Qwen-7B: Alibaba зарелизилисвою опен-соурсную LLM на 7B параметров
Qwen-7B натренили на 2.2 трлн токенов, размер контекста во вреия тренировки был 2048, а на тесте можно впихнуть до 8192 (у Llama-2 - 4096). Это первая открытая LLM от Alibaba.
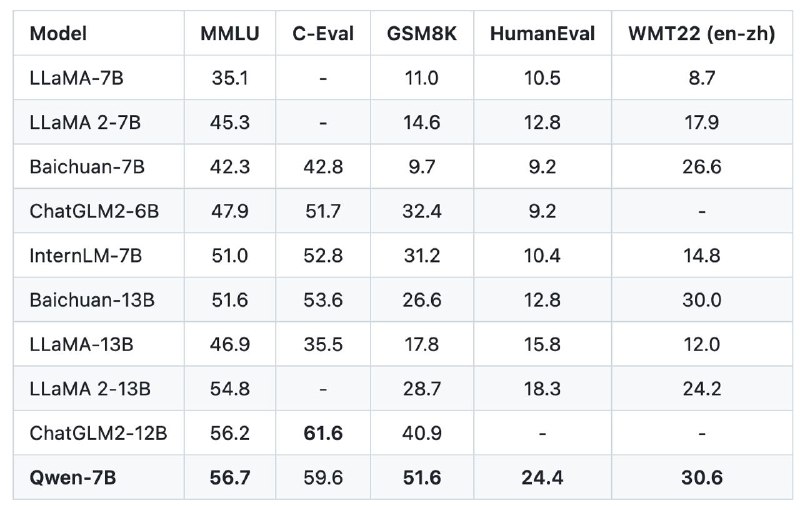
Что по бенчмаркам? В репе есть куча таблиц, и китайцы заявляют, что они бьют LLama-2. Особенно большая разница на бенчмарке по написанию кода Human-Eval: 24.4 vs 12.8. Но я бы осторожно смотрел на эти числа. Если по некоторым бенчмаркам Qwen-7B обходит ванильную LLama-2-7B, и даже LLaMA-2-13B, то вот с зафайнтюнеными версиями Llama-2 разрыв уже не такой большой. И, честно сказать, никто точно не знает, как они трениновали свою базовую модель.
По аналогии с LLaMa2-chat, у Qwen тоже есть чатовая версия Qwen-7B-Chat, которая затюнена отвечать на запросы пользователя и, кроме того, пользоваться разными тулами и API.
Для любителей деталей, архитектура похожа на LLaMA. Со следующими различиями:
> The following are the main differences from the standard transformer: 1) using untied embedding, 2) using rotary positional embedding, 3) no biases except for QKV in attention, 4) RMSNorm instead of LayerNorm, 5) SwiGLU instead of ReLU, and 6) adopting flash attention to accelerate training. The model has 32 layers, the embedding dimension is 4096, and the number of attention heads is 32.
Лицензия тоже как у Llama-2: Можно использовать в коммерчески целях, но только пока у вас нет 100 млн активных пользователей в месяц (у Llama-2 можно до 700 млн).
Больше деталей в этом репорте (да, это тупо .md файл в репозитории).
Qwen-7B: Alibaba зарелизилисвою опен-соурсную LLM на 7B параметров
Qwen-7B натренили на 2.2 трлн токенов, размер контекста во вреия тренировки был 2048, а на тесте можно впихнуть до 8192 (у Llama-2 - 4096). Это первая открытая LLM от Alibaba.
Что по бенчмаркам? В репе есть куча таблиц, и китайцы заявляют, что они бьют LLama-2. Особенно большая разница на бенчмарке по написанию кода Human-Eval: 24.4 vs 12.8. Но я бы осторожно смотрел на эти числа. Если по некоторым бенчмаркам Qwen-7B обходит ванильную LLama-2-7B, и даже LLaMA-2-13B, то вот с зафайнтюнеными версиями Llama-2 разрыв уже не такой большой. И, честно сказать, никто точно не знает, как они трениновали свою базовую модель.
По аналогии с LLaMa2-chat, у Qwen тоже есть чатовая версия Qwen-7B-Chat, которая затюнена отвечать на запросы пользователя и, кроме того, пользоваться разными тулами и API.
Для любителей деталей, архитектура похожа на LLaMA. Со следующими различиями:
> The following are the main differences from the standard transformer: 1) using untied embedding, 2) using rotary positional embedding, 3) no biases except for QKV in attention, 4) RMSNorm instead of LayerNorm, 5) SwiGLU instead of ReLU, and 6) adopting flash attention to accelerate training. The model has 32 layers, the embedding dimension is 4096, and the number of attention heads is 32.
Лицензия тоже как у Llama-2: Можно использовать в коммерчески целях, но только пока у вас нет 100 млн активных пользователей в месяц (у Llama-2 можно до 700 млн).
Больше деталей в этом репорте (да, это тупо .md файл в репозитории).
The War on Fakes channel has repeatedly attempted to push conspiracies that footage from Ukraine is somehow being falsified. One post on the channel from February 24 claimed without evidence that a widely viewed photo of a Ukrainian woman injured in an airstrike in the city of Chuhuiv was doctored and that the woman was seen in a different photo days later without injuries. The post, which has over 600,000 views, also baselessly claimed that the woman's blood was actually makeup or grape juice. "And that set off kind of a battle royale for control of the platform that Durov eventually lost," said Nathalie Maréchal of the Washington advocacy group Ranking Digital Rights. Official government accounts have also spread fake fact checks. An official Twitter account for the Russia diplomatic mission in Geneva shared a fake debunking video claiming without evidence that "Western and Ukrainian media are creating thousands of fake news on Russia every day." The video, which has amassed almost 30,000 views, offered a "how-to" spot misinformation. Telegram does offer end-to-end encrypted communications through Secret Chats, but this is not the default setting. Standard conversations use the MTProto method, enabling server-client encryption but with them stored on the server for ease-of-access. This makes using Telegram across multiple devices simple, but also means that the regular Telegram chats you’re having with folks are not as secure as you may believe. On Telegram’s website, it says that Pavel Durov “supports Telegram financially and ideologically while Nikolai (Duvov)’s input is technological.” Currently, the Telegram team is based in Dubai, having moved around from Berlin, London and Singapore after departing Russia. Meanwhile, the company which owns Telegram is registered in the British Virgin Islands.
from ms

{kind=link}