
Орги ChatBot Arena проанализировали, как Llama-3 забралась так высоко на лидерборде.
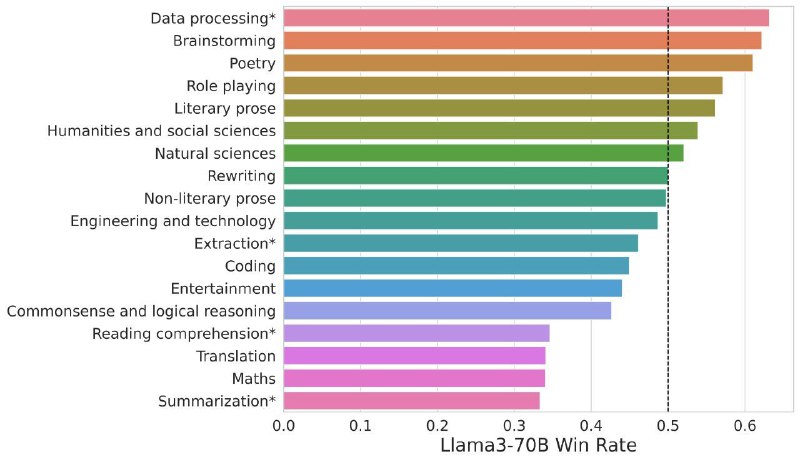
Llama 3, будучи сравнительно маленькой моделью отстаёт от GPT-4 на более сложных задачах, типа матеши и ризонинга, судя по анализу от Lmsys. Но вот в креативных задачах и более абстрактных задачах, где нужно что-то придумать (куда сходить вечером и тп) выигрывает старшие модели причём со значительным отрывом. Таких запросов от юзеров по всей видимости большинство, и именно они закидывают ламу3 в топ. Но это не отвечает на вопрос, как ей удаётся побеждать старшие модели на этих запросах. Кажется, что если модель лучше и больше, то она должна быть умнее во всем.
Так почему же llama 3 так хороша? Если коротко, то это компьют и качественные данные.
- Датасет фильтровали и фильтровали, чтобы модель училась только на всем хорошем. Кстати секрет той же Dalle 3 или GPT-4 в том же. У Dalle3 картинки в трейн датасете очень подробно описаны gpt-шкой с виженом. А для самой GPT-4, понятно, тоже сильно фильтровали тексты.
- Есть такая гипотеза – Оптимальность модели по Шиншилле. Из нее следует, что для 8B модели оптимально по компьюту натренить ее на 200B токенах. И долгое время это считалось стандартом – якобы дальше тренить мелкую модель смысла нет, и лучше взять модель пожирнее. Но Llama3 натренили на 15 трлн токенов и она всё ещё продолжала учиться. Крч перетрейн капитальный.
- Аккуратный файнтюн на ручной разметке. Кроме почти уже стандартных supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), и direct preference optimization (DPO) парни скормили лламе3 10 лямов размеченных вручную примеров.
Окей, с тяжелыми тасками она всё равно не очень справляется. Но, оказывается, это и не надо...🤷♀️
Юзеры обычно просят какую-нибудь фигню по типу "придумай то то, как сделать это..."
Лама благодаря хорошему датасету и ручному файнтюну просто оказалась очень харизматичной. Отвечает приятно, структура хорошая, на человека похожа:)
High-level Видосик про Llama3
Предыдущий пост про Llama3
Блог пост
@ai_newz
Llama 3, будучи сравнительно маленькой моделью отстаёт от GPT-4 на более сложных задачах, типа матеши и ризонинга, судя по анализу от Lmsys. Но вот в креативных задачах и более абстрактных задачах, где нужно что-то придумать (куда сходить вечером и тп) выигрывает старшие модели причём со значительным отрывом. Таких запросов от юзеров по всей видимости большинство, и именно они закидывают ламу3 в топ. Но это не отвечает на вопрос, как ей удаётся побеждать старшие модели на этих запросах. Кажется, что если модель лучше и больше, то она должна быть умнее во всем.
Так почему же llama 3 так хороша? Если коротко, то это компьют и качественные данные.
- Датасет фильтровали и фильтровали, чтобы модель училась только на всем хорошем. Кстати секрет той же Dalle 3 или GPT-4 в том же. У Dalle3 картинки в трейн датасете очень подробно описаны gpt-шкой с виженом. А для самой GPT-4, понятно, тоже сильно фильтровали тексты.
- Есть такая гипотеза – Оптимальность модели по Шиншилле. Из нее следует, что для 8B модели оптимально по компьюту натренить ее на 200B токенах. И долгое время это считалось стандартом – якобы дальше тренить мелкую модель смысла нет, и лучше взять модель пожирнее. Но Llama3 натренили на 15 трлн токенов и она всё ещё продолжала учиться. Крч перетрейн капитальный.
- Аккуратный файнтюн на ручной разметке. Кроме почти уже стандартных supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), и direct preference optimization (DPO) парни скормили лламе3 10 лямов размеченных вручную примеров.
