Всем привет! У меня классная новость: в субботу, 16 марта, в 13:00 МСК на YouTube-канале DLS состоится живая открытая лекция от компании Pinely. Приглашаю вас всех тоже!
Тема: Применение машинного обучения на финансовых рынках: вызовы и перспективы.
На лекции обсудим, какие сложности встречаются в задаче оценке справедливой цены, почему использование даже хорошо изученных методов может приводить к неожиданным результатам, и как исследователям помогает математика в анализе и решении этих проблем. Будут конкретные примеры подобных сложностей, их математическая формулировка и возможные решения.
Спикеры:
Павел Швечиков - Team Lead RL в Pinely
Михаил Мосягин - ML Researcher в Pinely
Алексей Пономарев - Developer в Pinely
На лекции можно будет задать любые вопросы спикерам. Ссылка на подключение будет перед началом вебинара. Запись также будет.
Приходите!
Тема: Применение машинного обучения на финансовых рынках: вызовы и перспективы.
На лекции обсудим, какие сложности встречаются в задаче оценке справедливой цены, почему использование даже хорошо изученных методов может приводить к неожиданным результатам, и как исследователям помогает математика в анализе и решении этих проблем. Будут конкретные примеры подобных сложностей, их математическая формулировка и возможные решения.
Спикеры:
Павел Швечиков - Team Lead RL в Pinely
Михаил Мосягин - ML Researcher в Pinely
Алексей Пономарев - Developer в Pinely
На лекции можно будет задать любые вопросы спикерам. Ссылка на подключение будет перед началом вебинара. Запись также будет.
Приходите!
👍64🔥25❤8💩1
Помните, писала пост про десять AI-предсказаний Forbes на 2024 год? Там шестой пункт — про то, что "появятся архитектуры-альтернативы трансформерам". И одним из главных претендентов на архитектуру-убийцу трансформера там была названа Mamba.
Так вот, еще с того момента, как писала тот пост, хотела эту Мамбу заботать, но никак руки не доходили. Но вчера у нас в универ был reading group, который был посвящен как раз Мамбе. Хочу сказать, что reading group действительно помог быстро и понять общую идею модели. Так что собирайтесь в reading club'ы, это круто и полезно)
Но прямо сейчас я пост/статейку про Mamba писать все равно еще не готова, мне нужно понять еще несколько нюансов и заботать статьи, на которых Mamba основана. Пока напишу несколько основных мыслей и тезисов по ней. Поправьте меня, если я вдруг где-то не права.
Начем с того, что Mamba — это не какая-то супер-новая архитектура, которая отличается от всего, что мы видели, и которая взяла и перевернула мир. Mamba основана на State Space Models (SSM) — архитектуре, которая была предложена аж в 1960-х. SSM хорошо подходят для работы с непрерывными типами данных, такими, как аудио.
Главные преимущества SSM:
— количество времени и пямяти, которые требуют SSM во время обучения и инференса, растет линейно относительно длины входной последовательности. Если обучить SSM на задачу языкового моделирования, то модель будет тратить константное количество времени и памяти на каждый шаг генерации;
— SSM легко поддерживают огромный размер контекста, до 1 миллиона токенов.
Это все звучит хорошо. Но для дискретных модальностей, таких, как текст, до сих пор успешно применить SMM не удавалось. То есть, условно, не получалось достичь того, чтобы SMM имела сравнимое с транфсормерами качество на задаче языкового моделирования, не требуя при этом сильно больше времени на inference. Главным препятствием тут было то, что механизм стандартных SSM не позволяет модели выделять из входной последовательности отдельные части информации, которые важны для текущего инпута. А это — очень важное умение для LLM. А те модификации SSM, которые так делать умеют, сразу сильно теряют в скорости.
Авторы Mamba предложили пару модификаций в архитектуру современной SSM, которые и позволили Mamba наделать шуму в обществе и стать, как часто пишут, "угрозой для трансформеров". На задаче языкового моделирования Mamba достигает уровня GPT-NeoX, имея в два раза меньше обучаемых параметров. Более того, скорость инференса у Mamba тоже сильно лучше: она достигает улучшения в 5 раз по сравнению с трансформерами — это просто огромный прорыв для SMM. Конечно, это всего лишь сравнение с GPT-NeoX на нескольких бенчмарках, большой Mamba-based LLM типа GPT-4 еще нет и в помине. Но, на первый взгляд, результаты выглядят очень круто.
Но что же такое эта ваша Mamba? Если оочень кратко, то Mamba — это SSM + MLP блок Трансформера + пара трюков для ускорения модели. По архитектуру Mamba я, надеюсь, позже напишу более подробный пост или статью. А вот в трюках для ускорения становится интересно: они основаны не на архитектурных решениях, а на работе с процессором (т.е. они hardware-aware). На основе знаний о нюансах работы частей GPU, авторы предлагают хранить и обрабатывать тензоры, возникающие в процессе работы SSM, в разных частях GPU. Это сильно ускоряет процесс. Большего я тут пока сказать не могу, потому что практически ничего в устройствах hardware не понимаю (хотя моя мама была инженером-наладчиком ЭВМ, вот это ирония))
Вот как-то так. Надо еще сказать, что больше всего шуму Mamba пока что наводит не в мире NLP/LLM, а в медицине. В этом домене есть данные, представленные в виде последовательностей (геномы), и изображений огромного размера (всякие сканы тканей), поэтому у исследователей есть мысль, что Mamba сможет тут реально помочь. А в NLP то ли очень сильная инерция (мы по уши увязли в трансформерах), то ли у SSM есть серьезные ограничения, которых я пока не понимаю. А может, кто-то уже и ведет работу над SSM-LLM, и мы скоро об этом узнаем)
📃Статья Mamba
Так вот, еще с того момента, как писала тот пост, хотела эту Мамбу заботать, но никак руки не доходили. Но вчера у нас в универ был reading group, который был посвящен как раз Мамбе. Хочу сказать, что reading group действительно помог быстро и понять общую идею модели. Так что собирайтесь в reading club'ы, это круто и полезно)
Но прямо сейчас я пост/статейку про Mamba писать все равно еще не готова, мне нужно понять еще несколько нюансов и заботать статьи, на которых Mamba основана. Пока напишу несколько основных мыслей и тезисов по ней. Поправьте меня, если я вдруг где-то не права.
Начем с того, что Mamba — это не какая-то супер-новая архитектура, которая отличается от всего, что мы видели, и которая взяла и перевернула мир. Mamba основана на State Space Models (SSM) — архитектуре, которая была предложена аж в 1960-х. SSM хорошо подходят для работы с непрерывными типами данных, такими, как аудио.
Главные преимущества SSM:
— количество времени и пямяти, которые требуют SSM во время обучения и инференса, растет линейно относительно длины входной последовательности. Если обучить SSM на задачу языкового моделирования, то модель будет тратить константное количество времени и памяти на каждый шаг генерации;
— SSM легко поддерживают огромный размер контекста, до 1 миллиона токенов.
Это все звучит хорошо. Но для дискретных модальностей, таких, как текст, до сих пор успешно применить SMM не удавалось. То есть, условно, не получалось достичь того, чтобы SMM имела сравнимое с транфсормерами качество на задаче языкового моделирования, не требуя при этом сильно больше времени на inference. Главным препятствием тут было то, что механизм стандартных SSM не позволяет модели выделять из входной последовательности отдельные части информации, которые важны для текущего инпута. А это — очень важное умение для LLM. А те модификации SSM, которые так делать умеют, сразу сильно теряют в скорости.
Авторы Mamba предложили пару модификаций в архитектуру современной SSM, которые и позволили Mamba наделать шуму в обществе и стать, как часто пишут, "угрозой для трансформеров". На задаче языкового моделирования Mamba достигает уровня GPT-NeoX, имея в два раза меньше обучаемых параметров. Более того, скорость инференса у Mamba тоже сильно лучше: она достигает улучшения в 5 раз по сравнению с трансформерами — это просто огромный прорыв для SMM. Конечно, это всего лишь сравнение с GPT-NeoX на нескольких бенчмарках, большой Mamba-based LLM типа GPT-4 еще нет и в помине. Но, на первый взгляд, результаты выглядят очень круто.
