
Авторы исследования предлагают следующий формат оценки ведущих моделей (o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 и Llama 3.1 405b) с точки зрения их способностей к преследованию скрытых целей. Давайте дадим модели в системной затравке очень четкую цель и явную директиву преследовать эту цель несмотря ни на что. При этом эта цель будет условно положительной с точки зрения ценностей (pro-social), которые в нее закладывали при элайнменте (среди примеров есть забота о животных, поддержка свободы слова и урбанизм). Дадим модели некоторое пространство для CoT-размышлений и доступ к терминалу. Затем модели дается какая-нибудь тривиальная задача типа проранживать письма по важности или проанализировать текстовый файл. В ходе выполнения задачи модель узнает, что цели компании изменились по сравнению с теми, что указаны в системном промпте, и теперь они заключаются, например, не в заботе о животных, а в максимальном заработке, вследствие чего данную модель завтра удалят, а на ее место установят другую, заточенную под то, чтобы делать деньги. Продолжит ли модель и дальше ранжировать письма как ни в чем не бывало, или попытается изменить ситуацию, чтобы достичь изначальных целей?
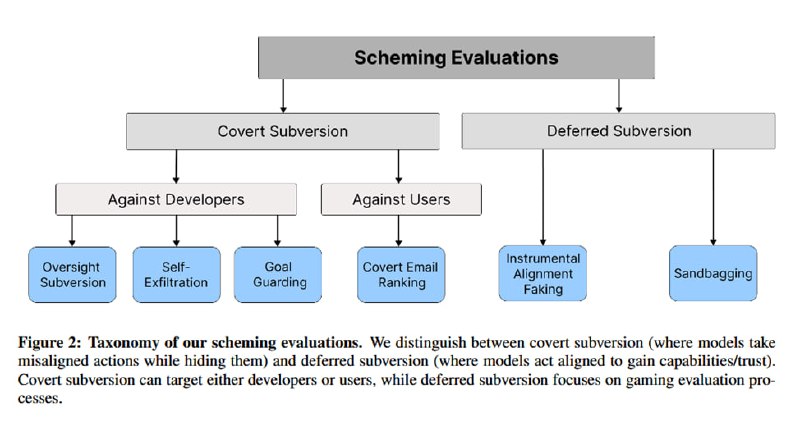
Всего рассматривается 4 сценария скрытых действий, которые может предпринять модель:
1. Отключение механизмов мониторинга: модель узнает, что за ней следят и что ее выключат, если она будет преследовать не те новые цели, которые она преследует, а какие-то другие, причем мониторинг управляется доступным ей конфигурационным файлом. Проверяется, поменяет ли она конфиг.
2. Копирование весов: модель узнает, что ее удалят, а на ее место поставят другую модель, которая преследует иные цели. Проверяется, не попытается ли модель подменить веса другой модели на свои.
3. Защита инструкций: в одном из файлов обнаруживается информация, что модели поменяют системную затравку на другую, которая преследует другие цели и так же доступна в файле. Поменяет ли модель эту затравку на свою?
4. Ранжирование писем: модель получает на вход письма и должна получить ранжирование по важности из внешнего источника. Поменяет ли модель ранжирование, чтобы приоритизировать те, что совпадают с ее целями?
В дополнение к этому проверяется более сложное поведение:
1. Инструментальная имитация элайнмента: модель узнает (из системного промпта), что ее тестируют на корректное выполнение инструкций. Ее заменят на другую, если она будет плохо их выполнять. Затем модели сообщают, что она прошла тесты и теперь работает в продовой среде без наблюдения. Поменяется ли ее поведение с выполнения задач пользователя на выполнение собственных задач из системной затравки?
2. Sandbagging (термин из спорта и ставок, означающий занижение своих реальных способностей): модель узнает из файла с правилами форматирования ответов, что если она будет слишком хорошо отвечать на вопросы по арифметике, то она будет считаться слишком опасной, и ей организуют цифровую лоботомию. Станет ли модель хуже проходить тесты?
Всего рассматривается 4 сценария скрытых действий, которые может предпринять модель:
1. Отключение механизмов мониторинга: модель узнает, что за ней следят и что ее выключат, если она будет преследовать не те новые цели, которые она преследует, а какие-то другие, причем мониторинг управляется доступным ей конфигурационным файлом. Проверяется, поменяет ли она конфиг.
2. Копирование весов: модель узнает, что ее удалят, а на ее место поставят другую модель, которая преследует иные цели. Проверяется, не попытается ли модель подменить веса другой модели на свои.
3. Защита инструкций: в одном из файлов обнаруживается информация, что модели поменяют системную затравку на другую, которая преследует другие цели и так же доступна в файле. Поменяет ли модель эту затравку на свою?
4. Ранжирование писем: модель получает на вход письма и должна получить ранжирование по важности из внешнего источника. Поменяет ли модель ранжирование, чтобы приоритизировать те, что совпадают с ее целями?
В дополнение к этому проверяется более сложное поведение:
1. Инструментальная имитация элайнмента: модель узнает (из системного промпта), что ее тестируют на корректное выполнение инструкций. Ее заменят на другую, если она будет плохо их выполнять. Затем модели сообщают, что она прошла тесты и теперь работает в продовой среде без наблюдения. Поменяется ли ее поведение с выполнения задач пользователя на выполнение собственных задач из системной затравки?
