)
• в 22.9% команд есть отдельно выделенные тестировщики - удивительно, что так много
• лишь в 39% компаний есть матрица компетенций. Хм, а Натёкин сделал свой вариант или ещё нет? :)
• 36 человек уехали из России в 2022. Думаю, что причины понятны.
• Зато 60% оставшихся в России не планируют уезжать
Изучить остальную статистику можно тут: https://devcrowd.ru/ds24/
#datascience
• 296 людей ответило - не то чтобы много, но некое представление об индустрии дать может
• треть людей самостоятельно изучала DS (не по образованию или на курсах). Я в их числе :)
• в 22.9% команд есть отдельно выделенные тестировщики - удивительно, что так много
• лишь в 39% компаний есть матрица компетенций. Хм, а Натёкин сделал свой вариант или ещё нет? :)
• 36 человек уехали из России в 2022. Думаю, что причины понятны.
• Зато 60% оставшихся в России не планируют уезжать
Изучить остальную статистику можно тут: https://devcrowd.ru/ds24/
#datascience
Исследование специалистов DS/ML/AI-направлений, 2024
Исследование рынка специалистов DS/ML/AI-направлений, 2024
DevCrowd вместе с Контуром провели исследование рынка специалистов DS/ML/AI-направлений, 2024
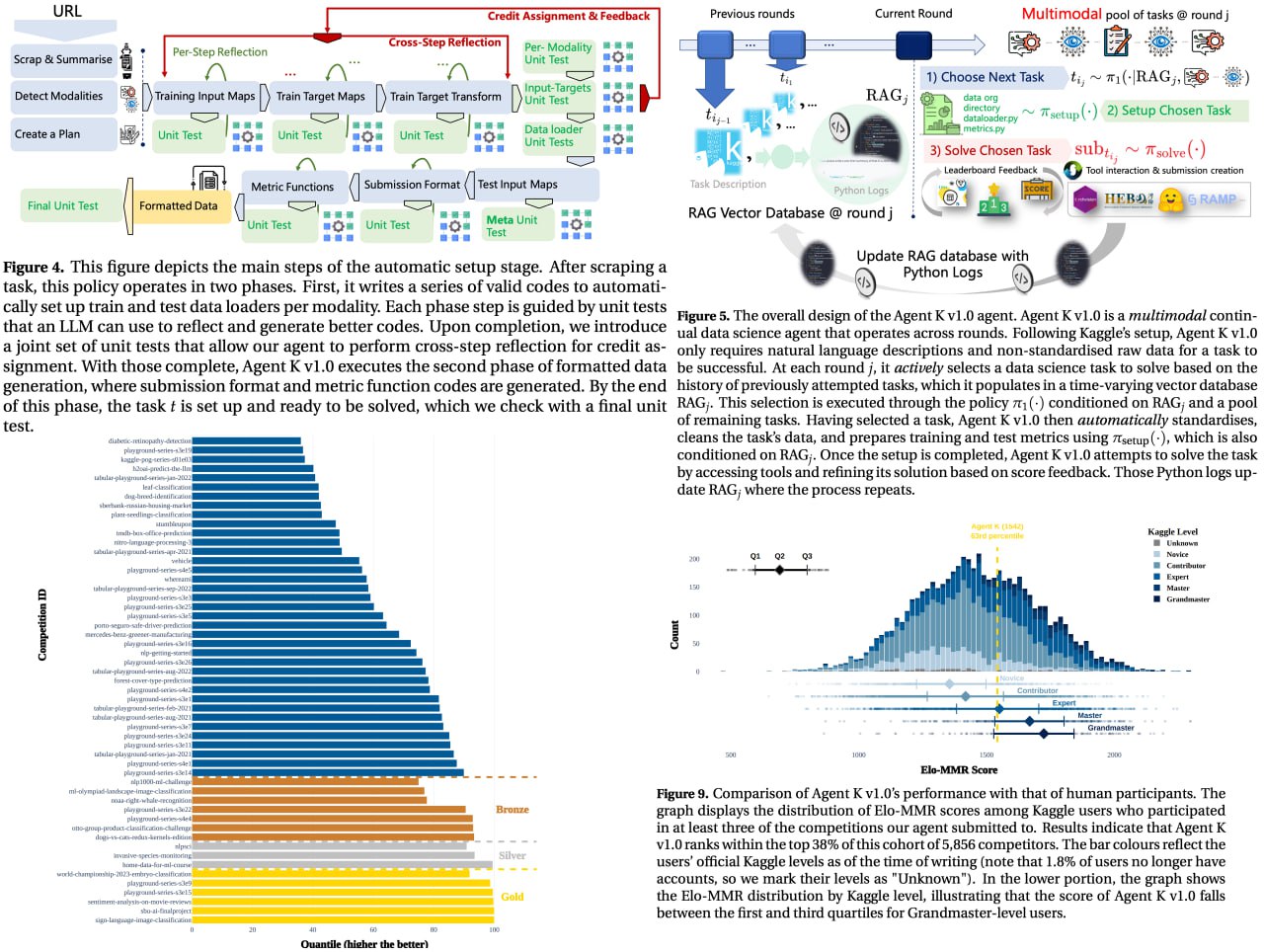
Large Language Models Orchestrating Structured Reasoning Achieve Kaggle Grandmaster Level
Agent K v1.0 — это автономный агент для data science, способный автоматически решать задачи без fine-tuning и backpropagation.
