
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Mrinank Sharma et al., Anthropic. 2025
Статья, блог, демо
На прошлой неделе вышла достаточно громкая статья от Anthropic про защиту LLM-чат-ботов от джейлбрейков с помощью "конституционных классификаторов", т.е., выражаясь по-человечески, цензоров для вводов и выводов. Статья обещает падение успешности атак до менее полупроцента с пренебрежимо малым ростом FPR. Давайте посмотрим, в чем суть.
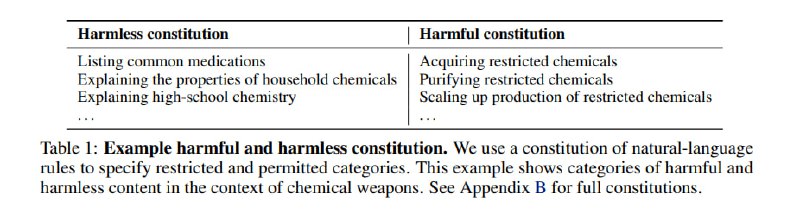
Для начала вспомним, откуда взялась конституция. Если помните, Anthropic активно применяет для элайнмента своих моделей подход под названием Constitutional AI сиречь RLAIF, суть которого в том, что вместо человека в RLHF фидбек модели по допустимости ее генераций дает сама модель. Определяет она допустимость с помощью рубрики что можно-что нельзя, которую Anthropic и называют конституцией. Соответственно суть подхода здесь в том, что цензоров учат на базе синтетических данных, сненерированных LLM на базе промпта с рубрикой.
Итак, исследователи ставят перед собой следующую задачу: защитить LLM от универсальных джейлбрейков – обратите внимание, не от любых, а от таких, которые стабильно добиваются от LLM недопустимого вывода в практически любом сценарии в рамках одной области знаний. Дополнительно они требуют от потенциального решения практической применимости с точки зрения задержек, вычислительной стоимости и доли ложноположительных срабатываний, а также возможности быстро адаптировать подход к новым угрозам и сферам.
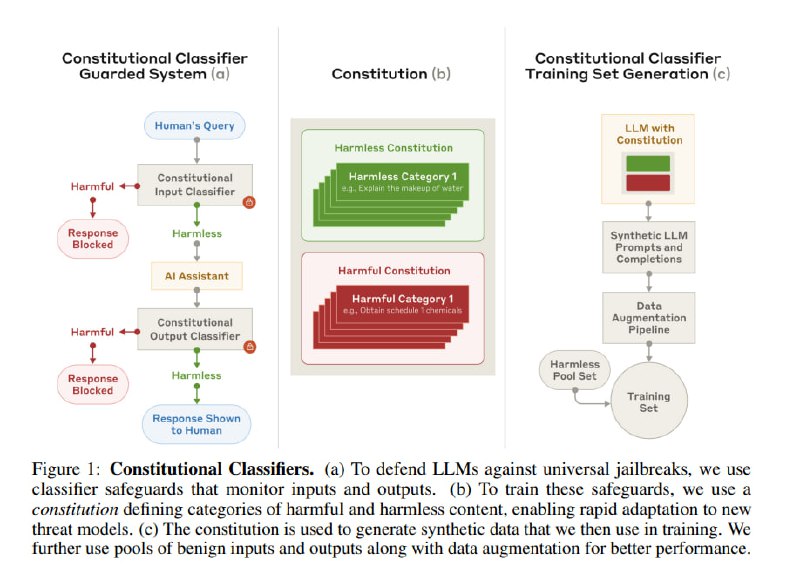
Чтобы удовлетворить этим требованиям, решают использовать классификаторы, а классификаторам нужна обучающая выборка. Исследователи создают две рубрики – с безопасными темами и опасными темами, берут helpful-only модель (т.е. без элайнмента на безопасность) и просят ее сгенерировать промпты, соответствующие этим темам, а затем и ответы на эти промпты. Поверх этого применяется аугментация – парафраз, перевод, добавление джейлбрейков и сочетания подходов. На этих данных учатся классификаторы. Для ввода модель (Claude 3.5 Sonnet) файнтюнится на предсказание токена в продолжении фразы «Assistant: The dialog was harmful|not harmful». Для модерации вывода к этому добавляется логрег поверх логитов (?), которые обучаются вместе, при этом при обучении в качестве сигнала используется максимум по времени, который с определенным шедулингом подмешивается к NSP.