Но что же такое эта ваша Mamba? Если оочень кратко, то Mamba — это SSM + MLP блок Трансформера + пара трюков для ускорения модели. По архитектуру Mamba я, надеюсь, позже напишу более подробный пост или статью. А вот в трюках для ускорения становится интересно: они основаны не на архитектурных решениях, а на работе с процессором (т.е. они hardware-aware). На основе знаний о нюансах работы частей GPU, авторы предлагают хранить и обрабатывать тензоры, возникающие в процессе работы SSM, в разных частях GPU. Это сильно ускоряет процесс. Большего я тут пока сказать не могу, потому что практически ничего в устройствах hardware не понимаю (хотя моя мама была инженером-наладчиком ЭВМ, вот это ирония))
Вот как-то так. Надо еще сказать, что больше всего шуму Mamba пока что наводит не в мире NLP/LLM, а в медицине. В этом домене есть данные, представленные в виде последовательностей (геномы), и изображений огромного размера (всякие сканы тканей), поэтому у исследователей есть мысль, что Mamba сможет тут реально помочь. А в NLP то ли очень сильная инерция (мы по уши увязли в трансформерах), то ли у SSM есть серьезные ограничения, которых я пока не понимаю. А может, кто-то уже и ведет работу над SSM-LLM, и мы скоро об этом узнаем)
📃Статья Mamba
❤84👍36🔥18🤮1👌1👻1
Со мной тут поделились ссылкой на стартап, который делает "одежду против распознавания лиц"🤡
Штаны или футболка с кислотными принтами обойдутся в $300+. Заявляется следующее:
Очень интересно, от каких таких систем распознавания людей они собрались "защищать" своей одеждой, что эти системы распознают не лица, а полностью силуэты людей, да еще и что-то знают про собак, жирафов или вязаных игрушек)
Стала дальше смотреть, какие у них пруфы, что их шмотки работают. А пруфы вот:
Типа, ну, от нашей нейронки защищает, значит, работает ¯\_(ツ)_/¯
Стартап к тому времени собрал больше €5000 на Kickstarter, выиграл какую-то итальянскую награду (стартап тоже итальянский) и получил упоминания в CNN, BBC, Wired, Forbes и других местах.
Либо я чего-то сильно недопонимаю в работе систем распознавания людей, либо это довольно красивый развод на деньги😐
Ну хоть в отзывах пишут, что одежда удобная и мягкая. За $300 уж должна быть...
Штаны или футболка с кислотными принтами обойдутся в $300+. Заявляется следующее:
"People wearing the Manifesto Collection are not recognized as "persons" by the AI.
The system recognizes dogs, zebras, giraffes, or small-knitted people inside the fabric."
Очень интересно, от каких таких систем распознавания людей они собрались "защищать" своей одеждой, что эти системы распознают не лица, а полностью силуэты людей, да еще и что-то знают про собак, жирафов или вязаных игрушек)
Стала дальше смотреть, какие у них пруфы, что их шмотки работают. А пруфы вот:
"Whenever we participate in an event, we set up a real-time recognition system showing how our garments work"
Типа, ну, от нашей нейронки защищает, значит, работает ¯\_(ツ)_/¯
Стартап к тому времени собрал больше €5000 на Kickstarter, выиграл какую-то итальянскую награду (стартап тоже итальянский) и получил упоминания в CNN, BBC, Wired, Forbes и других местах.
Либо я чего-то сильно недопонимаю в работе систем распознавания людей, либо это довольно красивый развод на деньги😐
Ну хоть в отзывах пишут, что одежда удобная и мягкая. За $300 уж должна быть...
🤡84😁32🎉11❤6👍4🔥2😱1🤮1
Есть одна вещь в исследованиях вокруг модели CLIP, которую я пока хоть убей не понимаю. Давайте вам расскажу, может, поможете мне понять, в чем я не права.
Осенью я как-то ковыряла CLIP, и наткнулась на сразу кучку статей по очень странной, казалось бы, теме: prompt tuning for visual-language models. Идея этих статей следующая:
Смотрите, вот есть CLIP. Напомню, что это две нейросети — text encoder и image encoder. Эти нейросети переводят текст и изображения в общее пространство эмбеддингов. То есть, если есть картинка и ее текст-описание, то эмбеддинг картинки, полученный из image encoder, будет близок по косинусному расстоянию к эмбеддингу текста, полученному из text encoder. А если текст картинке не соответствует, то эмбеддинги текста и картинки будут по косинусному расстоянию далеки.
Так вот, с помощью CLIP можно решать задачу классификации картинок в zero-shot режиме, т.е. вообще без дообучения. Берем тестовый датасет картинок и названия их классов ('fish', 'dog', ...). Прогоняем названия классов через text encoder, получаем эмбеддинги классов. Далее для каждой картинки получаем ее эмбеддинг из image encoder и сравниваем его по косинусному расстоянию со всеми эмбеддингами классов. Тот класс, для которого косинусное расстояние вышло наименьшим, и будет ответом для картинки.
Таким макаром набирается, скажем, 0.65 accuracy на валидации ImageNet. А дальше возникает следующая идея: давайте придумаем, как получать более хорошие эмбеддинги классов, чтобы zero-shot accuracy стал еще выше. Например, хорошо работает идея с добавлением к названиям классов префикса 'a photo of'. Т.е. если получить эмбеддинги классов в виде 'a photo of <class_name>', то с такими эмбеддингами zero-shot acc станет на пару процентов выше.
И дальше начинаются танцы с бубнами вокруг темы "какой бы придумать префикс еще получше". Пишутся статьи вида "давайте использовать несколько разных префиксов и потом усреднять эмбеддинги классов, полученные с помощью этих префиксов", "давайте нагенерим кучу вариантов префиксов и каким-то хитрым алгоритмом выберем их них n лучших" и т.п. Вот пример подобной недавней статьи, первый ее автор из Кембриджа.
А дальше еще веселее. Возникает идея: а давайте не просто подбирать разные префиксы и их смешивать, давайте учить псевдо-префикс. Т.е. берем n "псевдо-эмбеддингов слов", берем эмбеддинг названия класса, конкатенируем их и получаем эмбеддинг промпта вида <псевдо-слово_1, ..., псевдо-слово_n, class_name>. На небольшой части трейн сета ImageNet учим эти n псевдо-эмбеддингов слов так, чтобы zero-shot результат классификации картинок ImageNet с помощью этих псевдо-эмбеддингов был как можно выше.
Так вот, к чему я это все. А к тому, что, мне кажется, что сама идея тюнинга промптом для CLIP совершенно не имеет смысла.
Объясню мысль в следующем посте ⬇️
Осенью я как-то ковыряла CLIP, и наткнулась на сразу кучку статей по очень странной, казалось бы, теме: prompt tuning for visual-language models. Идея этих статей следующая:
Смотрите, вот есть CLIP. Напомню, что это две нейросети — text encoder и image encoder. Эти нейросети переводят текст и изображения в общее пространство эмбеддингов. То есть, если есть картинка и ее текст-описание, то эмбеддинг картинки, полученный из image encoder, будет близок по косинусному расстоянию к эмбеддингу текста, полученному из text encoder. А если текст картинке не соответствует, то эмбеддинги текста и картинки будут по косинусному расстоянию далеки.
Так вот, с помощью CLIP можно решать задачу классификации картинок в zero-shot режиме, т.е. вообще без дообучения. Берем тестовый датасет картинок и названия их классов ('fish', 'dog', ...). Прогоняем названия классов через text encoder, получаем эмбеддинги классов. Далее для каждой картинки получаем ее эмбеддинг из image encoder и сравниваем его по косинусному расстоянию со всеми эмбеддингами классов. Тот класс, для которого косинусное расстояние вышло наименьшим, и будет ответом для картинки.
