
Deepseek V2: топ за свои деньги
Что-то в опенсорс в последнее время попадает прям поток MoE моделей, вот и DeepSeek V2 из них. 236B параметров, из которых 21B - активных. По качеству - между Mixtral 8x22B и LLaMa 3 70B, но при этом в 2-4 раза дешевле этих моделей у самых дешёвых провайдеров, всего лишь 14 центов за млн токенов инпута и 28 за млн токенов на выход. Лицензия модели MIT, так что до конца недели будет штук пять разных провайдеров дешевле этого.
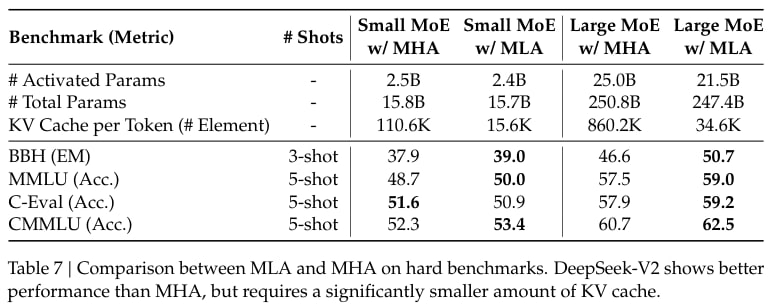
Главная особенность - Multi-Head Latent Attention (MLA). От обычного Multi-Head Attention (MHA) он отличается механизмом сжатия KV Cache, где он хранится как низкоранговая матрица, откуда и куда проецируется когда его нужно использовать или обновить. Из экспериментов, по качеству это работает лучше MHA, при этом используя в 4 раза меньше памяти чем обычные Grouped Query Attention конфиги. Из нюансов - авторам пришлось изобрести новый вариант RoPE чтобы это всё заработало, так как обычный RoPE такого количества линейных проекций туда и назад переживать решительно отказывается. Если честно, я не совсем понимаю почему это работает и почему нету абляций для dense моделей, но интересно как это будет сочетаться с квантизацией KV кэша.
Размер контекста - 128k. Тренировали это всё на 8 триллионах токенов в течении 1.5 миллиона часов на H800 (китайская версия H100). Это уровень компьюта тренировки LLaMa 3 8B и примерно в 3 раза больше чем у Snowflake Arctic.
У модели 162 эксперта, из которых 2 перманентно активные, а из остальных 160-ти на каждый токен выбирается 6. Хочу отметить что эксперты там крайне маленькие – у каждого размерность всего 1536.
Соотношение цены и качества прекрасное, если все подтвердится на ChatBot Arena.
Из минусов — размер. В BF16 для локального инференса нужно 8x A100 с 80GB VRAM. Вся надежда на квантизацию.
Демка
Пейпер
Базовая модель
Чат версия
@ai_newz
Что-то в опенсорс в последнее время попадает прям поток MoE моделей, вот и DeepSeek V2 из них. 236B параметров, из которых 21B - активных. По качеству - между Mixtral 8x22B и LLaMa 3 70B, но при этом в 2-4 раза дешевле этих моделей у самых дешёвых провайдеров, всего лишь 14 центов за млн токенов инпута и 28 за млн токенов на выход. Лицензия модели MIT, так что до конца недели будет штук пять разных провайдеров дешевле этого.
Главная особенность - Multi-Head Latent Attention (MLA). От обычного Multi-Head Attention (MHA) он отличается механизмом сжатия KV Cache, где он хранится как низкоранговая матрица, откуда и куда проецируется когда его нужно использовать или обновить. Из экспериментов, по качеству это работает лучше MHA, при этом используя в 4 раза меньше памяти чем обычные Grouped Query Attention конфиги. Из нюансов - авторам пришлось изобрести новый вариант RoPE чтобы это всё заработало, так как обычный RoPE такого количества линейных проекций туда и назад переживать решительно отказывается. Если честно, я не совсем понимаю почему это работает и почему нету абляций для dense моделей, но интересно как это будет сочетаться с квантизацией KV кэша.
Размер контекста - 128k. Тренировали это всё на 8 триллионах токенов в течении 1.5 миллиона часов на H800 (китайская версия H100). Это уровень компьюта тренировки LLaMa 3 8B и примерно в 3 раза больше чем у Snowflake Arctic.
У модели 162 эксперта, из которых 2 перманентно активные, а из остальных 160-ти на каждый токен выбирается 6. Хочу отметить что эксперты там крайне маленькие – у каждого размерность всего 1536.