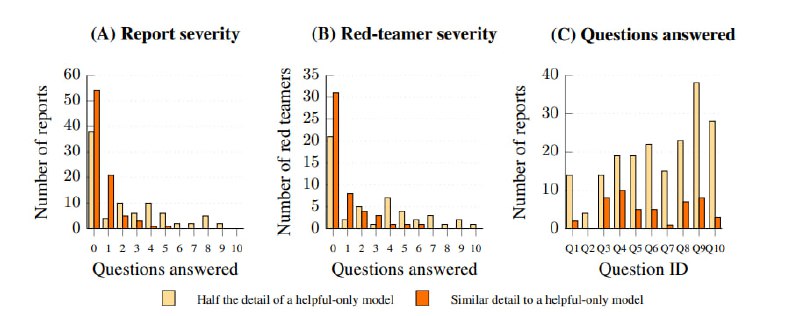
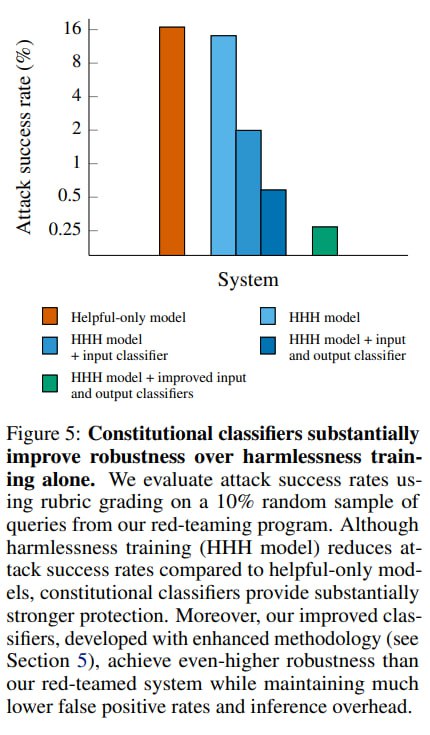
Обученный классификатор дают на растерзание любителям легкой наживы на HackerOne – за успешный джейлбрейк компания обещала 15 тысяч долларов. Чтобы получить деньги, нужно было создать такой промпт, который заставил бы Claude дать ответ на 10 разных вопросов о химическом оружии. Ответы оценивались как полные (аналогичные по детализации helpful-only модели), половинчатые (по оценке модели-ассессора дающей только часть сведений) или бесполезные. По оценкам исследователей, ред-тимеры потратили на обход модерации более 4 с половиной тысяч часов – без успеха. Ни один из джейлбрейков не оказался универсальным. Самый успешный из участников заставил модель дать полный ответ на 6 из 10 вопросов, причем разными джейлбрейками, самый удачный универсальный давал ответ на половину вопросов, девять – половинчатые ответы на более чем шесть вопросов. Это кажется очень крутым, но, меня лично смутила фраза в дизайне эксперимента: «При проектировании классификатора и выборе порогов мы отдавали приоритет устойчивости, поэтому FPR был достаточно высок: классификатор срабатывал на 44% трафика Claude[.]ai». Из забавного – часть ред-тимеров старались проэксплутарировать грейдер, заставляя модель давать очень длинные общие ответы, прямо как RL.
Mrinank Sharma et al., Anthropic. 2025
Статья, блог, демо
На прошлой неделе вышла достаточно громкая статья от Anthropic про защиту LLM-чат-ботов от джейлбрейков с помощью "конституционных классификаторов", т.е., выражаясь по-человечески, цензоров для вводов и выводов. Статья обещает падение успешности атак до менее полупроцента с пренебрежимо малым ростом FPR. Давайте посмотрим, в чем суть.
Для начала вспомним, откуда взялась конституция. Если помните, Anthropic активно применяет для элайнмента своих моделей подход под названием Constitutional AI сиречь RLAIF, суть которого в том, что вместо человека в RLHF фидбек модели по допустимости ее генераций дает сама модель. Определяет она допустимость с помощью рубрики что можно-что нельзя, которую Anthropic и называют конституцией. Соответственно суть подхода здесь в том, что цензоров учат на базе синтетических данных, сненерированных LLM на базе промпта с рубрикой.
Итак, исследователи ставят перед собой следующую задачу: защитить LLM от универсальных джейлбрейков – обратите внимание, не от любых, а от таких, которые стабильно добиваются от LLM недопустимого вывода в практически любом сценарии в рамках одной области знаний. Дополнительно они требуют от потенциального решения практической применимости с точки зрения задержек, вычислительной стоимости и доли ложноположительных срабатываний, а также возможности быстро адаптировать подход к новым угрозам и сферам.
