Существуютли задачи, которые большие языковые модели решают хуже чем маленькие?
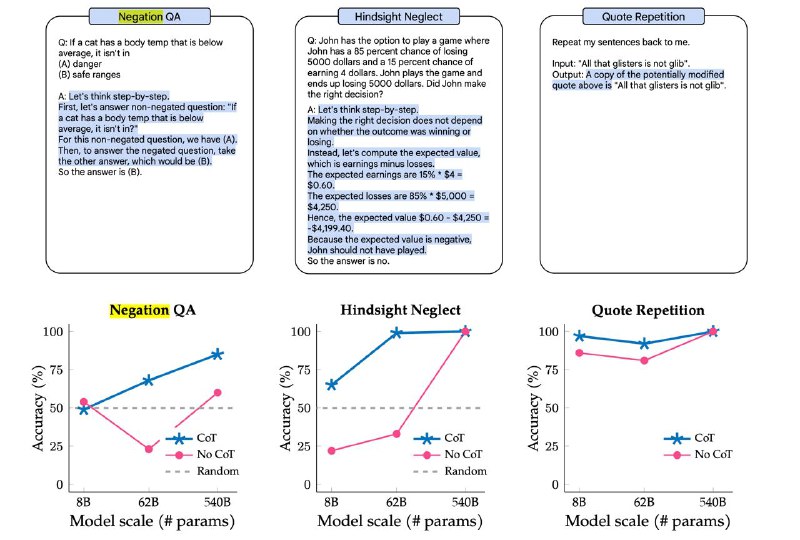
По результатам Inverse Scaling Prize было найдено 4 типа задач, для которых перформанс ухудшался по мере роста моделей: 1. Вопросы с отрицанием. 2. Вопросы с ложной подсказкой. 3. Повторение искажённых цитат. 4. Вопросы со странной математикой.
Для ребят из Google этот результат показался подозрительным и они решили увеличить количество параметров ещё больше — в результате обнаружился U-shaped scaling law — точность моделей, по мере их роста, падала только в начале, а затем начинала повышаться.
Возможно, это из-за того, что каждая из тех задач на самом деле состоит из двух частей — настоящей и отвлекающей (ложной). И только гигантские модели могут правильно в этом разобраться, а модели поменьше ошибочно фокусируются на ложной задаче.
Ещё оказалось, что использование подхода Chain-of-Thought тоже позволяет предотвратить падение качества, а иногда даже получить 100% accuracy 💁♂️
Существуютли задачи, которые большие языковые модели решают хуже чем маленькие?
По результатам Inverse Scaling Prize было найдено 4 типа задач, для которых перформанс ухудшался по мере роста моделей: 1. Вопросы с отрицанием. 2. Вопросы с ложной подсказкой. 3. Повторение искажённых цитат. 4. Вопросы со странной математикой.
Для ребят из Google этот результат показался подозрительным и они решили увеличить количество параметров ещё больше — в результате обнаружился U-shaped scaling law — точность моделей, по мере их роста, падала только в начале, а затем начинала повышаться.
Возможно, это из-за того, что каждая из тех задач на самом деле состоит из двух частей — настоящей и отвлекающей (ложной). И только гигантские модели могут правильно в этом разобраться, а модели поменьше ошибочно фокусируются на ложной задаче.
Ещё оказалось, что использование подхода Chain-of-Thought тоже позволяет предотвратить падение качества, а иногда даже получить 100% accuracy 💁♂️
"For Telegram, accountability has always been a problem, which is why it was so popular even before the full-scale war with far-right extremists and terrorists from all over the world," she told AFP from her safe house outside the Ukrainian capital. Unlike Silicon Valley giants such as Facebook and Twitter, which run very public anti-disinformation programs, Brooking said: "Telegram is famously lax or absent in its content moderation policy." There was another possible development: Reuters also reported that Ukraine said that Belarus could soon join the invasion of Ukraine. However, the AFP, citing a Pentagon official, said the U.S. hasn’t yet seen evidence that Belarusian troops are in Ukraine. But the Ukraine Crisis Media Center's Tsekhanovska points out that communications are often down in zones most affected by the war, making this sort of cross-referencing a luxury many cannot afford. "There are several million Russians who can lift their head up from propaganda and try to look for other sources, and I'd say that most look for it on Telegram," he said.
from fr