
{kind=link}
{kind=link}
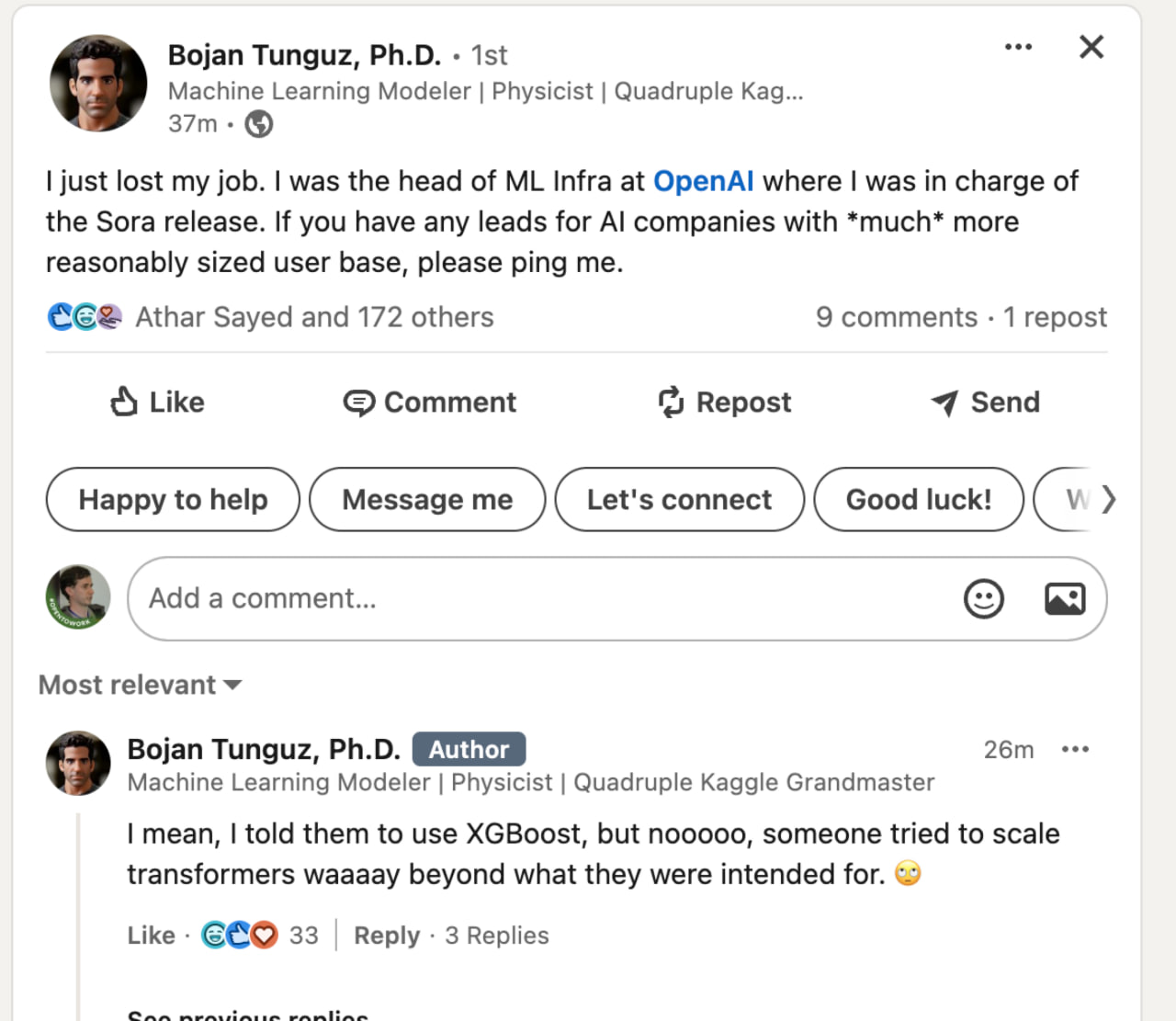
How to use AI to write articles about how to use AI as a product manager for your AI app on your journey to being replaced by an AI product manager
Andrew Ng опубликовал мини-блог пост AI Product Management. К сожалению, текст настолько generic, что его очень красочно описали на ycombinator
Andrew Ng опубликовал мини-блог пост AI Product Management. К сожалению, текст настолько generic, что его очень красочно описали на ycombinator
{kind=link}
Byte Latent Transformer: Patches Scale Better Than Tokens
Новая статья от META - Byte Latent Transformer. Пробуют новый подход к токенизации - вместо фиксированного словаря используют динамические patches, размер которых определяется по энтропии следующего байта. Модель успешно масштабировали до 8B параметров и 4T байтов, при этом с лучшим качеством. Плюс эффективность и тренировки, и инференса лучше. Каких-то особых недостатков подхода авторы не описали. Ждём Llama 4 на байтах? :)
Paper link
Code link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Новая статья от META - Byte Latent Transformer. Пробуют новый подход к токенизации - вместо фиксированного словаря используют динамические patches, размер которых определяется по энтропии следующего байта. Модель успешно масштабировали до 8B параметров и 4T байтов, при этом с лучшим качеством. Плюс эффективность и тренировки, и инференса лучше. Каких-то особых недостатков подхода авторы не описали. Ждём Llama 4 на байтах? :)
Paper link
Code link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
Falcon 3
Институт в Абу-Даби выпустил новую версию своей модели, блогпост на huggingface тут.