Окей, с тяжелыми тасками она всё равно не очень справляется. Но, оказывается, это и не надо...🤷♀️
Юзеры обычно просят какую-нибудь фигню по типу "придумай то то, как сделать это..."
Лама благодаря хорошему датасету и ручному файнтюну просто оказалась очень харизматичной. Отвечает приятно, структура хорошая, на человека похожа:)
High-level Видосик про Llama3
Предыдущий пост про Llama3
Блог пост
@ai_newz
group-telegram.com/ai_newz/2688
Create:
Last Update:
Last Update:
Орги ChatBot Arena проанализировали, как Llama-3 забралась так высоко на лидерборде.
Llama 3, будучи сравнительно маленькой моделью отстаёт от GPT-4 на более сложных задачах, типа матеши и ризонинга, судя по анализу от Lmsys. Но вот в креативных задачах и более абстрактных задачах, где нужно что-то придумать (куда сходить вечером и тп) выигрывает старшие модели причём со значительным отрывом. Таких запросов от юзеров по всей видимости большинство, и именно они закидывают ламу3 в топ. Но это не отвечает на вопрос, как ей удаётся побеждать старшие модели на этих запросах. Кажется, что если модель лучше и больше, то она должна быть умнее во всем.
Так почему же llama 3 так хороша? Если коротко, то это компьют и качественные данные.
- Датасет фильтровали и фильтровали, чтобы модель училась только на всем хорошем. Кстати секрет той же Dalle 3 или GPT-4 в том же. У Dalle3 картинки в трейн датасете очень подробно описаны gpt-шкой с виженом. А для самой GPT-4, понятно, тоже сильно фильтровали тексты.
- Есть такая гипотеза – Оптимальность модели по Шиншилле. Из нее следует, что для 8B модели оптимально по компьюту натренить ее на 200B токенах. И долгое время это считалось стандартом – якобы дальше тренить мелкую модель смысла нет, и лучше взять модель пожирнее. Но Llama3 натренили на 15 трлн токенов и она всё ещё продолжала учиться. Крч перетрейн капитальный.
- Аккуратный файнтюн на ручной разметке. Кроме почти уже стандартных supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), и direct preference optimization (DPO) парни скормили лламе3 10 лямов размеченных вручную примеров.
Окей, с тяжелыми тасками она всё равно не очень справляется. Но, оказывается, это и не надо...🤷♀️
Юзеры обычно просят какую-нибудь фигню по типу "придумай то то, как сделать это..."
Лама благодаря хорошему датасету и ручному файнтюну просто оказалась очень харизматичной. Отвечает приятно, структура хорошая, на человека похожа:)
High-level Видосик про Llama3
Предыдущий пост про Llama3
Блог пост
@ai_newz
Llama 3, будучи сравнительно маленькой моделью отстаёт от GPT-4 на более сложных задачах, типа матеши и ризонинга, судя по анализу от Lmsys. Но вот в креативных задачах и более абстрактных задачах, где нужно что-то придумать (куда сходить вечером и тп) выигрывает старшие модели причём со значительным отрывом. Таких запросов от юзеров по всей видимости большинство, и именно они закидывают ламу3 в топ. Но это не отвечает на вопрос, как ей удаётся побеждать старшие модели на этих запросах. Кажется, что если модель лучше и больше, то она должна быть умнее во всем.
Так почему же llama 3 так хороша? Если коротко, то это компьют и качественные данные.
- Датасет фильтровали и фильтровали, чтобы модель училась только на всем хорошем. Кстати секрет той же Dalle 3 или GPT-4 в том же. У Dalle3 картинки в трейн датасете очень подробно описаны gpt-шкой с виженом. А для самой GPT-4, понятно, тоже сильно фильтровали тексты.
- Есть такая гипотеза – Оптимальность модели по Шиншилле. Из нее следует, что для 8B модели оптимально по компьюту натренить ее на 200B токенах. И долгое время это считалось стандартом – якобы дальше тренить мелкую модель смысла нет, и лучше взять модель пожирнее. Но Llama3 натренили на 15 трлн токенов и она всё ещё продолжала учиться. Крч перетрейн капитальный.
- Аккуратный файнтюн на ручной разметке. Кроме почти уже стандартных supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), и direct preference optimization (DPO) парни скормили лламе3 10 лямов размеченных вручную примеров.
Окей, с тяжелыми тасками она всё равно не очень справляется. Но, оказывается, это и не надо...🤷♀️
Юзеры обычно просят какую-нибудь фигню по типу "придумай то то, как сделать это..."
Лама благодаря хорошему датасету и ручному файнтюну просто оказалась очень харизматичной. Отвечает приятно, структура хорошая, на человека похожа:)
High-level Видосик про Llama3
Предыдущий пост про Llama3
Блог пост
@ai_newz
BY эйай ньюз



Share with your friend now:
group-telegram.com/ai_newz/2688