Таким макаром набирается, скажем, 0.65 accuracy на валидации ImageNet. А дальше возникает следующая идея: давайте придумаем, как получать более хорошие эмбеддинги классов, чтобы zero-shot accuracy стал еще выше. Например, хорошо работает идея с добавлением к названиям классов префикса 'a photo of'. Т.е. если получить эмбеддинги классов в виде 'a photo of <class_name>', то с такими эмбеддингами zero-shot acc станет на пару процентов выше.
И дальше начинаются танцы с бубнами вокруг темы "какой бы придумать префикс еще получше". Пишутся статьи вида "давайте использовать несколько разных префиксов и потом усреднять эмбеддинги классов, полученные с помощью этих префиксов", "давайте нагенерим кучу вариантов префиксов и каким-то хитрым алгоритмом выберем их них n лучших" и т.п. Вот пример подобной недавней статьи, первый ее автор из Кембриджа.
А дальше еще веселее. Возникает идея: а давайте не просто подбирать разные префиксы и их смешивать, давайте учить псевдо-префикс. Т.е. берем n "псевдо-эмбеддингов слов", берем эмбеддинг названия класса, конкатенируем их и получаем эмбеддинг промпта вида <псевдо-слово_1, ..., псевдо-слово_n, class_name>. На небольшой части трейн сета ImageNet учим эти n псевдо-эмбеддингов слов так, чтобы zero-shot результат классификации картинок ImageNet с помощью этих псевдо-эмбеддингов был как можно выше.
Так вот, к чему я это все. А к тому, что, мне кажется, что сама идея тюнинга промптом для CLIP совершенно не имеет смысла.
Объясню мысль в следующем посте ⬇️
👍28🤔12🔥4❤3❤🔥1🥰1🤮1
(продолжение поста выше)
Поясню, почему я так думаю. Идея обучения промпта (prompt-tuning) далеко не нова. Она активно используется в NLP и языковых моделях в частности. Идея там такая: пусть у нас есть модель, которая на вход принимает задачу в виде текста на естественном языке. Например, "Translate the following sentence to French: I love machine learning". Моделька, скорее всего, большая, с большим количеством параметром. Если нам захочется дообучить ее под свою задачу, это потребует большого количества данных, времени и хорошего GPU. И тогда возникает хорошая идея: а давайте дообучать модельку не будем, а будем учить правильный промпт-формулировку задачи. Это гораздо проще и быстрее, и часто дает хорошие результаты. Эта идея в NLP работает примерно с появления T5 — первой достаточно большой модели, которая могла решать сразу несколько задачи и принимала на вход описание задачи на естественном языке.
Казалось бы, если идея так хороша с языковыми моделями, то почему бы не применить к CLIP? Собственно, так и рассужали авторы статьи "Learning to Prompt for Vision-Language Models", которая и предлагает идею выучивания промпта для CLIP, которую я описала выше. Но тут есть одно "но": в случае с CLIP у нас есть доступ к внутреннему пространству эмбеддингов текстов и картинок. И мы можем работать прямо в нем.
То есть, мы можем, получить из CLIP эмбеддинги названий классов и картинок, а дальше, например, навесить на эмбеддинги картинок/текста мини-нейросеть-адаптер из пары слоев. И учить эту мини-нейросеть на трейне ImageNet так, чтобы она выдавала новые эмбеддинги картинок/текста. Такие, что на них zero-shot классификация на валидации ImageNet будет показывать лучший accuracy.
И так даже сделали. Вот работа с названием CLIP-Adapter, которая сделала ровно это. Авторы показали, что это работет лучше обучения промптов из работы выше.
Вот так. Короче, я не понимаю, почему люди все еще пытаются учить промпты для CLIP, когда, казалось бы, это не имеет смысла. Зачем учить что-то (промпт), что должно порождать хорошие результаты после некоего сложно преобразования (text encoder), когда мы можем сделать намного проще — учить что-то (нейросеть-адаптер), что само сразу должно порождать нужный результат? Кажется, что в случае нейросети-адаптера задача ставится намного проще, и с оптимизационной точки зрения решить ее легче (не надо тюнить что-то, что проходит через сложное преобразование перед подачей в лосс).
И самое веселое — у статьи "Learning to Prompt for Vision-Language Models" больше 1200 цитирований😐 Это очень много. А еще на той же самой идее эти авторы написали еще статей, где чуть улучшили идею обучения промптов. И на них еще по 800 цитирований тоже...
В общем, помогите Тане понять, в чем смысл prompt-learning для CLIP, ато я совсем не знаю(
Поясню, почему я так думаю. Идея обучения промпта (prompt-tuning) далеко не нова. Она активно используется в NLP и языковых моделях в частности. Идея там такая: пусть у нас есть модель, которая на вход принимает задачу в виде текста на естественном языке. Например, "Translate the following sentence to French: I love machine learning". Моделька, скорее всего, большая, с большим количеством параметром. Если нам захочется дообучить ее под свою задачу, это потребует большого количества данных, времени и хорошего GPU. И тогда возникает хорошая идея: а давайте дообучать модельку не будем, а будем учить правильный промпт-формулировку задачи. Это гораздо проще и быстрее, и часто дает хорошие результаты. Эта идея в NLP работает примерно с появления T5 — первой достаточно большой модели, которая могла решать сразу несколько задачи и принимала на вход описание задачи на естественном языке.
Казалось бы, если идея так хороша с языковыми моделями, то почему бы не применить к CLIP? Собственно, так и рассужали авторы статьи "Learning to Prompt for Vision-Language Models", которая и предлагает идею выучивания промпта для CLIP, которую я описала выше. Но тут есть одно "но": в случае с CLIP у нас есть доступ к внутреннему пространству эмбеддингов текстов и картинок. И мы можем работать прямо в нем.
То есть, мы можем, получить из CLIP эмбеддинги названий классов и картинок, а дальше, например, навесить на эмбеддинги картинок/текста мини-нейросеть-адаптер из пары слоев. И учить эту мини-нейросеть на трейне ImageNet так, чтобы она выдавала новые эмбеддинги картинок/текста. Такие, что на них zero-shot классификация на валидации ImageNet будет показывать лучший accuracy.
И так даже сделали. Вот работа с названием CLIP-Adapter, которая сделала ровно это. Авторы показали, что это работет лучше обучения промптов из работы выше.
Вот так. Короче, я не понимаю, почему люди все еще пытаются учить промпты для CLIP, когда, казалось бы, это не имеет смысла. Зачем учить что-то (промпт), что должно порождать хорошие результаты после некоего сложно преобразования (text encoder), когда мы можем сделать намного проще — учить что-то (нейросеть-адаптер), что само сразу должно порождать нужный результат? Кажется, что в случае нейросети-адаптера задача ставится намного проще, и с оптимизационной точки зрения решить ее легче (не надо тюнить что-то, что проходит через сложное преобразование перед подачей в лосс).
И самое веселое — у статьи "Learning to Prompt for Vision-Language Models" больше 1200 цитирований😐 Это очень много. А еще на той же самой идее эти авторы написали еще статей, где чуть улучшили идею обучения промптов. И на них еще по 800 цитирований тоже...
В общем, помогите Тане понять, в чем смысл prompt-learning для CLIP, ато я совсем не знаю(
👍54🤔10🔥6❤3🥰3🤯3❤🔥1💩1🤨1
Всем привет! в субботу, 27 числа, я буду записывать новый выпуск подкаста Deep Learning Stories. Тема выпуска — соревнования по машинному обучению: взгляд со стороны участника и организатора.
Гости выпуска — Ринат Шарафетдинов, ML-инженер в команде прогнозирования спроса, и Евгений Финогеев, тимлид команды матчинга и машинного обучения, в Samokat.tech.
