
ARC Benchmark
Многие бенчмарки (то есть наборы данных с размеченными ожидаемыми ответами, признанные прокси-оценками качества) для LLM справедливо можно критиковать за то, что они по сути тестируют запоминание. Самый простой пример — бенчмарки вопросов-ответов (или тестов с опциями ответа, но не все): чтобы ответить на вопрос «в каком году было то и то?» не нужно быть гением мысли или обладать выдающимся интеллектом. Достаточно просто запомнить факт.
По мере усложнения задач в какой-то момент мы натыкаемся на дилемму — что является запоминанием, а что рассуждением модели? Если я придумываю новую математическую задачку для средней школы, которая решается в 4-5 действий, и модель её решает — какая здесь доля запоминания, а какая интеллекта/рассуждений? Модель могла видеть много схожих задач (больше, чем дети при обучении в школе), но не конкретно эту и даже не другую такую же с идентичным принципом решения.
И после преодоления этого региона, в теории, начинаются задачи, связанные с очень банальными знаниями, но требующие именно рассуждений. Вот ARC Benchmark, по мнению его создателя Francois Chollet, такой. С ним неплохо справляются дети, на 90%+ решают взрослые, но ни одна модель или даже система ни 4 года назад, ни сегодня не показывает близких результатов.
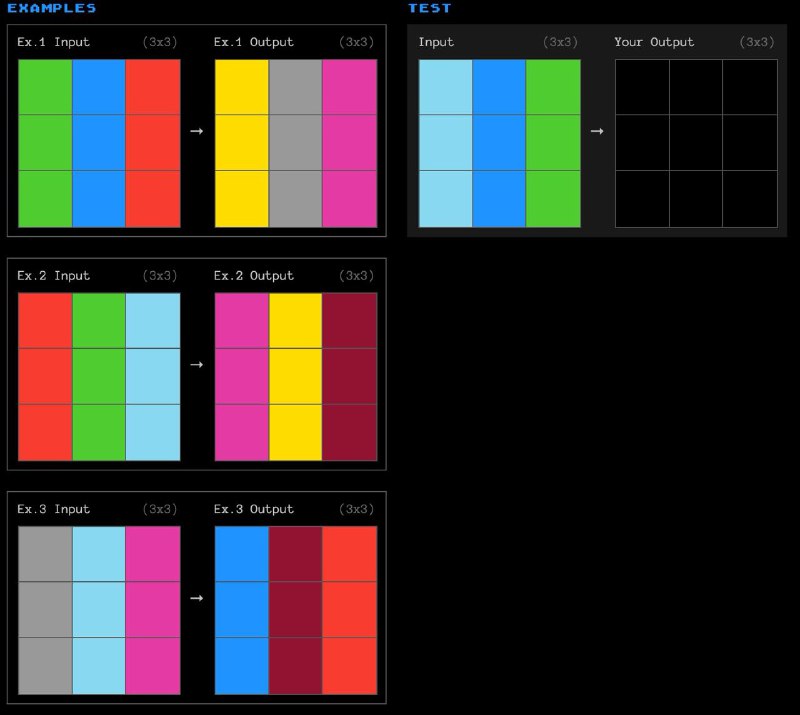
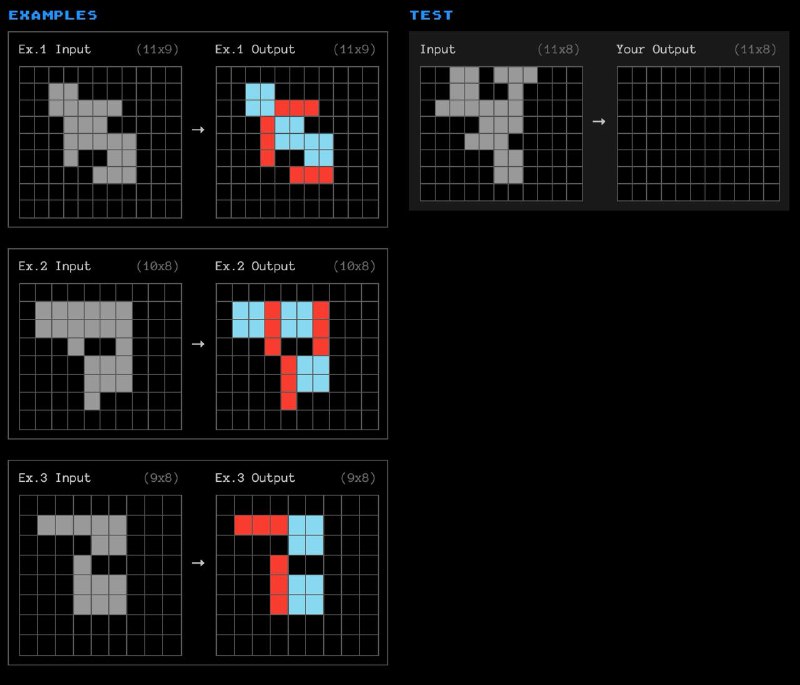
Как выглядит бенчмарк? Это сотни задачек по типу тех, что указаны на картинке, или которые вы можете покликать тут. Цель — по нескольким примерам найти паттерн, и применить его к новой ситуации. Francois считает, что паттерны и тип задачи тут очень редки, чтобы не допустить запоминания, но в то же время человек может разобраться.
Chollet вот 5 лет назад статью написал про свои взгляды и то, почему именно так хочет тестировать модели, и про то, почему нахождение новых паттернов из очень маленького набора данных и умение их применять — это мера интеллекта.
В среднем человек решает 85% задач (когда выходная картинка для нового примера идентично авторской), а LLM-ки единицы процентов. Лучшие системы (заточенные под схожий класс задач) добиваются ~34%.
