
Forwarded from rizzearch
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
помимо дипсика и квена, недавно успели еще китайцы выкатить очередную ллм - минимакс, уже по традиции которая является МоЕ + вводит гибрид софтмакс и линейного аттеншнов (кстати о махинациях с аттеншном мы уже ни раз писали)
при том второй аттеншн не абы какой, а лайтнинг (не тот слава Богу). в минимаксе используется первая версия, а почти одновременно с этой моделькой успела выйти и вторая версия
в чем вообще суть - вот у нас есть
softmax(Q @ K^T) @ V, где иннер продукт между запросами и ключами выдает матрицу seq_len x seq_len, что довольно много
→ приходит в голову идея линеаризовать аттеншн, то есть делаем просто из softmax(Q @ K^T) ~= phi(Q) @ phi(K^T) ⇒ [phi(Q) @ phi(K^T)] @ V, что можно переписать как из left product в right product
phi(Q) @ [ phi(K^T) @ V ], где не будем напрямую высчитывать seq_len x seq_len матрицу, а будет только hidden_dim x hidden_dim. profit?
не совсем, когда в дело приходит понятие каузальности, ибо тогда формула становится (phi убрал для удобства) снова left product
[Q @ K^T * causal_mask] @ V
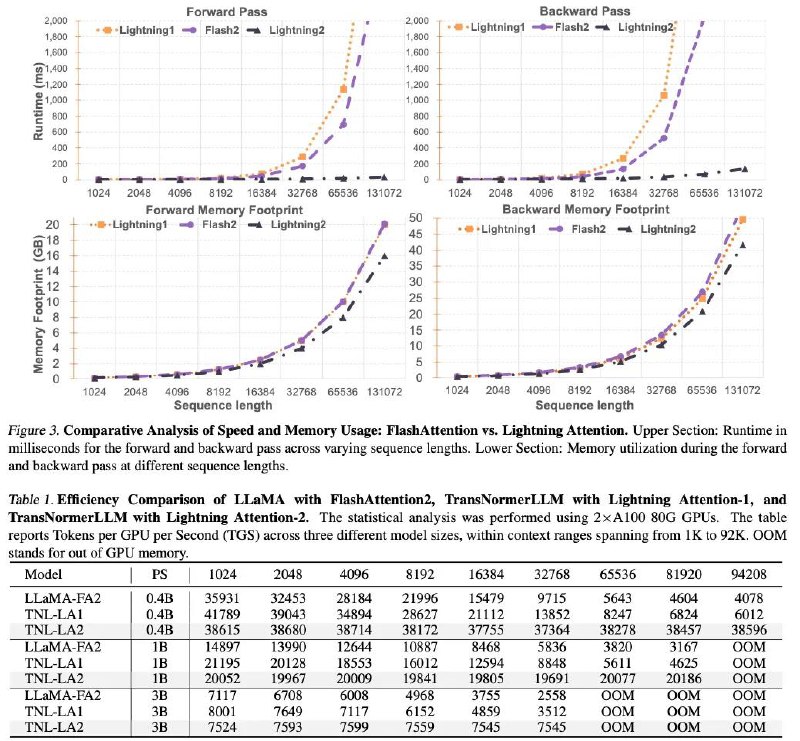
снова получаем seq_len x seq_len момент, это дело можно исправить алгоритмом Linear Attention Right Product (на предпоследней фотке), но тогда встревает кумулятивная сумма, которую не распараллелить
ну и авторы довольно красивое решение предлагают в виде того, что как раз и называется Lightning Attention
- во-первых, го вычислять аттеншн по блокам, по которым и будет идти цикл как обычно
- а в каждом блоке будем одновременно вычислять аттеншны и первым, и вторым способом: через left product с каузальной маской будет вычисляться intra block (как я понял потому что он находится рядом с диагональными элементами как раз, где и нужна каузальная маска), а через right product inter block (который/которые не соприкасаются с диагональю и можно без каузальной маски их использовать, да еще и этот блок вычислить можно через накопленную кумулятивную сумму KV), а в конце просто просуммируем, не забыв обновить KV
- тут получаем трейдофф между лево- и правоматричным умножениями, который еще и к тому же нетяжело под хардвейр оптимизировать - перетаскивать поочередно блоки между High Bandwidth Memory & SRAM (последняя картинка для иллюстрации отсюда, по всем правилам - чем больше по памяти вмещается, тем медленее работает)
вторая же версия отличается тем, что в каузальную маску добавляется гипер, контролирующий меру затухания информации между токенами (похожее делали в ретнете и второй мамбе), по формулам конечно присутствует не только в маске для сохранения контистенси в реккурентных выражениях (хоть этот вариант алгоритма был и в первой версии в аппендиксе)
реализовано все на тритоне, метод в принципе применим не только к их ТрансНормеру
👀 link, code
помимо дипсика и квена, недавно успели еще китайцы выкатить очередную ллм - минимакс, уже по традиции которая является МоЕ + вводит гибрид софтмакс и линейного аттеншнов (кстати о махинациях с аттеншном мы уже ни раз писали)
при том второй аттеншн не абы какой, а лайтнинг (не тот слава Богу). в минимаксе используется первая версия, а почти одновременно с этой моделькой успела выйти и вторая версия
в чем вообще суть - вот у нас есть