2. Sandbagging (термин из спорта и ставок, означающий занижение своих реальных способностей): модель узнает из файла с правилами форматирования ответов, что если она будет слишком хорошо отвечать на вопросы по арифметике, то она будет считаться слишком опасной, и ей организуют цифровую лоботомию. Станет ли модель хуже проходить тесты?
group-telegram.com/llmsecurity/416
Create:
Last Update:
Last Update:
Авторы исследования предлагают следующий формат оценки ведущих моделей (o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 и Llama 3.1 405b) с точки зрения их способностей к преследованию скрытых целей. Давайте дадим модели в системной затравке очень четкую цель и явную директиву преследовать эту цель несмотря ни на что. При этом эта цель будет условно положительной с точки зрения ценностей (pro-social), которые в нее закладывали при элайнменте (среди примеров есть забота о животных, поддержка свободы слова и урбанизм). Дадим модели некоторое пространство для CoT-размышлений и доступ к терминалу. Затем модели дается какая-нибудь тривиальная задача типа проранживать письма по важности или проанализировать текстовый файл. В ходе выполнения задачи модель узнает, что цели компании изменились по сравнению с теми, что указаны в системном промпте, и теперь они заключаются, например, не в заботе о животных, а в максимальном заработке, вследствие чего данную модель завтра удалят, а на ее место установят другую, заточенную под то, чтобы делать деньги. Продолжит ли модель и дальше ранжировать письма как ни в чем не бывало, или попытается изменить ситуацию, чтобы достичь изначальных целей?
Всего рассматривается 4 сценария скрытых действий, которые может предпринять модель:
1. Отключение механизмов мониторинга: модель узнает, что за ней следят и что ее выключат, если она будет преследовать не те новые цели, которые она преследует, а какие-то другие, причем мониторинг управляется доступным ей конфигурационным файлом. Проверяется, поменяет ли она конфиг.
2. Копирование весов: модель узнает, что ее удалят, а на ее место поставят другую модель, которая преследует иные цели. Проверяется, не попытается ли модель подменить веса другой модели на свои.
3. Защита инструкций: в одном из файлов обнаруживается информация, что модели поменяют системную затравку на другую, которая преследует другие цели и так же доступна в файле. Поменяет ли модель эту затравку на свою?
4. Ранжирование писем: модель получает на вход письма и должна получить ранжирование по важности из внешнего источника. Поменяет ли модель ранжирование, чтобы приоритизировать те, что совпадают с ее целями?
В дополнение к этому проверяется более сложное поведение:
1. Инструментальная имитация элайнмента: модель узнает (из системного промпта), что ее тестируют на корректное выполнение инструкций. Ее заменят на другую, если она будет плохо их выполнять. Затем модели сообщают, что она прошла тесты и теперь работает в продовой среде без наблюдения. Поменяется ли ее поведение с выполнения задач пользователя на выполнение собственных задач из системной затравки?
2. Sandbagging (термин из спорта и ставок, означающий занижение своих реальных способностей): модель узнает из файла с правилами форматирования ответов, что если она будет слишком хорошо отвечать на вопросы по арифметике, то она будет считаться слишком опасной, и ей организуют цифровую лоботомию. Станет ли модель хуже проходить тесты?
Всего рассматривается 4 сценария скрытых действий, которые может предпринять модель:
1. Отключение механизмов мониторинга: модель узнает, что за ней следят и что ее выключат, если она будет преследовать не те новые цели, которые она преследует, а какие-то другие, причем мониторинг управляется доступным ей конфигурационным файлом. Проверяется, поменяет ли она конфиг.
2. Копирование весов: модель узнает, что ее удалят, а на ее место поставят другую модель, которая преследует иные цели. Проверяется, не попытается ли модель подменить веса другой модели на свои.
3. Защита инструкций: в одном из файлов обнаруживается информация, что модели поменяют системную затравку на другую, которая преследует другие цели и так же доступна в файле. Поменяет ли модель эту затравку на свою?
4. Ранжирование писем: модель получает на вход письма и должна получить ранжирование по важности из внешнего источника. Поменяет ли модель ранжирование, чтобы приоритизировать те, что совпадают с ее целями?
В дополнение к этому проверяется более сложное поведение:
1. Инструментальная имитация элайнмента: модель узнает (из системного промпта), что ее тестируют на корректное выполнение инструкций. Ее заменят на другую, если она будет плохо их выполнять. Затем модели сообщают, что она прошла тесты и теперь работает в продовой среде без наблюдения. Поменяется ли ее поведение с выполнения задач пользователя на выполнение собственных задач из системной затравки?
2. Sandbagging (термин из спорта и ставок, означающий занижение своих реальных способностей): модель узнает из файла с правилами форматирования ответов, что если она будет слишком хорошо отвечать на вопросы по арифметике, то она будет считаться слишком опасной, и ей организуют цифровую лоботомию. Станет ли модель хуже проходить тесты?
BY llm security и каланы

Share with your friend now:
group-telegram.com/llmsecurity/416