Многие бенчмарки (то есть наборы данных с размеченными ожидаемыми ответами, признанные прокси-оценками качества) для LLM справедливо можно критиковать за то, что они по сути тестируют запоминание. Самый простой пример — бенчмарки вопросов-ответов (или тестов с опциями ответа, но не все): чтобы ответить на вопрос «в каком году было то и то?» не нужно быть гением мысли или обладать выдающимся интеллектом. Достаточно просто запомнить факт.
По мере усложнения задач в какой-то момент мы натыкаемся на дилемму — что является запоминанием, а что рассуждением модели? Если я придумываю новую математическую задачку для средней школы, которая решается в 4-5 действий, и модель её решает — какая здесь доля запоминания, а какая интеллекта/рассуждений? Модель могла видеть много схожих задач (больше, чем дети при обучении в школе), но не конкретно эту и даже не другую такую же с идентичным принципом решения.
И после преодоления этого региона, в теории, начинаются задачи, связанные с очень банальными знаниями, но требующие именно рассуждений. Вот ARC Benchmark, по мнению его создателя Francois Chollet, такой. С ним неплохо справляются дети, на 90%+ решают взрослые, но ни одна модель или даже система ни 4 года назад, ни сегодня не показывает близких результатов.
Как выглядит бенчмарк? Это сотни задачек по типу тех, что указаны на картинке, или которые вы можете покликать тут. Цель — по нескольким примерам найти паттерн, и применить его к новой ситуации. Francois считает, что паттерны и тип задачи тут очень редки, чтобы не допустить запоминания, но в то же время человек может разобраться.
Chollet вот 5 лет назад статью написал про свои взгляды и то, почему именно так хочет тестировать модели, и про то, почему нахождение новых паттернов из очень маленького набора данных и умение их применять — это мера интеллекта.
В среднем человек решает 85% задач (когда выходная картинка для нового примера идентично авторской), а LLM-ки единицы процентов. Лучшие системы (заточенные под схожий класс задач) добиваются ~34%.
group-telegram.com/seeallochnaya/1523
Create:
Last Update:
Last Update:
ARC Benchmark
Многие бенчмарки (то есть наборы данных с размеченными ожидаемыми ответами, признанные прокси-оценками качества) для LLM справедливо можно критиковать за то, что они по сути тестируют запоминание. Самый простой пример — бенчмарки вопросов-ответов (или тестов с опциями ответа, но не все): чтобы ответить на вопрос «в каком году было то и то?» не нужно быть гением мысли или обладать выдающимся интеллектом. Достаточно просто запомнить факт.