softmax(Q @ K^T) @ V, где иннер продукт между запросами и ключами выдает матрицу seq_len x seq_len, что довольно много
→ приходит в голову идея линеаризовать аттеншн, то есть делаем просто из softmax(Q @ K^T) ~= phi(Q) @ phi(K^T) ⇒ [phi(Q) @ phi(K^T)] @ V, что можно переписать как из left product в right product
phi(Q) @ [ phi(K^T) @ V ], где не будем напрямую высчитывать seq_len x seq_len матрицу, а будет только hidden_dim x hidden_dim. profit?
не совсем, когда в дело приходит понятие каузальности, ибо тогда формула становится (phi убрал для удобства) снова left product
[Q @ K^T * causal_mask] @ V
снова получаем seq_len x seq_len момент, это дело можно исправить алгоритмом Linear Attention Right Product (на предпоследней фотке), но тогда встревает кумулятивная сумма, которую не распараллелить
ну и авторы довольно красивое решение предлагают в виде того, что как раз и называется Lightning Attention
- во-первых, го вычислять аттеншн по блокам, по которым и будет идти цикл как обычно
- а в каждом блоке будем одновременно вычислять аттеншны и первым, и вторым способом: через left product с каузальной маской будет вычисляться intra block (как я понял потому что он находится рядом с диагональными элементами как раз, где и нужна каузальная маска), а через right product inter block (который/которые не соприкасаются с диагональю и можно без каузальной маски их использовать, да еще и этот блок вычислить можно через накопленную кумулятивную сумму KV), а в конце просто просуммируем, не забыв обновить KV
- тут получаем трейдофф между лево- и правоматричным умножениями, который еще и к тому же нетяжело под хардвейр оптимизировать - перетаскивать поочередно блоки между High Bandwidth Memory & SRAM (последняя картинка для иллюстрации отсюда, по всем правилам - чем больше по памяти вмещается, тем медленее работает)
вторая же версия отличается тем, что в каузальную маску добавляется гипер, контролирующий меру затухания информации между токенами (похожее делали в ретнете и второй мамбе), по формулам конечно присутствует не только в маске для сохранения контистенси в реккурентных выражениях (хоть этот вариант алгоритма был и в первой версии в аппендиксе)
реализовано все на тритоне, метод в принципе применим не только к их ТрансНормеру
👀 link, code
group-telegram.com/nlpwanderer/90
Create:
Last Update:
Last Update:
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
помимо дипсика и квена, недавно успели еще китайцы выкатить очередную ллм - минимакс, уже по традиции которая является МоЕ + вводит гибрид софтмакс и линейного аттеншнов (кстати о махинациях с аттеншном мы уже ни раз писали)
при том второй аттеншн не абы какой, а лайтнинг (не тот слава Богу). в минимаксе используется первая версия, а почти одновременно с этой моделькой успела выйти и вторая версия
в чем вообще суть - вот у нас есть
softmax(Q @ K^T) @ V, где иннер продукт между запросами и ключами выдает матрицу seq_len x seq_len, что довольно много
→ приходит в голову идея линеаризовать аттеншн, то есть делаем просто из softmax(Q @ K^T) ~= phi(Q) @ phi(K^T) ⇒ [phi(Q) @ phi(K^T)] @ V, что можно переписать как из left product в right product
phi(Q) @ [ phi(K^T) @ V ], где не будем напрямую высчитывать seq_len x seq_len матрицу, а будет только hidden_dim x hidden_dim. profit?