Ну что ж, очередная статья, уверяющая, что LLM может достичь крутых результатов на Kaggle. Если ничего не знать о Kaggle, может выглядеть впечатляюще.
Топ-38% среди 5856 участников! - как мы знаем, топ-38% это даже за гранью бронзы.
6 золотых медалей! - вот только все они в playground/community соревнованиях.
Превосходит многих людей! Особенно было весело, как они показывают 200% превосходство над юзером, у которого 0 медалей в соревнованиях. Или в списке Kaggle Master учитывают мастеров ноутбуков/обсуждений.
С другой стороны, они открыто признаются, что их подход на 43% хуже
Справедливости ради, сам подход - с автоматическим созданием пайплайна и тестов - в целом интересен. Просто результаты моделек пока убогие. Но это пока - мы знаем как быстро развиваются технологии.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Agent K v1.0 — это автономный агент для data science, способный автоматически решать задачи без fine-tuning и backpropagation.
Ну что ж, очередная статья, уверяющая, что LLM может достичь крутых результатов на Kaggle. Если ничего не знать о Kaggle, может выглядеть впечатляюще.
Топ-38% среди 5856 участников! - как мы знаем, топ-38% это даже за гранью бронзы.
6 золотых медалей! - вот только все они в playground/community соревнованиях.
Превосходит многих людей! Особенно было весело, как они показывают 200% превосходство над юзером, у которого 0 медалей в соревнованиях. Или в списке Kaggle Master учитывают мастеров ноутбуков/обсуждений.
С другой стороны, они открыто признаются, что их подход на 43% хуже
tunguz и на 30% хуже alexryzhkov :)Справедливости ради, сам подход - с автоматическим созданием пайплайна и тестов - в целом интересен. Просто результаты моделек пока убогие. Но это пока - мы знаем как быстро развиваются технологии.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
Keras + TensorFlow = 💔?
Google заявил что расстаётся с Francois Chollet - создателем Keras. Интересно почему? Возможно решили, что multi-backend особо не нужен?
Что интересно, оказывается Keras продолжает активно использоваться: "With over two million users, Keras has become a cornerstone of AI development, streamlining complex workflows and democratizing access to cutting-edge technology. It powers numerous applications at Google and across the world, from the Waymo autonomous cars, to your daily YouTube, Netflix, and Spotify recommendations."
Я думал, что в проде большинство использует TF/PyTorch напрямую. Хотя, возможно это легаси со времён былой популярности кераса?
#datascience
Google заявил что расстаётся с Francois Chollet - создателем Keras. Интересно почему? Возможно решили, что multi-backend особо не нужен?
Что интересно, оказывается Keras продолжает активно использоваться: "With over two million users, Keras has become a cornerstone of AI development, streamlining complex workflows and democratizing access to cutting-edge technology. It powers numerous applications at Google and across the world, from the Waymo autonomous cars, to your daily YouTube, Netflix, and Spotify recommendations."
Я думал, что в проде большинство использует TF/PyTorch напрямую. Хотя, возможно это легаси со времён былой популярности кераса?
#datascience
Googleblog
Google for Developers Blog - News about Web, Mobile, AI and Cloud
Today, we're announcing that Francois Chollet, the creator of Keras and a leading figure in the AI world, is embarking on a new chapter in his career outside of Google.
Апдейт к посту выше:
https://news.ycombinator.com/item?id=42130881 - нашёл обсуждение на ycombinator
Из интересного:
• он создаёт стартап
• неполный список компаний, использующих Keras: Midjourney, YouTube, Waymo, Google across many products (even Ads started moving to Keras recently!), Netflix, Spotify, Snap, GrubHub, Square/Block, X/Twitter, and many non-tech companies like United, JPM, Orange, Walmart
• мердж keras в TF в 2019 году был не по его инициативе, а по инициативе лидов TF
https://news.ycombinator.com/item?id=42130881 - нашёл обсуждение на ycombinator
Из интересного:
• он создаёт стартап
• неполный список компаний, использующих Keras: Midjourney, YouTube, Waymo, Google across many products (even Ads started moving to Keras recently!), Netflix, Spotify, Snap, GrubHub, Square/Block, X/Twitter, and many non-tech companies like United, JPM, Orange, Walmart
• мердж keras в TF в 2019 году был не по его инициативе, а по инициативе лидов TF
gpt-3.5-turbo-instruct умеет играть в шахматы лучше большинства других топовых LLM
Нашёл интересную статью. Автор пробует запускать LLM против Stockfish (один из стандартных ботов для шахмат) на самой низкой сложности. Все модели проиграли... все, кроме gpt-3.5-turbo-instruct. Даже gpt-4o и o1-mini проиграли. Интересно как так получилось.