По мере усложнения задач в какой-то момент мы натыкаемся на дилемму — что является запоминанием, а что рассуждением модели? Если я придумываю новую математическую задачку для средней школы, которая решается в 4-5 действий, и модель её решает — какая здесь доля запоминания, а какая интеллекта/рассуждений? Модель могла видеть много схожих задач (больше, чем дети при обучении в школе), но не конкретно эту и даже не другую такую же с идентичным принципом решения.
И после преодоления этого региона, в теории, начинаются задачи, связанные с очень банальными знаниями, но требующие именно рассуждений. Вот ARC Benchmark, по мнению его создателя Francois Chollet, такой. С ним неплохо справляются дети, на 90%+ решают взрослые, но ни одна модель или даже система ни 4 года назад, ни сегодня не показывает близких результатов.
Как выглядит бенчмарк? Это сотни задачек по типу тех, что указаны на картинке, или которые вы можете покликать тут. Цель — по нескольким примерам найти паттерн, и применить его к новой ситуации. Francois считает, что паттерны и тип задачи тут очень редки, чтобы не допустить запоминания, но в то же время человек может разобраться.
Chollet вот 5 лет назад статью написал про свои взгляды и то, почему именно так хочет тестировать модели, и про то, почему нахождение новых паттернов из очень маленького набора данных и умение их применять — это мера интеллекта.
В среднем человек решает 85% задач (когда выходная картинка для нового примера идентично авторской), а LLM-ки единицы процентов. Лучшие системы (заточенные под схожий класс задач) добиваются ~34%.
Многие бенчмарки (то есть наборы данных с размеченными ожидаемыми ответами, признанные прокси-оценками качества) для LLM справедливо можно критиковать за то, что они по сути тестируют запоминание. Самый простой пример — бенчмарки вопросов-ответов (или тестов с опциями ответа, но не все): чтобы ответить на вопрос «в каком году было то и то?» не нужно быть гением мысли или обладать выдающимся интеллектом. Достаточно просто запомнить факт.
По мере усложнения задач в какой-то момент мы натыкаемся на дилемму — что является запоминанием, а что рассуждением модели? Если я придумываю новую математическую задачку для средней школы, которая решается в 4-5 действий, и модель её решает — какая здесь доля запоминания, а какая интеллекта/рассуждений? Модель могла видеть много схожих задач (больше, чем дети при обучении в школе), но не конкретно эту и даже не другую такую же с идентичным принципом решения.
И после преодоления этого региона, в теории, начинаются задачи, связанные с очень банальными знаниями, но требующие именно рассуждений. Вот ARC Benchmark, по мнению его создателя Francois Chollet, такой. С ним неплохо справляются дети, на 90%+ решают взрослые, но ни одна модель или даже система ни 4 года назад, ни сегодня не показывает близких результатов.
Как выглядит бенчмарк? Это сотни задачек по типу тех, что указаны на картинке, или которые вы можете покликать тут. Цель — по нескольким примерам найти паттерн, и применить его к новой ситуации. Francois считает, что паттерны и тип задачи тут очень редки, чтобы не допустить запоминания, но в то же время человек может разобраться.
Chollet вот 5 лет назад статью написал про свои взгляды и то, почему именно так хочет тестировать модели, и про то, почему нахождение новых паттернов из очень маленького набора данных и умение их применять — это мера интеллекта.
В среднем человек решает 85% задач (когда выходная картинка для нового примера идентично авторской), а LLM-ки единицы процентов. Лучшие системы (заточенные под схожий класс задач) добиваются ~34%.
BY Сиолошная

Share with your friend now:
group-telegram.com/seeallochnaya/1523