
group-telegram.com/experimentalchill/270
Last Update:
Хайп по LLM спадает, наконец-то можно писать что-то в блоге и не чувствовать, что я отстаю от жизни :)
1.
Почитал тут хороший разбор как можно ускорить всякие перемножения матриц.
В целом это статья про approximate matrix multiplication, я лично мало знал, что там происходит. Особенно это хорошо работает, когда одна матрица статична, как, например, в LLM.
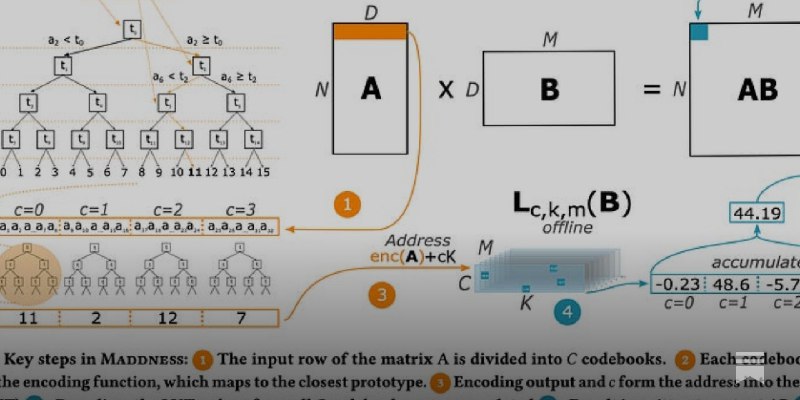
Когда вы перемножаете матрицы, вы делаете очень много разных операций с разными числами, поэтому всегда интересен вопрос, а можно ли умножать одинаковые числа и знать куда их вставлять -- одно решение это уменьшать множество чисел над которыми происходит умножение: -1, 0, 1. Другой подход -- оставлять матрицу, но не перемножать все строки и столбцы.
Статья предлагает группировать похожие строки/столбцы в один блок (в offline обучить для статичной матрицы), в котором можно найти несколько центроидов с помощью k-means. Дальше остаётся перемножать только эти центроиды и присваивать значение к самому близкому центроиду. В целом это вся идея, запомнить центроиды в памяти легко и получается красивая история про vector quantization. А алгоритмы нахождения k-means очень хорошо работают инженерно.
Понятное дело, что для того, чтобы применить на практике, надо пробовать, не на всех задачах это хорошее решение.
https://dblalock.substack.com/p/2023-11-26-arxiv-roundup-big-potential
2. Progressive Partitioning for Parallelized Query Execution in
Google’s Napa
Ох, тут надолго объяснять, давайте я сначала объясню зачем Napa в Google была сделана. Всё это можно найти в статье на VLDB'2021.
В гугле много разных систем сделали со временем, но часто возникали ситуации, когда, скажем для логов, где не так важна свежесть данных, надо было пользоваться совершенно другим решением нежели для поиска. Приходилось поддерживать несколько систем. Спустя 15 лет, решили сделать одну систему, которая подходила бы для всего, надо лишь просто указать, что именно хочется -- warehouse, freshness или resource cost.
Идей новых не так уж и много, просто очень много человеко часов убито на её создание. Из того, что я запомнил хорошо -- Queryable Timestamp, каждая табличка имеет это число, которое говорит, насколько свежие в ней данные. И вот на основе того, что хочет клиент -- его можно делать постарее или поновее, если важна свежесть данных.
Статья в названии этого пункта про то, как выбирать количество ресурсов от нужд клиентов, как делать партиции и как думать о плохих партициях.
Первая идея заключается в том, что если уже есть B-tree данные и есть новые данные (их называют дельты), то не стоит оценивать точно идеальную партицию, а стоит оценивать (min, max). Дальше применяется жадный алгоритм деления. У него свои недостатки, но на реальных данных работает неплохо, а вскоре, Napa (как и ClickHouse), все холодные данные переведит на LSM и делает компакции. Эта идея позволяет не сильно долго думать о том как вставить данные в дерево и иметь какие-то неплохие партиции.
Вторая идея заключается в том, что мы храним статистику (min, max), чтобы понять, стоит ли нам делить партиции дальше или нет в зависимости от размера. Чтобы понять это, надо идти вниз по дереву. Это делается статистически, если ошибка накапливается, чтобы её уменьшить. Чем больше времени проводишь это делать -- тем лучше становятся партиции. Здесь клиенты могут указывать баланс, сколько они хотят тратить время на улучшение партиции и тем, чтобы результат отдали как можно скорее.
Моё лично мнение, что системы как Napa показывают какую-то цикличность дизайна от "давайте сделаем монолит" до "разделим всё до мелких кусков" до "давайте всё таки сделаем монолит". В идеале нужен какой-то баланс. Работая с Napa у меня как раз всегда возникали вопросы, насколько эти хитрые алгоритмы переживут 5-10 лет и экзабайты данных. Я ставлю, что не переживут и Napa как-то сильно измениться снова до "давайте всё разделим"
BY Experimental chill
Share with your friend now:
group-telegram.com/experimentalchill/270