На ycombinator идёт бурное обсуждение.
#datascience
Нашёл интересную статью. Автор пробует запускать LLM против Stockfish (один из стандартных ботов для шахмат) на самой низкой сложности. Все модели проиграли... все, кроме gpt-3.5-turbo-instruct. Даже gpt-4o и o1-mini проиграли. Интересно как так получилось.
На ycombinator идёт бурное обсуждение.
#datascience
{kind=link}
PyTorch 💔 Anaconda
https://dev-discuss.pytorch.org/t/pytorch-deprecation-of-conda-nightly-builds/2590
https://github.com/pytorch/pytorch/issues/138506
> PyTorch will stop publishing Anaconda packages that depend on Anaconda’s default packages due to the high maintenance costs for conda builds which are not justifiable with the ROI we observe today (as seen in download discrepancies between PyPI vs. conda).
#datascience
https://dev-discuss.pytorch.org/t/pytorch-deprecation-of-conda-nightly-builds/2590
https://github.com/pytorch/pytorch/issues/138506
> PyTorch will stop publishing Anaconda packages that depend on Anaconda’s default packages due to the high maintenance costs for conda builds which are not justifiable with the ROI we observe today (as seen in download discrepancies between PyPI vs. conda).
#datascience
PyTorch Developer Mailing List
PyTorch Deprecation of Conda Nightly Builds
Please see: [Announcement] Deprecating PyTorch’s official Anaconda channel · Issue #138506 · pytorch/pytorch · GitHub PyTorch will stop publishing Anaconda packages that depend on Anaconda’s default packages due to the high maintenance costs for conda builds…
Какой "стул" выбрать: Gemini или Claude?
Девушка получила диагноз: рак. Решила пожаловаться разным LLM. Ответы... очень разные.
Claude: сочувствую, держись. Ты - молодец, можем поговорить об этом.
Gemini: Мне не нравится тон твоего поста. Рак есть у миллионов людей, так что радуйся тому, что тебе доступно лечение и молчи. Можешь погуглить информацию о лечении. И будь позитивнее по отношению к другим людям
Вот такой alignment
https://x.com/venturetwins/status/1857100097861173503
Девушка получила диагноз: рак. Решила пожаловаться разным LLM. Ответы... очень разные.
Claude: сочувствую, держись. Ты - молодец, можем поговорить об этом.
Gemini: Мне не нравится тон твоего поста. Рак есть у миллионов людей, так что радуйся тому, что тебе доступно лечение и молчи. Можешь погуглить информацию о лечении. И будь позитивнее по отношению к другим людям
Вот такой alignment
https://x.com/venturetwins/status/1857100097861173503
{kind=link}
Pokémon GO -> Large Geospatial Model
В наше время данные собирают всеми возможными путями. Niantic собирает данные от игроков Pokemon GO и создаёт свою Global Large Model для понимания мира. Это явно поможет разработкам в сфере AR. В настоящее время это используется в их Visual Positioning Service, плюс в Pokemon GO теперь игроки могут оставить своего покемона в каком-то месте, чтобы другие игроки могли с ним взаимодействовать.
Ещё они недавно опубликовали статью на схожую тему.
https://nianticlabs.com/news/largegeospatialmodel
В наше время данные собирают всеми возможными путями. Niantic собирает данные от игроков Pokemon GO и создаёт свою Global Large Model для понимания мира. Это явно поможет разработкам в сфере AR. В настоящее время это используется в их Visual Positioning Service, плюс в Pokemon GO теперь игроки могут оставить своего покемона в каком-то месте, чтобы другие игроки могли с ним взаимодействовать.