не совсем, когда в дело приходит понятие каузальности, ибо тогда формула становится (phi убрал для удобства) снова left product
[Q @ K^T * causal_mask] @ V
снова получаем seq_len x seq_len момент, это дело можно исправить алгоритмом Linear Attention Right Product (на предпоследней фотке), но тогда встревает кумулятивная сумма, которую не распараллелить
ну и авторы довольно красивое решение предлагают в виде того, что как раз и называется Lightning Attention
- во-первых, го вычислять аттеншн по блокам, по которым и будет идти цикл как обычно
- а в каждом блоке будем одновременно вычислять аттеншны и первым, и вторым способом: через left product с каузальной маской будет вычисляться intra block (как я понял потому что он находится рядом с диагональными элементами как раз, где и нужна каузальная маска), а через right product inter block (который/которые не соприкасаются с диагональю и можно без каузальной маски их использовать, да еще и этот блок вычислить можно через накопленную кумулятивную сумму KV), а в конце просто просуммируем, не забыв обновить KV
- тут получаем трейдофф между лево- и правоматричным умножениями, который еще и к тому же нетяжело под хардвейр оптимизировать - перетаскивать поочередно блоки между High Bandwidth Memory & SRAM (последняя картинка для иллюстрации отсюда, по всем правилам - чем больше по памяти вмещается, тем медленее работает)
вторая же версия отличается тем, что в каузальную маску добавляется гипер, контролирующий меру затухания информации между токенами (похожее делали в ретнете и второй мамбе), по формулам конечно присутствует не только в маске для сохранения контистенси в реккурентных выражениях (хоть этот вариант алгоритма был и в первой версии в аппендиксе)
реализовано все на тритоне, метод в принципе применим не только к их ТрансНормеру
👀 link, code
помимо дипсика и квена, недавно успели еще китайцы выкатить очередную ллм - минимакс, уже по традиции которая является МоЕ + вводит гибрид софтмакс и линейного аттеншнов (кстати о махинациях с аттеншном мы уже ни раз писали)
при том второй аттеншн не абы какой, а лайтнинг (не тот слава Богу). в минимаксе используется первая версия, а почти одновременно с этой моделькой успела выйти и вторая версия
в чем вообще суть - вот у нас есть
softmax(Q @ K^T) @ V, где иннер продукт между запросами и ключами выдает матрицу seq_len x seq_len, что довольно много
→ приходит в голову идея линеаризовать аттеншн, то есть делаем просто из softmax(Q @ K^T) ~= phi(Q) @ phi(K^T) ⇒ [phi(Q) @ phi(K^T)] @ V, что можно переписать как из left product в right product
phi(Q) @ [ phi(K^T) @ V ], где не будем напрямую высчитывать seq_len x seq_len матрицу, а будет только hidden_dim x hidden_dim. profit?
не совсем, когда в дело приходит понятие каузальности, ибо тогда формула становится (phi убрал для удобства) снова left product
[Q @ K^T * causal_mask] @ V
снова получаем seq_len x seq_len момент, это дело можно исправить алгоритмом Linear Attention Right Product (на предпоследней фотке), но тогда встревает кумулятивная сумма, которую не распараллелить
ну и авторы довольно красивое решение предлагают в виде того, что как раз и называется Lightning Attention
- во-первых, го вычислять аттеншн по блокам, по которым и будет идти цикл как обычно
- а в каждом блоке будем одновременно вычислять аттеншны и первым, и вторым способом: через left product с каузальной маской будет вычисляться intra block (как я понял потому что он находится рядом с диагональными элементами как раз, где и нужна каузальная маска), а через right product inter block (который/которые не соприкасаются с диагональю и можно без каузальной маски их использовать, да еще и этот блок вычислить можно через накопленную кумулятивную сумму KV), а в конце просто просуммируем, не забыв обновить KV
- тут получаем трейдофф между лево- и правоматричным умножениями, который еще и к тому же нетяжело под хардвейр оптимизировать - перетаскивать поочередно блоки между High Bandwidth Memory & SRAM (последняя картинка для иллюстрации отсюда, по всем правилам - чем больше по памяти вмещается, тем медленее работает)
вторая же версия отличается тем, что в каузальную маску добавляется гипер, контролирующий меру затухания информации между токенами (похожее делали в ретнете и второй мамбе), по формулам конечно присутствует не только в маске для сохранения контистенси в реккурентных выражениях (хоть этот вариант алгоритма был и в первой версии в аппендиксе)
реализовано все на тритоне, метод в принципе применим не только к их ТрансНормеру
👀 link, code
BY NLP Wanderer






Share with your friend now:
group-telegram.com/nlpwanderer/90