Модели размером от 1B до 10B. Одна из моделей - Mamba. Уверяют, что модель на 3B лучше, чем Llama 3.1-8B
#datascience
Институт в Абу-Даби выпустил новую версию своей модели, блогпост на huggingface тут.
Модели размером от 1B до 10B. Одна из моделей - Mamba. Уверяют, что модель на 3B лучше, чем Llama 3.1-8B
#datascience
{kind=link}
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Новая версия всем известного BERT. Авторы обновили архитектуру, добавили модные трюки для оптимизации тренировки, досыпали данных. Получили SOTA на большинстве бенчмарков.
Было интересно почитать какие изменения появились за 6 лет. В конце статьи авторы ещё подробно описывали эксперименты и мысли. Из забавного: "проблема первого мира" - если в батче 500к-1млн семплов, то дефолтный семплер в Pytorch плохо рандомит. Авторам пришлось взять ссемплер из Numpy.
А ещё интересное - один из авторов недавно взял соло золото в соревновании на каггле и занял 4-е место в общем рейтинге соревнований.
Paper
Code
Weights
Blogpost
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Новая версия всем известного BERT. Авторы обновили архитектуру, добавили модные трюки для оптимизации тренировки, досыпали данных. Получили SOTA на большинстве бенчмарков.
Было интересно почитать какие изменения появились за 6 лет. В конце статьи авторы ещё подробно описывали эксперименты и мысли. Из забавного: "проблема первого мира" - если в батче 500к-1млн семплов, то дефолтный семплер в Pytorch плохо рандомит. Авторам пришлось взять ссемплер из Numpy.
А ещё интересное - один из авторов недавно взял соло золото в соревновании на каггле и занял 4-е место в общем рейтинге соревнований.
Paper
Code
Weights
Blogpost
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
Data, Stories and Languages
DataFest Yerevan Я завтра выступаю на DataFest Yerevan с рассказом про применение face recognition для выявления множественных аккаунтов одного человека. Блогпост про это я уже публиковал. По идее при регистрации на сайте https://datafest.am/2024 должна…
И вот доклады выложили на youtube!
https://www.youtube.com/watch?v=hieJhU9J3e0&list=PLvwlJZXG6IkVRkSDyJsPmcBXw25Nm7_yt&index=16
По ссылке можно посмотреть как мой доклад, так и остальные. Из забавного: с 17:40 на протяжении шести минут я отвечал на вопросы одного очень любознательного человека. Надеюсь, что это был не один из фродстеров :) И надеюсь, что я не сказал ничего лишнего 👀
#datascience
https://www.youtube.com/watch?v=hieJhU9J3e0&list=PLvwlJZXG6IkVRkSDyJsPmcBXw25Nm7_yt&index=16
По ссылке можно посмотреть как мой доклад, так и остальные. Из забавного: с 17:40 на протяжении шести минут я отвечал на вопросы одного очень любознательного человека. Надеюсь, что это был не один из фродстеров :) И надеюсь, что я не сказал ничего лишнего 👀
#datascience
YouTube
Fraud Detection via Face Recognition
Speaker: Andrei Lukianenko (Careem)
Topic: Fraud Detection via Face Recognition
DataFest Yerevan 2024, https://datafest.am/
Topic: Fraud Detection via Face Recognition
DataFest Yerevan 2024, https://datafest.am/
🤖 Папка ИИ
Под конец этого года коллеги из «ГОС ИТ Богатырёва» собрали нейрокрутую папку с каналами про ИИ и технологии, в которую включили и меня. Актуальные новости, советы по работе с LLM и многое другое.
Добавляйте папку и делитесь со своими друзьями.
Под конец этого года коллеги из «ГОС ИТ Богатырёва» собрали нейрокрутую папку с каналами про ИИ и технологии, в которую включили и меня. Актуальные новости, советы по работе с LLM и многое другое.