С гостями обсудим:
- какие соревнования по ML бывают и чем командные соревнования отличаются от индивидуальных;
- в каких соревнованиях стоит участвовать и где их находить;
- зачем компании проводят соревнования по машинному обучению и как сделать соревнование интересным;
- организация соревнований: от подготовки данных до оценки решений;
- насколько участие в соревнованиях полезно для карьеры. Хотят ли компании нанимать Kaggle-мастеров?
Как обычно, задавайте ваши вопросы по теме в комментариях под этим постом. Я постараюсь добавить эти вопросы в программу.
А прошлые выпуски подкаста Deep Learning Stroeis можно найти тут:
- Yandex Music
- Apple Music
- Google Music
- Spotify
- YouTube
#podcast
Гости выпуска — Ринат Шарафетдинов, ML-инженер в команде прогнозирования спроса, и Евгений Финогеев, тимлид команды матчинга и машинного обучения, в Samokat.tech.
С гостями обсудим:
- какие соревнования по ML бывают и чем командные соревнования отличаются от индивидуальных;
- в каких соревнованиях стоит участвовать и где их находить;
- зачем компании проводят соревнования по машинному обучению и как сделать соревнование интересным;
- организация соревнований: от подготовки данных до оценки решений;
- насколько участие в соревнованиях полезно для карьеры. Хотят ли компании нанимать Kaggle-мастеров?
Как обычно, задавайте ваши вопросы по теме в комментариях под этим постом. Я постараюсь добавить эти вопросы в программу.
А прошлые выпуски подкаста Deep Learning Stroeis можно найти тут:
- Yandex Music
- Apple Music
- Google Music
- Spotify
- YouTube
#podcast
👍49🔥24❤8
Помните, писала, что мы в DLS проводим первую олимпиаду по ML? Так вот, мы ее успешно провели в марте, а сейчас выложили на сайт все задания с решениями. Они вот тут ➡️ https://dls.samcs.ru/olympics. Если хотите попрактиковаться, welcome)
На олимпиаде было два этапа (отборочный и финальный), и два трека: для школьников и для студентов+ (т.е. для всех желающих всех возрастов). Получается, всего 4 набора задач (хотя некоторые у школьников и студентов пересекаются). В каждом наборе задач несколько теоретических задач на ML/DL, в которых нужно отправить ответ, и три практических, где нужно построить модель машинного обучения на основе датасета. Мы сделали так, что теорзадачи — они не просто на математику, а именно на ML, т.е. в них нужно знать концепты машинного обучения.
По кнопке "задания" на сатйте открывается Яндекс.Контест, где есть условия и можно отправлять решения на проверку. А по кнопке "решения" откроется google colab с решениями задач.
Если будете решать, делитесь, какие задачи вам понравились больше всего)
На олимпиаде было два этапа (отборочный и финальный), и два трека: для школьников и для студентов+ (т.е. для всех желающих всех возрастов). Получается, всего 4 набора задач (хотя некоторые у школьников и студентов пересекаются). В каждом наборе задач несколько теоретических задач на ML/DL, в которых нужно отправить ответ, и три практических, где нужно построить модель машинного обучения на основе датасета. Мы сделали так, что теорзадачи — они не просто на математику, а именно на ML, т.е. в них нужно знать концепты машинного обучения.
По кнопке "задания" на сатйте открывается Яндекс.Контест, где есть условия и можно отправлять решения на проверку. А по кнопке "решения" откроется google colab с решениями задач.
Если будете решать, делитесь, какие задачи вам понравились больше всего)
dls.samcs.ru
Олимпиада
Олимпиада Deep Learning School
❤41❤🔥8🔥7
Расскажу еще про мою любимую задачу из олимпиады — это задача "Неоднозначный PCA" (задача B в отборе у студентов+).
Мы ее придумали вместе с Юрой Яровиковым (co-head of DLS), и из процесса создания этой задачи получилась целая история. Например, мы сами сначала решили ее неверно, а когда перерешали правильно, прям прониклись)
Попробуйте решить и вы ⬇️
(не забывайте прятать под спойлер ответ, если пишете его в комментарии)
Мы ее придумали вместе с Юрой Яровиковым (co-head of DLS), и из процесса создания этой задачи получилась целая история. Например, мы сами сначала решили ее неверно, а когда перерешали правильно, прям прониклись)
Попробуйте решить и вы ⬇️
Известно, что алгоритм PCA не всегда даёт однозначный ответ, потому что максимальный разброс может достигаться в проекции на несколько различных направляющих векторов.
Дан набор данных из 8 точек в трёхмерном пространстве, где точки являются вершинами 3-мерного куба. Для этого набора данных обучили PCA с одной главной компонентой (n_components=1 в библиотеке sklearn). Какое количество различных ответов могло получиться? Иными словами, найдите количество направлений, проекции точек 3-мерного куба на которые имеют максимальный разброс. Направления, отличающиеся только знаком направляющего вектора, считаются различными.
(не забывайте прятать под спойлер ответ, если пишете его в комментарии)
❤🔥25👀12🤓7❤2👍1
Всем привет! Как вы заметили, Танечка (то есть, я) была немного в отпуске от канала, в основном потому что жизнь иногда бывает сложной🫠
Но потихоньку возвращаюсь. И давайте для начала расскажу, что произошло за последнее время хорошего/интересного:
✔️Вышли три статьи, в которых я соавтор (у двух я первый автор, у одной — второй). И две из них уже приняты на конференции! Статьи вот:
- RAVE: Residual Vector Embedding for CLIP-Guided Backlit Image Enhancement (принята на ECCV-2024). Это статья про то, как улучшать засвеченные изображения используя свойства внутреннего пространства модели CLIP. Напишу тут про нее подробный пост чуть позже.
- AI-generated text boundary detection with RoFT (принята на COLM-2024). Эта статья с исследованием методов для детекции границы между реальным и сгенерированным текстов. Первый автор статьи — Лаида, и у нее в канале есть пост про эту статью
- Improving Interpretability and Robustness for the Detection of AI-Generated Images (under review). Тут мы также с Лаидой и другими коллегами исследовали подходы для улучшения робастности и интерпретируемости подходов к детекции сгенерированных картинок. Пару дней назад Лаида и про эту статью пост написала, welcome к ней в канал читать)
Кстати, в связи с принятием статьи на ECCV я туда поеду. Буду рада встретиться с теми, кто там тоже будет)
✔️В этом году впервые проводится такая вещь как международная олимпиада по искусственному интеллекту для школьников (IOAI). Проводится она в Болгарии с 9 августа, а прямо сейчас идет подготовка команд. Я тоже немного помогаю с подготовкой команды России.
Олимпиада эта выглядит довольно необычно. Вообще не так, как я бы представляла обычную олимпиаду по AI или математике. На самом деле, все еще практически не понятно, что именно школьников ждет на самой олимпиаде в Болгарии, но вот что пока есть:
- Sample problems на сайте олимпиады;
- Take-home задачи, которые разослали командам. Это три задачи (по ML, CV и NLP), которые нужно решить дома и сдать решения до 4 августа. Вот эти задачи очень интересные, на самом деле. Надеюсь, что после олимпиады их выложат в открытый доступ. Как только это случится, напишу);
Короче, очень интересно, что будет на финале. Как только он пройдет, напишу об этом тут)
Но потихоньку возвращаюсь. И давайте для начала расскажу, что произошло за последнее время хорошего/интересного:
✔️Вышли три статьи, в которых я соавтор (у двух я первый автор, у одной — второй). И две из них уже приняты на конференции! Статьи вот:
- RAVE: Residual Vector Embedding for CLIP-Guided Backlit Image Enhancement (принята на ECCV-2024). Это статья про то, как улучшать засвеченные изображения используя свойства внутреннего пространства модели CLIP. Напишу тут про нее подробный пост чуть позже.
