
group-telegram.com/abstractDL/272
Last Update:
VAR: Image Generation via Next-Scale Prediction (by Bytedance)
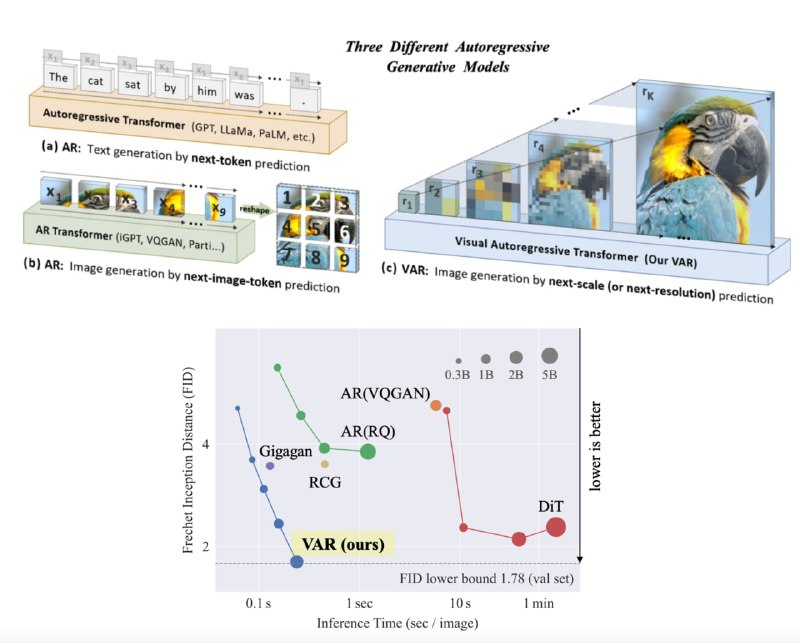
Вы наверняка слышали про авторегрессионный подход к генерации изображений (imageGPT, Dalle-1). Но у этих методов было очень большое ограничение — картиночные токены приходилось "выпрямлять" в 1D последовательность, которая становилась слишком длинной. Поэтому они работали плохо и медленно, уступив место диффузиям.
Авторы VAR предложили мозговзрывательный способ генерировать изображения при помощи GPT без необходимости делать это неприятное "выпрямление" — вместо авторегрессии по пикселям\токенам они делают "next-scale prediction", то есть предсказывают сразу всю матрицу VQVAE токенов за один forward pass. Теперь один шаг авторегрессии — это шаг увеличения разрешения (см. картинку). К моему удивлению, для этого потребовалось совсем немного модификаций оригинальной GPT-2 архитектуры (текстовой).
Такой подход работает просто молниеносно, а законы масштабирования сильно лучше, чем у диффузий. По метрикам VAR бьёт всех на class-conditional датасетах (генерации по тексту пока нет, но над этим уже работают). А тем временем весь код и веса уже в открытом доступе.
P.S. Думаю, что это один из самых перспективных методов генерации изображений (и видео?) на данный момент.
Статья, GitHub, Huggingface
BY AbstractDL
Share with your friend now:
group-telegram.com/abstractDL/272