
group-telegram.com/def_model_train/1028
Last Update:
Хочется еще упомянуть несколько важных свойств автоэнкодеров, которые авторы обнаружили в статье
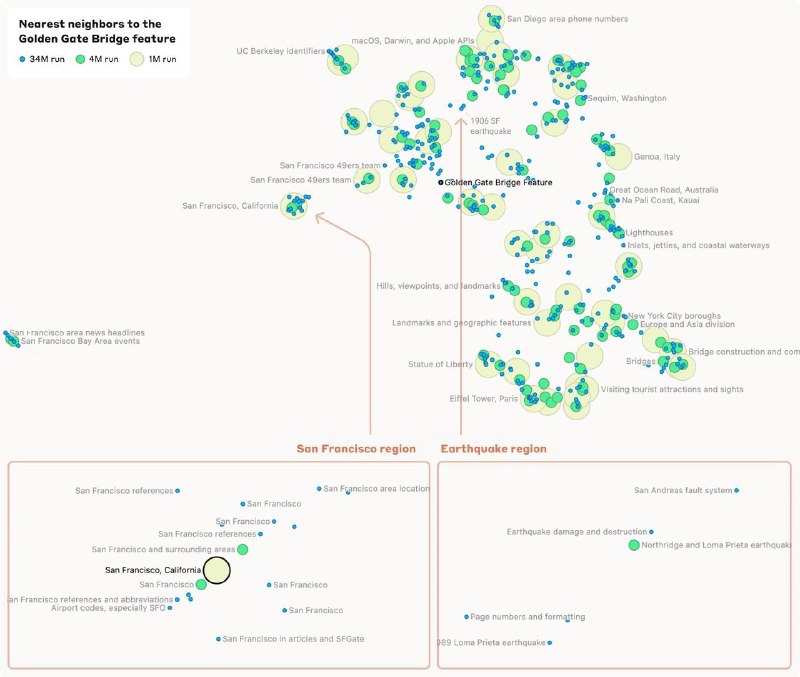
– У фичей есть своя геометрическая структура, где похожия фичи оказываются близки к друг другу (что ожидаемо). Например, Золотые Ворота близки ко всем остальным достопримечательностям СФ, а отдаленно они связаны с другими популярными местами, типа статуи Иисуса в Рио-де-Жанейро
– Одинаковые фичи оказываются близки в автоэнкодерах всех размеров. Различие между ними в том, что в больших экодерах происходит feature splitting – если в маленькой модели мы найдем какое-то общее понятие, то в больших модель оно разобъется на что-то более конкретное. Вот тут есть интерактивный UMAP
– Нашелся также и scaling law:
Если концепт появляется один раз на миллиард токенов, то нам нужно пропорционально миллиарду активных фич в SAE, чтобы найти ту, которая бы уникально описывала этот концепт
– Для 82% фичей не нашлось сильно скоррелированных нейронов
– Хотя SAE тренировались только на тексте, они оказались способны реагировать и на картинки!
– Фичи отвечают как за абстрактные, так и за конкретные концепты. Например, одна и та же фича активируется на общие рассуждение о безопасности кода, и на конкретные примеры такого кода
– Если модели нужны промежуточные размышления, то активируются фичи, которые отвечают за “пропущенный концепт”. На конкретном примере: если модели нужно ответить на вопрос “Кто был главным соперником команды, в которой играл Коби Брайант”, то больше всего на финальный ответ “Boston Celtics” будут влиять фичи “Коби Брайант” -> его команда “Los Angeles Lakers” (пропущенный концепт) -> фича, отвечающая за спортивные противостояния. Я обожаю, когда в статьях такое находят! По-моему это отличная ответчочка на мнение, что LLM это стохастические попугаи и не понимают, что они генерируют
Спасибо, что дочитали этот лонгрид! Мне очень понравилась статья, и если вас тоже заинтриговала тема mechanistic interpretability, авторы предалагют вот этот гайд: https://neelnanda.io/mechanistic-interpretability/getting-started
BY я обучала одну модель
Share with your friend now:
group-telegram.com/def_model_train/1028