- AI-generated text boundary detection with RoFT (принята на COLM-2024). Эта статья с исследованием методов для детекции границы между реальным и сгенерированным текстов. Первый автор статьи — Лаида, и у нее в канале есть пост про эту статью
- Improving Interpretability and Robustness for the Detection of AI-Generated Images (under review). Тут мы также с Лаидой и другими коллегами исследовали подходы для улучшения робастности и интерпретируемости подходов к детекции сгенерированных картинок. Пару дней назад Лаида и про эту статью пост написала, welcome к ней в канал читать)
Кстати, в связи с принятием статьи на ECCV я туда поеду. Буду рада встретиться с теми, кто там тоже будет)
✔️В этом году впервые проводится такая вещь как международная олимпиада по искусственному интеллекту для школьников (IOAI). Проводится она в Болгарии с 9 августа, а прямо сейчас идет подготовка команд. Я тоже немного помогаю с подготовкой команды России.
Олимпиада эта выглядит довольно необычно. Вообще не так, как я бы представляла обычную олимпиаду по AI или математике. На самом деле, все еще практически не понятно, что именно школьников ждет на самой олимпиаде в Болгарии, но вот что пока есть:
- Sample problems на сайте олимпиады;
- Take-home задачи, которые разослали командам. Это три задачи (по ML, CV и NLP), которые нужно решить дома и сдать решения до 4 августа. Вот эти задачи очень интересные, на самом деле. Надеюсь, что после олимпиады их выложат в открытый доступ. Как только это случится, напишу);
Короче, очень интересно, что будет на финале. Как только он пройдет, напишу об этом тут)
🔥107❤31👍21👻2👎1👏1🤮1
Такой вопрос: может быть, среди вас или ваших знакомых кто-то едет на конференцию COLM в октябре?
Дело в том, что у нас приняли на нее статью (см. пост выше), и обязательно нужно, чтобы кто-то пришел ножками на конференцию и постоял рядом с ее постером. Но конференция в США (Филадельфия), и ни у кого из авторов нет туда визы =( У меня стоит собеседование на визу 27 сентября, но меня с очень большой вероятностью развернут с administrative check. Так что если кто-то едет, вы бы очень сильно нас выручили. С нас плюшки🙃
Дело в том, что у нас приняли на нее статью (см. пост выше), и обязательно нужно, чтобы кто-то пришел ножками на конференцию и постоял рядом с ее постером. Но конференция в США (Филадельфия), и ни у кого из авторов нет туда визы =( У меня стоит собеседование на визу 27 сентября, но меня с очень большой вероятностью развернут с administrative check. Так что если кто-то едет, вы бы очень сильно нас выручили. С нас плюшки🙃
😢53❤8🔥7🥰5🤮1🕊1
Наверное, многие слышали новость о том, что "AI завоевал серебро на межнаре по математике (IMO)" Так вот, я прочитала блогпост DeepMind по этому поводу и собрала главные поинты про модельку в пост.
Для начала, вводная по олимпиаде. IMO — это международная математическая олимпиада, высшая ступень олимпиад по математике. От каждой страны туда едет команда из шести человек. Олимпиада проходит в два дня, в каждый из дней дается три задачи и 4.5 часа на их решение. Задачи бывают четырех видов по темам: алгебра, теория чисел (тч), комбинаторика и геометрия. Каждая задача оценивается из 7 баллов, где 7 баллов — это полностью правильное решение задачи без ошибок и пробелов в рассуждении. Промежуточные баллы от 0 до 7 за решение получить при этом тоже можно. Например, если в решении пропущены пара незначительных моментов, поставят 5-6 баллов, а если задача не решена, но написаны идеи, потенциально ведущие к правильному решению, то можно получить до трех баллов.
Теперь, как устроена система для решения IMO от DeepMind и что там интересного:
Задачи по алгебре, тч и комбе решала модель AlphaProof, а по геометрии – другая, AlphaGeometry2. Всего модель решила 4 из 6 задач, все полностью правильно. Получается, набрала 7*4=28 баллов из возможных 36. Это — серебро на IMO 2024. Золото выдавалось от 29🤣
Теперь про модельки. Начнем с AlphaProof.
AlphaProof принимает на вход условие задачи и генерируют решение на формальном языке Lean. Получается, нужно как-то уметь переводить условие задачи, записанное на английском языке, на язык Lean. Для этого DeepMind взяли свою LLM Gemini и дообучили ее на эту задачу. Теперь условие задачи сначала попадает в Gemini, который переводит ее на Lean, и затем подает на вход AlphaProof.
AlphaProof — это RL-модель, практически идентичная AlphaZero, которая играла в Go. Работает AlphaProof так: сначала генерирует возможный ответ на задачу, а затем пытается доказать или опровергнуть правильность этого ответа, блуждая по пространству возможных утверждений-шагов доказательства (proof steps). Если удалось собрать верное доказательство, то этот пример используется для дообучения AlphaProof. Пишут, что до IMO модельку обучали на огромном пуле разных задач, а на самой олимпиаде делали вот что: генерировали разые вариации задач олимпиады, просили AlphaProof их решить, а верно найденные решения тоже использовали для дообучения AlphaProof на ходу. И так, пока не будет найдено решение основной задачи. Чем-то напоминает то, как люди тоже сначала стараются решить relaxed версии задач, прежде чем додуматься до решения основной.
Из интересного:
— на IMO были две задачи на алгебру, одна на тч, две на комбу и одна на геометрию. AlphaProof решила обе алгебры и тч, но не смогла решить ни одну комбинаторику😂 В принципе, у человеков тоже обычно проблемы с комбой, судя по моему школьному опыту...
— время, потраченное AlphaProof на решение разных задач, очень разное. Одни задачи она решила за минуты, а на другую потратила три дня. Учитывая, что у людей на решение трех задач дается 4.5 часа, то сравнение модели с человеками-участниками олимпиады не очень честное;
— решения модель выдавала только на те задачи, которые точно полностью смогла решить. Частичные решения модели не оценивались. Вот тут нечестно в другую сторону: возможно, с частичными решениями задач на комбу модель могла бы получить и больше 28 баллов, претендуя и на золото;
— утверждается, что решения модели полностью в соответствии с правилами олимпиады проверяли два уважаемых математика: Prof Sir Timothy Gowers (золотой медалист IMO и филдсовский лауреат) и Dr Joseph Myers (дважды золотой медалист IMO и член комитета IMO). Так что свои 28 баллов моделька, кажется, получила честно.
Продолжение ⬇️
Для начала, вводная по олимпиаде. IMO — это международная математическая олимпиада, высшая ступень олимпиад по математике. От каждой страны туда едет команда из шести человек. Олимпиада проходит в два дня, в каждый из дней дается три задачи и 4.5 часа на их решение. Задачи бывают четырех видов по темам: алгебра, теория чисел (тч), комбинаторика и геометрия. Каждая задача оценивается из 7 баллов, где 7 баллов — это полностью правильное решение задачи без ошибок и пробелов в рассуждении. Промежуточные баллы от 0 до 7 за решение получить при этом тоже можно. Например, если в решении пропущены пара незначительных моментов, поставят 5-6 баллов, а если задача не решена, но написаны идеи, потенциально ведущие к правильному решению, то можно получить до трех баллов.
Теперь, как устроена система для решения IMO от DeepMind и что там интересного:
Задачи по алгебре, тч и комбе решала модель AlphaProof, а по геометрии – другая, AlphaGeometry2. Всего модель решила 4 из 6 задач, все полностью правильно. Получается, набрала 7*4=28 баллов из возможных 36. Это — серебро на IMO 2024. Золото выдавалось от 29
Теперь про модельки. Начнем с AlphaProof.