Соотношение цены и качества прекрасное, если все подтвердится на ChatBot Arena.
Из минусов — размер. В BF16 для локального инференса нужно 8x A100 с 80GB VRAM. Вся надежда на квантизацию.
Демка
Пейпер
Базовая модель
Чат версия
@ai_newz
group-telegram.com/ai_newz/2662
Create:
Last Update:
Last Update:
Deepseek V2: топ за свои деньги
Что-то в опенсорс в последнее время попадает прям поток MoE моделей, вот и DeepSeek V2 из них. 236B параметров, из которых 21B - активных. По качеству - между Mixtral 8x22B и LLaMa 3 70B, но при этом в 2-4 раза дешевле этих моделей у самых дешёвых провайдеров, всего лишь 14 центов за млн токенов инпута и 28 за млн токенов на выход. Лицензия модели MIT, так что до конца недели будет штук пять разных провайдеров дешевле этого.
Главная особенность - Multi-Head Latent Attention (MLA). От обычного Multi-Head Attention (MHA) он отличается механизмом сжатия KV Cache, где он хранится как низкоранговая матрица, откуда и куда проецируется когда его нужно использовать или обновить. Из экспериментов, по качеству это работает лучше MHA, при этом используя в 4 раза меньше памяти чем обычные Grouped Query Attention конфиги. Из нюансов - авторам пришлось изобрести новый вариант RoPE чтобы это всё заработало, так как обычный RoPE такого количества линейных проекций туда и назад переживать решительно отказывается. Если честно, я не совсем понимаю почему это работает и почему нету абляций для dense моделей, но интересно как это будет сочетаться с квантизацией KV кэша.
Размер контекста - 128k. Тренировали это всё на 8 триллионах токенов в течении 1.5 миллиона часов на H800 (китайская версия H100). Это уровень компьюта тренировки LLaMa 3 8B и примерно в 3 раза больше чем у Snowflake Arctic.
У модели 162 эксперта, из которых 2 перманентно активные, а из остальных 160-ти на каждый токен выбирается 6. Хочу отметить что эксперты там крайне маленькие – у каждого размерность всего 1536.
Соотношение цены и качества прекрасное, если все подтвердится на ChatBot Arena.
Из минусов — размер. В BF16 для локального инференса нужно 8x A100 с 80GB VRAM. Вся надежда на квантизацию.
Демка
Пейпер
Базовая модель
Чат версия
@ai_newz
Что-то в опенсорс в последнее время попадает прям поток MoE моделей, вот и DeepSeek V2 из них. 236B параметров, из которых 21B - активных. По качеству - между Mixtral 8x22B и LLaMa 3 70B, но при этом в 2-4 раза дешевле этих моделей у самых дешёвых провайдеров, всего лишь 14 центов за млн токенов инпута и 28 за млн токенов на выход. Лицензия модели MIT, так что до конца недели будет штук пять разных провайдеров дешевле этого.
Главная особенность - Multi-Head Latent Attention (MLA). От обычного Multi-Head Attention (MHA) он отличается механизмом сжатия KV Cache, где он хранится как низкоранговая матрица, откуда и куда проецируется когда его нужно использовать или обновить. Из экспериментов, по качеству это работает лучше MHA, при этом используя в 4 раза меньше памяти чем обычные Grouped Query Attention конфиги. Из нюансов - авторам пришлось изобрести новый вариант RoPE чтобы это всё заработало, так как обычный RoPE такого количества линейных проекций туда и назад переживать решительно отказывается. Если честно, я не совсем понимаю почему это работает и почему нету абляций для dense моделей, но интересно как это будет сочетаться с квантизацией KV кэша.
Размер контекста - 128k. Тренировали это всё на 8 триллионах токенов в течении 1.5 миллиона часов на H800 (китайская версия H100). Это уровень компьюта тренировки LLaMa 3 8B и примерно в 3 раза больше чем у Snowflake Arctic.
У модели 162 эксперта, из которых 2 перманентно активные, а из остальных 160-ти на каждый токен выбирается 6. Хочу отметить что эксперты там крайне маленькие – у каждого размерность всего 1536.
Соотношение цены и качества прекрасное, если все подтвердится на ChatBot Arena.
Из минусов — размер. В BF16 для локального инференса нужно 8x A100 с 80GB VRAM. Вся надежда на квантизацию.
Демка
Пейпер
Базовая модель
Чат версия
@ai_newz
BY эйай ньюз

Share with your friend now:
group-telegram.com/ai_newz/2662