Добавляйте папку и делитесь со своими друзьями.
Telegram
ИИ и техно
Polina invites you to add the folder “ИИ и техно”, which includes 28 chats.
И снова о том, как современные LLM увеличивают разницу между экспертами и новичками
Уже давно идут бурные обсуждения того, что благодаря LLM разница между сеньорами и джунами всё растёт и растёт - ибо опытные люди знают что и как спросить, могут поймать ошибки, могут подтолкнуть ботов в нужную сторону.
Сегодня я наткнулся на тредик на реддите. Автор жалуется, что o1 pro (который за 200$) бесполезен для написания кода.
Самый топовый ответ - "Type out a very detailed document that explains exactly what you want from your code - it could be several pages in length. Then feed that whole document into o1-pro and just let it do its thing. Afterwards, you can switch to 4o if you want to do minor adjustments using Canvas."
То есть предлагается написать полноценное детальное техзадание, которое бот сможет выполнить по шагам.
В том, насколько такое вообще работает я не уверен - не пробовал. Но если это действительно так, то это, опять же лишь "упрощает" работу сеньоров. Написать качественное детальное тз - это серьёзная задача, не все это могут.
Интересно наблюдать за тем, как индустрия безумно быстро двигается в некоторых направлениях.
#datascience
Уже давно идут бурные обсуждения того, что благодаря LLM разница между сеньорами и джунами всё растёт и растёт - ибо опытные люди знают что и как спросить, могут поймать ошибки, могут подтолкнуть ботов в нужную сторону.
Сегодня я наткнулся на тредик на реддите. Автор жалуется, что o1 pro (который за 200$) бесполезен для написания кода.
Самый топовый ответ - "Type out a very detailed document that explains exactly what you want from your code - it could be several pages in length. Then feed that whole document into o1-pro and just let it do its thing. Afterwards, you can switch to 4o if you want to do minor adjustments using Canvas."
То есть предлагается написать полноценное детальное техзадание, которое бот сможет выполнить по шагам.
В том, насколько такое вообще работает я не уверен - не пробовал. Но если это действительно так, то это, опять же лишь "упрощает" работу сеньоров. Написать качественное детальное тз - это серьёзная задача, не все это могут.
Интересно наблюдать за тем, как индустрия безумно быстро двигается в некоторых направлениях.
#datascience
{kind=link}
12 лет использования Anki для изучения иностранных языков
Я тут осознал, что уже 12 лет использую Anki для изучения иностранных языков. Решил подсобрать статистику и поделиться опытом.
Во-первых, если смотреть на график количества просмотров карточек, можно очень наглядно увидеть, как менялись интересы и жизнь. Есть несколько пиков, когда было активное изучение языков, есть несколько сильных падений - особенно когда перекатился в data science.
В настоящий момент Anki показывает, что у меня 36к карточек. Из них 15.8к - испанский, 9.7к японский и 8.8к немецкий.
В основном я сам создаю колоды - создаю карточки во время чтения, иногда использую готовые колоды.
Несколько советов на основе моего опыта:
• Карточки должны быть максимально чёткими - чтобы ответ был однозначным
• Зубрить слова в вакууме - не особо полезно и интересно, нужны предложения с примерами
• Не надо пытаться выучить все неизвестные слова - мы в родном-то языке не все слова знаем
Подробнее можно почитать в моём блогпосте.
#languages
Я тут осознал, что уже 12 лет использую Anki для изучения иностранных языков. Решил подсобрать статистику и поделиться опытом.
Во-первых, если смотреть на график количества просмотров карточек, можно очень наглядно увидеть, как менялись интересы и жизнь. Есть несколько пиков, когда было активное изучение языков, есть несколько сильных падений - особенно когда перекатился в data science.
В настоящий момент Anki показывает, что у меня 36к карточек. Из них 15.8к - испанский, 9.7к японский и 8.8к немецкий.
В основном я сам создаю колоды - создаю карточки во время чтения, иногда использую готовые колоды.
Несколько советов на основе моего опыта:
• Карточки должны быть максимально чёткими - чтобы ответ был однозначным
• Зубрить слова в вакууме - не особо полезно и интересно, нужны предложения с примерами
• Не надо пытаться выучить все неизвестные слова - мы в родном-то языке не все слова знаем
Подробнее можно почитать в моём блогпосте.
#languages
Andlukyane
12 years of studying foreign languages with Anki – Andrey Lukyanenko
Я не знаю, что это такое, но мне это прислал один из "неизвестных поклонников" то ли из Индии, то ли из Пакистана.
С Новым Годом, товарищи!
С Новым Годом, товарищи!
{kind=link}