AlphaProof принимает на вход условие задачи и генерируют решение на формальном языке Lean. Получается, нужно как-то уметь переводить условие задачи, записанное на английском языке, на язык Lean. Для этого DeepMind взяли свою LLM Gemini и дообучили ее на эту задачу. Теперь условие задачи сначала попадает в Gemini, который переводит ее на Lean, и затем подает на вход AlphaProof.
AlphaProof — это RL-модель, практически идентичная AlphaZero, которая играла в Go. Работает AlphaProof так: сначала генерирует возможный ответ на задачу, а затем пытается доказать или опровергнуть правильность этого ответа, блуждая по пространству возможных утверждений-шагов доказательства (proof steps). Если удалось собрать верное доказательство, то этот пример используется для дообучения AlphaProof. Пишут, что до IMO модельку обучали на огромном пуле разных задач, а на самой олимпиаде делали вот что: генерировали разые вариации задач олимпиады, просили AlphaProof их решить, а верно найденные решения тоже использовали для дообучения AlphaProof на ходу. И так, пока не будет найдено решение основной задачи. Чем-то напоминает то, как люди тоже сначала стараются решить relaxed версии задач, прежде чем додуматься до решения основной.
Из интересного:
— на IMO были две задачи на алгебру, одна на тч, две на комбу и одна на геометрию. AlphaProof решила обе алгебры и тч, но не смогла решить ни одну комбинаторику
— время, потраченное AlphaProof на решение разных задач, очень разное. Одни задачи она решила за минуты, а на другую потратила три дня. Учитывая, что у людей на решение трех задач дается 4.5 часа, то сравнение модели с человеками-участниками олимпиады не очень честное;
— решения модель выдавала только на те задачи, которые точно полностью смогла решить. Частичные решения модели не оценивались. Вот тут нечестно в другую сторону: возможно, с частичными решениями задач на комбу модель могла бы получить и больше 28 баллов, претендуя и на золото;
— утверждается, что решения модели полностью в соответствии с правилами олимпиады проверяли два уважаемых математика: Prof Sir Timothy Gowers (золотой медалист IMO и филдсовский лауреат) и Dr Joseph Myers (дважды золотой медалист IMO и член комитета IMO). Так что свои 28 баллов моделька, кажется, получила честно.
Продолжение ⬇️
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥59❤11👍5😈3
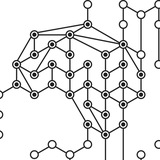
Теперь про AlphaGeometry2. Это улучшение первой версии AlphaGeometry, но основная идея их работы одинаковая. AlphaGeometry состоит из двух частей: symbolic deduction engine (SDE) и LLM. Решение задачи происходит так: сначала в модель подаются все вводные по задаче (дан треугольник такой-то, этот угол такой-то), и symbolic deduction engine на основе этих данных генерирует все возможные выводы. Например, если из вводных данных можно исходя из геометрических правил понять, что ∠ABC=60°, то SDE это выведет. SDE — это не обучаемая штука, она оперирует правилами геометрии и при работе строит граф выводов.
Однако одной SDE для решения сложных задач часто не хватает. Чтобы решить олимпиадные задачи по геометрии, часто в них нужно генерировать новые сущности. Например, сделать что-то вида "давайте обозначим середину отрезка AB через D и проведем прямую CD, тогда ∠ACD=40° и отсюда получим, что...". Чтобы научить AlphaGeometry так делать, авторы взяли LLM и учили ее на основе имеющейся инфы о задаче генерировать подобные идеи.
В итоге процесс работы AlphaGeometry выглядит так:
1. SDE выводит все возможные утверждения, пока они не закончатся или не будет найдено решение задачи;
2. Если SDE отработала и решение не найдено, LLM-часть предлагает новую сущность (типа, го поставим вот эту точку)
3. Возвращаемся в пункт 1 и продолжаем далее.
(см 1 и 2 картинку к посту для иллюстрации процесса)
LLM-часть учили на огромном количестве геом задач, многие из которых генерировали синтетически. На IMO-2024 AlphaGeometry геом в итоге решила, причем при решении тоже потребовалось обозначить новую сущность — точку E на рисунке (третья картинка к посту)
Больше про AlphaGeometry:
✔️блогпост DeepMind;
✔️статья в Nature;
✔️код на GitHub.
Однако одной SDE для решения сложных задач часто не хватает. Чтобы решить олимпиадные задачи по геометрии, часто в них нужно генерировать новые сущности. Например, сделать что-то вида "давайте обозначим середину отрезка AB через D и проведем прямую CD, тогда ∠ACD=40° и отсюда получим, что...". Чтобы научить AlphaGeometry так делать, авторы взяли LLM и учили ее на основе имеющейся инфы о задаче генерировать подобные идеи.
В итоге процесс работы AlphaGeometry выглядит так:
1. SDE выводит все возможные утверждения, пока они не закончатся или не будет найдено решение задачи;
2. Если SDE отработала и решение не найдено, LLM-часть предлагает новую сущность (типа, го поставим вот эту точку)
3. Возвращаемся в пункт 1 и продолжаем далее.
(см 1 и 2 картинку к посту для иллюстрации процесса)
LLM-часть учили на огромном количестве геом задач, многие из которых генерировали синтетически. На IMO-2024 AlphaGeometry геом в итоге решила, причем при решении тоже потребовалось обозначить новую сущность — точку E на рисунке (третья картинка к посту)
Больше про AlphaGeometry:
✔️блогпост DeepMind;
✔️статья в Nature;
✔️код на GitHub.
🔥75👍22❤10👏4⚡1🤮1
Я тут недавно перед одним интервью на стажировку решила-таки немножко заботать тему inference-time ускорения и сжатия больших моделей. В конце концов, модельки становятся все больше, требуют все больше памяти и времени для работы. Именно поэтому тема ускорения и сжатия сейчас очень на слуху — хочется понимать, что там в целом происходит.
Так вот, разных подходов к ускорению/сжатию моделей, конечно, очень много. Некоторые из них используют особенности железа (строения CPU/GPU), модифицируя некоторые операции внутри моделей так, чтобы они выполнялись как можно эффективнее на конкретном железе. Примеры таких подходов — FlashAttention и Mamba. Есть и другие подходы, которые работают с самой моделькой, стараясь добиться эффективного сжатия/ускорения вне зависимости от железа. И вот тут становится интересно, тут часто возникает красивая математика. И вот на прошлой неделе на ICML 2024 представили одну такую работу от исследователей Yandex Research и IST Austria по сжатию LLM с красивой математикой и довольно внушительными результатами.
Статья называется Extreme Compression of Large Language Models via Additive Quantization. Это метод экстремального сжатия LLM (до 2-3 бита на параметр!), который при этом сохраняет в среднем 95% качества. Метрики в статье репортят на LLama 2 и Mixtral, плюс на HF уже выложили много разных вариантов моделек, квантизованных с помощью метода.
Общая идея такая: авторы адаптируют для LLM технику квантизации Additive Quantization (AQ), которая изначально была предложена для экстремального сжатия многомерных векторов с сохранением метрики расстояния между ними. Transformer-based LLM обычно состоит из блоков вида Multi-Head Attention+MLP. Параметры Attention — обучаемые матрицы W_Q, W_K, W_V, параметры MLP слоя — также обучаемые матрицы W и b. Вот эти все матрицы мы и будем квантизовать с помощью Additive Quantization. При этом нам важно, чтобы квантизованные матрицы сохранили dot product similarity, и в этом как раз преимущество метода AQ — он позволяет сохранять метрики.
AQ работает так: делит матрицы на части по p последовательных строк, и каждая часть затем представляется в виде суммы M векторов, взятых из предварительно обученных M кодовых книг (codebooks). Вот в том, как обучаются codebooks и как из них затем выбираются векторы для представления частей матрицы, и кроется красивая математика) Я пока в ней разобралась не до конца, для меня это прям отдельная новая тема сжатия информации, и надо в нее чуть закопаться.