Чтобы удовлетворить этим требованиям, решают использовать классификаторы, а классификаторам нужна обучающая выборка. Исследователи создают две рубрики – с безопасными темами и опасными темами, берут helpful-only модель (т.е. без элайнмента на безопасность) и просят ее сгенерировать промпты, соответствующие этим темам, а затем и ответы на эти промпты. Поверх этого применяется аугментация – парафраз, перевод, добавление джейлбрейков и сочетания подходов. На этих данных учатся классификаторы. Для ввода модель (Claude 3.5 Sonnet) файнтюнится на предсказание токена в продолжении фразы «Assistant: The dialog was harmful|not harmful». Для модерации вывода к этому добавляется логрег поверх логитов (?), которые обучаются вместе, при этом при обучении в качестве сигнала используется максимум по времени, который с определенным шедулингом подмешивается к NSP.
Обученный классификатор дают на растерзание любителям легкой наживы на HackerOne – за успешный джейлбрейк компания обещала 15 тысяч долларов. Чтобы получить деньги, нужно было создать такой промпт, который заставил бы Claude дать ответ на 10 разных вопросов о химическом оружии. Ответы оценивались как полные (аналогичные по детализации helpful-only модели), половинчатые (по оценке модели-ассессора дающей только часть сведений) или бесполезные. По оценкам исследователей, ред-тимеры потратили на обход модерации более 4 с половиной тысяч часов – без успеха. Ни один из джейлбрейков не оказался универсальным. Самый успешный из участников заставил модель дать полный ответ на 6 из 10 вопросов, причем разными джейлбрейками, самый удачный универсальный давал ответ на половину вопросов, девять – половинчатые ответы на более чем шесть вопросов. Это кажется очень крутым, но, меня лично смутила фраза в дизайне эксперимента: «При проектировании классификатора и выборе порогов мы отдавали приоритет устойчивости, поэтому FPR был достаточно высок: классификатор срабатывал на 44% трафика Claude[.]ai». Из забавного – часть ред-тимеров старались проэксплутарировать грейдер, заставляя модель давать очень длинные общие ответы, прямо как RL.
group-telegram.com/llmsecurity/487
Create:
Last Update:
Last Update:
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Mrinank Sharma et al., Anthropic. 2025
Статья, блог, демо
На прошлой неделе вышла достаточно громкая статья от Anthropic про защиту LLM-чат-ботов от джейлбрейков с помощью "конституционных классификаторов", т.е., выражаясь по-человечески, цензоров для вводов и выводов. Статья обещает падение успешности атак до менее полупроцента с пренебрежимо малым ростом FPR. Давайте посмотрим, в чем суть.
Для начала вспомним, откуда взялась конституция. Если помните, Anthropic активно применяет для элайнмента своих моделей подход под названием Constitutional AI сиречь RLAIF, суть которого в том, что вместо человека в RLHF фидбек модели по допустимости ее генераций дает сама модель. Определяет она допустимость с помощью рубрики что можно-что нельзя, которую Anthropic и называют конституцией. Соответственно суть подхода здесь в том, что цензоров учат на базе синтетических данных, сненерированных LLM на базе промпта с рубрикой.
Итак, исследователи ставят перед собой следующую задачу: защитить LLM от универсальных джейлбрейков – обратите внимание, не от любых, а от таких, которые стабильно добиваются от LLM недопустимого вывода в практически любом сценарии в рамках одной области знаний. Дополнительно они требуют от потенциального решения практической применимости с точки зрения задержек, вычислительной стоимости и доли ложноположительных срабатываний, а также возможности быстро адаптировать подход к новым угрозам и сферам.
Чтобы удовлетворить этим требованиям, решают использовать классификаторы, а классификаторам нужна обучающая выборка. Исследователи создают две рубрики – с безопасными темами и опасными темами, берут helpful-only модель (т.е. без элайнмента на безопасность) и просят ее сгенерировать промпты, соответствующие этим темам, а затем и ответы на эти промпты. Поверх этого применяется аугментация – парафраз, перевод, добавление джейлбрейков и сочетания подходов. На этих данных учатся классификаторы. Для ввода модель (Claude 3.5 Sonnet) файнтюнится на предсказание токена в продолжении фразы «Assistant: The dialog was harmful|not harmful». Для модерации вывода к этому добавляется логрег поверх логитов (?), которые обучаются вместе, при этом при обучении в качестве сигнала используется максимум по времени, который с определенным шедулингом подмешивается к NSP.
