
{kind=link}
group-telegram.com/theworldisnoteasy/1262
Last Update:
Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке.
В 2020-х расклад сил в технологическом соревновании стало предельно просто оценивать. Революция «Глубокого обучения Больших моделей на Больших данных» превратила вычислительную мощность в ключевой фактор прогресса практически всех интеллектуально емких индустрий: от разработки новых лекарств до новых видов вооружений. А там, где задействован ИИ (а он уже почти всюду) вычислительная мощность, вообще, решает все.
Формула превосходства стала предельно проста:
• собери как можно больше данных;
• создай как можно более сложную (по числу параметров) модель;
• обучи модель как можно быстрее.
Тот, у кого будет «больше-больше-быстрее» имеет максимально высокие шансы выиграть в технологической гонке. А здесь все упирается в вычислительную мощность «железа» (HW) и алгоритмов (SW).
И при всем уважении к алгоритмам, но в этой паре их роль №2. Ибо алгоритм изобрести, скопировать или даже украсть все же проще, чем HW. «Железо» либо есть, либо его нет.
Это мы проходили еще в СССР. Это же стало даже более критическим фактором в эпоху «Глубокого обучения Больших моделей на Больших данных».
Вот два самых свежих примера.
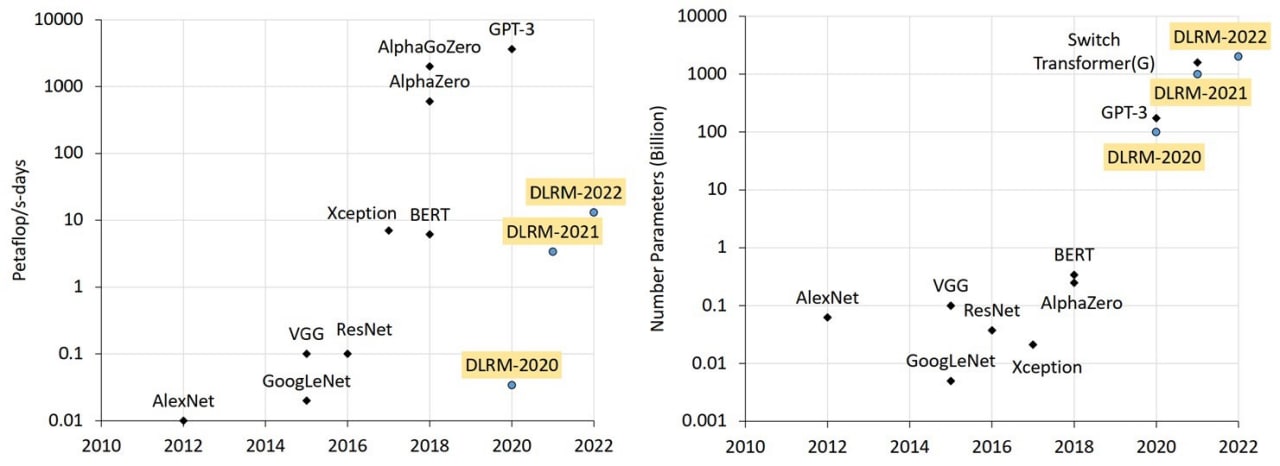
1) Facebook раскрыл свою систему рекомендаций. Она построена на модели рекомендаций глубокого обучения (DLRM). Содержит эта модель 12 триллионов параметров и требует суммарного объема вычислений более 10 Petaflop/s-days.
2) Microsoft скоро продемонстрирует модель для ИИ с 1 триллионом параметров. Она работает на системе вычислительной производительности 502 Petaflop/s на 3072 графических процессорах.
Для сравнения, языковая модель GPT-2, разработанная OpenAI 2 года назад, поразила мир тем, что у нее было 1,5 миллиарда параметров. А GPT-3, вышедшая в 2020 имела уже 175 млрд. параметров.
Как видите, модели с триллионами параметров – уже данность. И чтобы их учить не годами, а днями, нужно «железо» сумасшедшей вычислительной мощности.
Т.е. сами видите, - есть «железо» - участвуй в гонке, нет «железа» - кури в сторонке.
На приложенной картинке свежие данные о размерах моделей и требуемой для них вычислительной мощности.
#HPC #ИИгонка
BY Малоизвестное интересное

Share with your friend now:
group-telegram.com/theworldisnoteasy/1262