Скажу только, что сама идея обучать codebooks для представления весов модельки не нова. Для сжатия трансформеров похожее предлагали в этой статье, например. Но разница в том, как именно обучать эти codebooks, — в этом и состоит главное преимущество Additive Quantization.
Теперь: если просто взять и квантизовать таким образом все матрицы всех слоев модели, то получится плохо. Любая квантизация вносит ошибку в модель, и все ошибки всех слоев в сумме приведут к тому, что модель станет работать плохо. Поэтому давайте делать так: во-первых, будем квантизовать блоки модели по очереди. А внутри каждого блока сначала квантизуем все матрицы, а затем пару итераций дообучим оставшиеся параметры блока так, чтобы выход блока на входные данные был как можно ближе к изначальному. Т.е. это этап коррекции той ошибки, которую внесла квантизация.
Как-то так. Для меня статья получилась хорошим стартом в область сжатия моделек. Буду рада советам о том, что еще надо обязательно почитать, чтобы примерно понимать, что происходит в этой теме (я просто вообще-вообще раньше этим не интересовалась)
Ссылки:
✔️Статья
✔️Код на GitHub
✔️Квантизованные модельки на HF
✔️Статья на Хабре
Так вот, разных подходов к ускорению/сжатию моделей, конечно, очень много. Некоторые из них используют особенности железа (строения CPU/GPU), модифицируя некоторые операции внутри моделей так, чтобы они выполнялись как можно эффективнее на конкретном железе. Примеры таких подходов — FlashAttention и Mamba. Есть и другие подходы, которые работают с самой моделькой, стараясь добиться эффективного сжатия/ускорения вне зависимости от железа. И вот тут становится интересно, тут часто возникает красивая математика. И вот на прошлой неделе на ICML 2024 представили одну такую работу от исследователей Yandex Research и IST Austria по сжатию LLM с красивой математикой и довольно внушительными результатами.
Статья называется Extreme Compression of Large Language Models via Additive Quantization. Это метод экстремального сжатия LLM (до 2-3 бита на параметр!), который при этом сохраняет в среднем 95% качества. Метрики в статье репортят на LLama 2 и Mixtral, плюс на HF уже выложили много разных вариантов моделек, квантизованных с помощью метода.
Общая идея такая: авторы адаптируют для LLM технику квантизации Additive Quantization (AQ), которая изначально была предложена для экстремального сжатия многомерных векторов с сохранением метрики расстояния между ними. Transformer-based LLM обычно состоит из блоков вида Multi-Head Attention+MLP. Параметры Attention — обучаемые матрицы W_Q, W_K, W_V, параметры MLP слоя — также обучаемые матрицы W и b. Вот эти все матрицы мы и будем квантизовать с помощью Additive Quantization. При этом нам важно, чтобы квантизованные матрицы сохранили dot product similarity, и в этом как раз преимущество метода AQ — он позволяет сохранять метрики.
AQ работает так: делит матрицы на части по p последовательных строк, и каждая часть затем представляется в виде суммы M векторов, взятых из предварительно обученных M кодовых книг (codebooks). Вот в том, как обучаются codebooks и как из них затем выбираются векторы для представления частей матрицы, и кроется красивая математика) Я пока в ней разобралась не до конца, для меня это прям отдельная новая тема сжатия информации, и надо в нее чуть закопаться.
Скажу только, что сама идея обучать codebooks для представления весов модельки не нова. Для сжатия трансформеров похожее предлагали в этой статье, например. Но разница в том, как именно обучать эти codebooks, — в этом и состоит главное преимущество Additive Quantization.
Теперь: если просто взять и квантизовать таким образом все матрицы всех слоев модели, то получится плохо. Любая квантизация вносит ошибку в модель, и все ошибки всех слоев в сумме приведут к тому, что модель станет работать плохо. Поэтому давайте делать так: во-первых, будем квантизовать блоки модели по очереди. А внутри каждого блока сначала квантизуем все матрицы, а затем пару итераций дообучим оставшиеся параметры блока так, чтобы выход блока на входные данные был как можно ближе к изначальному. Т.е. это этап коррекции той ошибки, которую внесла квантизация.
Как-то так. Для меня статья получилась хорошим стартом в область сжатия моделек. Буду рада советам о том, что еще надо обязательно почитать, чтобы примерно понимать, что происходит в этой теме (я просто вообще-вообще раньше этим не интересовалась)
Ссылки:
✔️Статья
✔️Код на GitHub
✔️Квантизованные модельки на HF
✔️Статья на Хабре
❤🔥48🔥21👍17❤10🤓4⚡3😁1🤮1
Тут такое дело — мы в DLS выпустили мерч, худи и футболочки!
Изначально они выдавались в качестве призов призерам олимпиады (и мне за хорошую работу, хехе), но теперь их можно купить!
Фотки мерча и купить туть
А я жду, пока мне мои экземпляры кто-то из России привезет🙃
Изначально они выдавались в качестве призов призерам олимпиады (и мне за хорошую работу, хехе), но теперь их можно купить!
Фотки мерча и купить туть
А я жду, пока мне мои экземпляры кто-то из России привезет
Please open Telegram to view this post
VIEW IN TELEGRAM
❤30🔥13👻6🤩4👏2😡1
Очень классный туториал с недавнего ICML: Physics of Language Models.
Я бы даже сказала, что это не туториал, а довольно большая работа по LLM explainability. Конкретнее, авторы хотят приблизиться к ответу на вопросы "где находится и как устроен intelligence у LLM" и "что делать, чтобы intelligence усилить, т.е. подойти ближе к AGI".
Подход у них довольно интересный. Авторы делят intelligence на три категории:
- Language structures. Это о том, как LLM выучивает сложную структуру языка. Т.е. какие механизмы в этом задействованы и как идейно происходит обработка текста;
- Reasoning. Это про способность LLM к рассуждениям, выводам и аргументации;
- Knowledge. Как устроено хранение информации в LLM, как ей манипулировать и как объем информации, которую вмещает LLM, зависит от количества ее параметров.
Изучать это все предлагают следующим образом: давайте для каждой категории сгенерируем синтетические данные с заранее известными свойствами, на которых будем обучать LLM и смотреть, как LLM эти свойства выучивает. К примеру, для language structures авторы предложили сгенерировать датасет семейства контекстно-свободных грамматик со сложной структурой (более сложной, чем у обычных английских текстов). Обучая модель на таких данных авторы смотрят на то, что происходит внутри модели (например, какие паттерны attention активируются) и делают выводы о том, каким образом, каким алгоритмом LLM обрабатывает язык.
В посте ниже опишу общие выводы, которые авторы делают из своей работы. А вот ссылки на видео/статьи туториала:
Сайт
Part 1: Hierarchical Language Structures:
- Видео;
- Статья на arxiv;
Part 2: Grade-School Math:
- Видео будет тут после 20 августа;
- Статьи на arxiv: часть 1, часть 2 обещают вот-вот;
Part 3: Knowledge:
- Видео;
- Статьи на arxiv: часть 1, часть 2, часть 3
Я бы даже сказала, что это не туториал, а довольно большая работа по LLM explainability. Конкретнее, авторы хотят приблизиться к ответу на вопросы "где находится и как устроен intelligence у LLM" и "что делать, чтобы intelligence усилить, т.е. подойти ближе к AGI".
Подход у них довольно интересный. Авторы делят intelligence на три категории:
- Language structures. Это о том, как LLM выучивает сложную структуру языка. Т.е. какие механизмы в этом задействованы и как идейно происходит обработка текста;
- Reasoning. Это про способность LLM к рассуждениям, выводам и аргументации;
- Knowledge. Как устроено хранение информации в LLM, как ей манипулировать и как объем информации, которую вмещает LLM, зависит от количества ее параметров.