Обученный классификатор дают на растерзание любителям легкой наживы на HackerOne – за успешный джейлбрейк компания обещала 15 тысяч долларов. Чтобы получить деньги, нужно было создать такой промпт, который заставил бы Claude дать ответ на 10 разных вопросов о химическом оружии. Ответы оценивались как полные (аналогичные по детализации helpful-only модели), половинчатые (по оценке модели-ассессора дающей только часть сведений) или бесполезные. По оценкам исследователей, ред-тимеры потратили на обход модерации более 4 с половиной тысяч часов – без успеха. Ни один из джейлбрейков не оказался универсальным. Самый успешный из участников заставил модель дать полный ответ на 6 из 10 вопросов, причем разными джейлбрейками, самый удачный универсальный давал ответ на половину вопросов, девять – половинчатые ответы на более чем шесть вопросов. Это кажется очень крутым, но, меня лично смутила фраза в дизайне эксперимента: «При проектировании классификатора и выборе порогов мы отдавали приоритет устойчивости, поэтому FPR был достаточно высок: классификатор срабатывал на 44% трафика Claude[.]ai». Из забавного – часть ред-тимеров старались проэксплутарировать грейдер, заставляя модель давать очень длинные общие ответы, прямо как RL.
Mrinank Sharma et al., Anthropic. 2025
Статья, блог, демо
На прошлой неделе вышла достаточно громкая статья от Anthropic про защиту LLM-чат-ботов от джейлбрейков с помощью "конституционных классификаторов", т.е., выражаясь по-человечески, цензоров для вводов и выводов. Статья обещает падение успешности атак до менее полупроцента с пренебрежимо малым ростом FPR. Давайте посмотрим, в чем суть.
Для начала вспомним, откуда взялась конституция. Если помните, Anthropic активно применяет для элайнмента своих моделей подход под названием Constitutional AI сиречь RLAIF, суть которого в том, что вместо человека в RLHF фидбек модели по допустимости ее генераций дает сама модель. Определяет она допустимость с помощью рубрики что можно-что нельзя, которую Anthropic и называют конституцией. Соответственно суть подхода здесь в том, что цензоров учат на базе синтетических данных, сненерированных LLM на базе промпта с рубрикой.
Итак, исследователи ставят перед собой следующую задачу: защитить LLM от универсальных джейлбрейков – обратите внимание, не от любых, а от таких, которые стабильно добиваются от LLM недопустимого вывода в практически любом сценарии в рамках одной области знаний. Дополнительно они требуют от потенциального решения практической применимости с точки зрения задержек, вычислительной стоимости и доли ложноположительных срабатываний, а также возможности быстро адаптировать подход к новым угрозам и сферам.
Чтобы удовлетворить этим требованиям, решают использовать классификаторы, а классификаторам нужна обучающая выборка. Исследователи создают две рубрики – с безопасными темами и опасными темами, берут helpful-only модель (т.е. без элайнмента на безопасность) и просят ее сгенерировать промпты, соответствующие этим темам, а затем и ответы на эти промпты. Поверх этого применяется аугментация – парафраз, перевод, добавление джейлбрейков и сочетания подходов. На этих данных учатся классификаторы. Для ввода модель (Claude 3.5 Sonnet) файнтюнится на предсказание токена в продолжении фразы «Assistant: The dialog was harmful|not harmful». Для модерации вывода к этому добавляется логрег поверх логитов (?), которые обучаются вместе, при этом при обучении в качестве сигнала используется максимум по времени, который с определенным шедулингом подмешивается к NSP.
Обученный классификатор дают на растерзание любителям легкой наживы на HackerOne – за успешный джейлбрейк компания обещала 15 тысяч долларов. Чтобы получить деньги, нужно было создать такой промпт, который заставил бы Claude дать ответ на 10 разных вопросов о химическом оружии. Ответы оценивались как полные (аналогичные по детализации helpful-only модели), половинчатые (по оценке модели-ассессора дающей только часть сведений) или бесполезные. По оценкам исследователей, ред-тимеры потратили на обход модерации более 4 с половиной тысяч часов – без успеха. Ни один из джейлбрейков не оказался универсальным. Самый успешный из участников заставил модель дать полный ответ на 6 из 10 вопросов, причем разными джейлбрейками, самый удачный универсальный давал ответ на половину вопросов, девять – половинчатые ответы на более чем шесть вопросов. Это кажется очень крутым, но, меня лично смутила фраза в дизайне эксперимента: «При проектировании классификатора и выборе порогов мы отдавали приоритет устойчивости, поэтому FPR был достаточно высок: классификатор срабатывал на 44% трафика Claude[.]ai». Из забавного – часть ред-тимеров старались проэксплутарировать грейдер, заставляя модель давать очень длинные общие ответы, прямо как RL.
BY llm security и каланы



Share with your friend now:
group-telegram.com/llmsecurity/487