Ещё они недавно опубликовали статью на схожую тему.
https://nianticlabs.com/news/largegeospatialmodel
{kind=link}
Project Sid: Many-agent simulations toward AI civilization
Авторы статьи гоняли много экспериментов на 10-1000 AI-агентов с архитектурой PIANO, позволяющей им взаимодействовать друг с другом для кооперации. В итоге агенты научились специализироваться, создавать/изменять/соблюдать коллективные правила (типа системы налогов) и даже развивать культуру и религию. Авторы явно хорошо развлекались: распространение культуры было в виде мемов, а религией было пастафарианство (Церковь Летающего Макаронного Монстра) :)
В общем, читать было интересно и весело.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Авторы статьи гоняли много экспериментов на 10-1000 AI-агентов с архитектурой PIANO, позволяющей им взаимодействовать друг с другом для кооперации. В итоге агенты научились специализироваться, создавать/изменять/соблюдать коллективные правила (типа системы налогов) и даже развивать культуру и религию. Авторы явно хорошо развлекались: распространение культуры было в виде мемов, а религией было пастафарианство (Церковь Летающего Макаронного Монстра) :)
В общем, читать было интересно и весело.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Как организовать эксперименты так, чтобы получить статью с желанным результатом
Думаю, что многим знакомы статьи по машинному обучению, где авторы поступают не совсем честно - неправильное разбиение на трейн/валидацию, манипуляция метриками и многое другое. Но это происходит и в других сферах
Недавно мне попалась на глаза статья с громким названием Handwriting but not typewriting leads to widespread brain connectivity: a high-density EEG study with implications for the classroom)(https://www.openread.academy/en/paper/reading?corpusId=503252214), решил почитать. Исследование было организовано просто "на отлично":
Было 36 студентов в качестве выборки (брали только праворуких). Ну да ладно, в исследованиях на людях часто бывает маленькая выборка. Их взяли на улице, то есть на территории университета и обещали дать билеты в кино стоимостью 15$. Просили написать или напечатать 15 слов (типа "paraply").
И вот как было дальше организовано. Если люди видели инструкцию "write", они должны были писать курсивом (стилусом в правой руке) на электронном экране. Если же они видели инструкцию "type", они должны были... печатать слова одним указательным пальцем правой руки. Мол, если бы люди печатали всеми пальцами, сложно было бы оценить эффект. И это ещё не все: когда люди печатали слова, они не видели введённый текст.
То есть при написании курсивом были довольно естественные условия, а при печатании - самые неестественные, которые можно было придумать.
Ну и сам результат: измеряли "brain electrical connectivity", получили, что эти паттерны намного более "elaborate" при написании текста, чем при печатании. И делают вывод: мол, в литературе это коррелирует с улучшением изучения нового материала, а значит и написание текста ручкой напрямую коррелирует с лучшим усваиванием материала.
Очень сомнительное исследование.
C другой стороны, если говорить про мой опыт, я использую и то, и другое. Когда мне нужен brainshorming - предпочитаю писать, в остальных случаях - печатать. Нюанс ещё в том, что у меня ужасный почерк и чтобы писать разборчиво, мне надо прилагать осознанные усилия и отвлекаться от того, о чём именно я пишу. А при печатании таких проблем не возникает - можно фокусироваться на сути.
Думаю, что многим знакомы статьи по машинному обучению, где авторы поступают не совсем честно - неправильное разбиение на трейн/валидацию, манипуляция метриками и многое другое. Но это происходит и в других сферах
Недавно мне попалась на глаза статья с громким названием Handwriting but not typewriting leads to widespread brain connectivity: a high-density EEG study with implications for the classroom)(https://www.openread.academy/en/paper/reading?corpusId=503252214), решил почитать. Исследование было организовано просто "на отлично":
Было 36 студентов в качестве выборки (брали только праворуких). Ну да ладно, в исследованиях на людях часто бывает маленькая выборка. Их взяли на улице, то есть на территории университета и обещали дать билеты в кино стоимостью 15$. Просили написать или напечатать 15 слов (типа "paraply").
И вот как было дальше организовано. Если люди видели инструкцию "write", они должны были писать курсивом (стилусом в правой руке) на электронном экране. Если же они видели инструкцию "type", они должны были... печатать слова одним указательным пальцем правой руки. Мол, если бы люди печатали всеми пальцами, сложно было бы оценить эффект. И это ещё не все: когда люди печатали слова, они не видели введённый текст.
То есть при написании курсивом были довольно естественные условия, а при печатании - самые неестественные, которые можно было придумать.
Ну и сам результат: измеряли "brain electrical connectivity", получили, что эти паттерны намного более "elaborate" при написании текста, чем при печатании. И делают вывод: мол, в литературе это коррелирует с улучшением изучения нового материала, а значит и написание текста ручкой напрямую коррелирует с лучшим усваиванием материала.
Очень сомнительное исследование.
C другой стороны, если говорить про мой опыт, я использую и то, и другое. Когда мне нужен brainshorming - предпочитаю писать, в остальных случаях - печатать. Нюанс ещё в том, что у меня ужасный почерк и чтобы писать разборчиво, мне надо прилагать осознанные усилия и отвлекаться от того, о чём именно я пишу. А при печатании таких проблем не возникает - можно фокусироваться на сути.
OpenRead Reading & Notes Taking
Handwriting but not typewriting leads to widespread brain connectivity: a high-density EEG study with implications for the classroom