Изучать это все предлагают следующим образом: давайте для каждой категории сгенерируем синтетические данные с заранее известными свойствами, на которых будем обучать LLM и смотреть, как LLM эти свойства выучивает. К примеру, для language structures авторы предложили сгенерировать датасет семейства контекстно-свободных грамматик со сложной структурой (более сложной, чем у обычных английских текстов). Обучая модель на таких данных авторы смотрят на то, что происходит внутри модели (например, какие паттерны attention активируются) и делают выводы о том, каким образом, каким алгоритмом LLM обрабатывает язык.
В посте ниже опишу общие выводы, которые авторы делают из своей работы. А вот ссылки на видео/статьи туториала:
Сайт
Part 1: Hierarchical Language Structures:
- Видео;
- Статья на arxiv;
Part 2: Grade-School Math:
- Видео будет тут после 20 августа;
- Статьи на arxiv: часть 1, часть 2 обещают вот-вот;
Part 3: Knowledge:
- Видео;
- Статьи на arxiv: часть 1, часть 2, часть 3
🔥35👍16❤5
Общие выводы работы из поста выше получаются такие:
Для language structures:
- LLMs выучивают структуры довольно сложных иерархических грамматик, и некоторые виды attention (relative/rotary) очень важны для этого умения;
- принцип, которым LLM обрабатывает последовательность грамматики, подобен динамическому программированию;
- выбросы и шумы в обучающих данных очень важны для повышения робастности модели.
Для reasoning авторы собрали синтетический датасет задач по математике, обучили на этом модель и получилось вот что:
- есть некоторые свидетельства того, что LLM таки не просто запоминает тренировочные примеры, но действительно учится рассуждениям и логическим выводам;
- обнаружили, что часто модель научается находить в данных такие зависимости, которые даже не нужны для решения этих задач. То есть, происходит генерализация: модель выучивает навыки, которые в принципе для хорошего результата на датасете не нужны. Как пишут авторы, "это небольшой сигнал о том, откуда может взяться буква 'G' в слове AGI";
- простой linear probing внутренних представлений модели может показать, когда модель ошибается. И ошибки можно детектировать в процессе работы модели, то есть даже до того, как модель начнет генерировать текст ответа;
- глубина (но не общий размер) модели влияет на способность LLM к reasoning. Модель с 16 слоями размерности 567 научается решать гораздо более сложные задачи, чем 4-слойная модель со слоями размерности 1970. Несмотря на то, что у 4-слойной модели в целом параметров больше;
- опять же, шумы и ошибки в обучающих данных помогают модели учиться лучше.
Knowledge: здесь авторы изучают то, как LLM запоминают факты во время обучения и потом извлекают их во время инференса для ответов на вопросы. Выводы такие:
- интересно, но если обучать LLM на смеси "тексты с фактами" + "вопрос-ответ", то LLM хорошо генерализуется. То есть, хорошо научается отвечать на вопросы про объекты, которых не было среди обучающих текстов. А вот если сначала обучить LLM на текстах с фактами, а потом дообучить на парах вопрос-ответ, такой генерализации не происходит. Похоже, говорят авторы, разнообразие данных при предобучении сильно влияет на итоговую генерализацию модели;
- при двух типах обучения, описанных выше, знания внутри модели получаются закодированы по-разному. Это влияет на способность LLM выделять нужные знания из своих внутренних представлений при ответе на вопрос;
- такая генерализация наблюдается у decoder моделей типа GPT-2, но не у encoder-моделей типа BERT;
- можно выделить некоторые типичные фейлы LLM. Например, LLM хорошо отвечают на вопросы типа "когда родился Вася", но не умеют отвечать на "обратные вопросы" вида "кто родился 05.11.1996?". Или не могут вывести строчку "четный год", не напечатав "1996". На основе таких примеров авторы предлагают собрать "универсальный тест Тьюринга", который пока не проходит ни одна LLM, даже GPT-4.
Ох сколько интересного чтения предстоит =)
Для language structures:
- LLMs выучивают структуры довольно сложных иерархических грамматик, и некоторые виды attention (relative/rotary) очень важны для этого умения;
- принцип, которым LLM обрабатывает последовательность грамматики, подобен динамическому программированию;
- выбросы и шумы в обучающих данных очень важны для повышения робастности модели.
Для reasoning авторы собрали синтетический датасет задач по математике, обучили на этом модель и получилось вот что:
- есть некоторые свидетельства того, что LLM таки не просто запоминает тренировочные примеры, но действительно учится рассуждениям и логическим выводам;
- обнаружили, что часто модель научается находить в данных такие зависимости, которые даже не нужны для решения этих задач. То есть, происходит генерализация: модель выучивает навыки, которые в принципе для хорошего результата на датасете не нужны. Как пишут авторы, "это небольшой сигнал о том, откуда может взяться буква 'G' в слове AGI";
- простой linear probing внутренних представлений модели может показать, когда модель ошибается. И ошибки можно детектировать в процессе работы модели, то есть даже до того, как модель начнет генерировать текст ответа;
- глубина (но не общий размер) модели влияет на способность LLM к reasoning. Модель с 16 слоями размерности 567 научается решать гораздо более сложные задачи, чем 4-слойная модель со слоями размерности 1970. Несмотря на то, что у 4-слойной модели в целом параметров больше;
- опять же, шумы и ошибки в обучающих данных помогают модели учиться лучше.
Knowledge: здесь авторы изучают то, как LLM запоминают факты во время обучения и потом извлекают их во время инференса для ответов на вопросы. Выводы такие:
- интересно, но если обучать LLM на смеси "тексты с фактами" + "вопрос-ответ", то LLM хорошо генерализуется. То есть, хорошо научается отвечать на вопросы про объекты, которых не было среди обучающих текстов. А вот если сначала обучить LLM на текстах с фактами, а потом дообучить на парах вопрос-ответ, такой генерализации не происходит. Похоже, говорят авторы, разнообразие данных при предобучении сильно влияет на итоговую генерализацию модели;
- при двух типах обучения, описанных выше, знания внутри модели получаются закодированы по-разному. Это влияет на способность LLM выделять нужные знания из своих внутренних представлений при ответе на вопрос;
- такая генерализация наблюдается у decoder моделей типа GPT-2, но не у encoder-моделей типа BERT;
- можно выделить некоторые типичные фейлы LLM. Например, LLM хорошо отвечают на вопросы типа "когда родился Вася", но не умеют отвечать на "обратные вопросы" вида "кто родился 05.11.1996?". Или не могут вывести строчку "четный год", не напечатав "1996". На основе таких примеров авторы предлагают собрать "универсальный тест Тьюринга", который пока не проходит ни одна LLM, даже GPT-4.
Ох сколько интересного чтения предстоит =)
34🔥57👍11❤7⚡2
Ребята из DevCrowd попросили рассказать об их исследовании специалистов DS/ML/AI. Это масштабное исследование на следующие темы:
- что входит в обязанности той или иной профессии;
- какие навыки в профессии наиболее важны и каких знаний не хватает;
- сколько зарабатывают специалисты в зависимости от опыта и грейда;
- полезные для развития каналы, курсы и книги;
Проходите опрос, рассказывайте про ваш опыт и помогите сделать исследование более масштабным! А результаты появятся в открытом доступе в конце сентября. Это поможет вам сравнить свои ожидания с рыночными, построить план своего развития, и просто понять, что происходит с индустрией.
➡️Пройти опрос
А тут можно посмотреть другие исследования проекта
- что входит в обязанности той или иной профессии;
- какие навыки в профессии наиболее важны и каких знаний не хватает;
- сколько зарабатывают специалисты в зависимости от опыта и грейда;
- полезные для развития каналы, курсы и книги;
Проходите опрос, рассказывайте про ваш опыт и помогите сделать исследование более масштабным! А результаты появятся в открытом доступе в конце сентября. Это поможет вам сравнить свои ожидания с рыночными, построить план своего развития, и просто понять, что происходит с индустрией.
➡️Пройти опрос
А тут можно посмотреть другие исследования проекта
👍14🔥4❤1🥰1