group-telegram.com/tech_priestess/2047
Last Update:
🎉 Тем временем, мы с коллегами выложили на arXiv новый 4-страничный препринт про применение Sparse AutoEncoders (SAE, разреженные автоэнкодеры) для детекции искусственно сгенерированных текстов 🎉 (чтобы подробно разобраться, как работают SAE, можно начать, например, отсюда: https://transformer-circuits.pub/2022/toy_model/index.html ; если же говорить вкратце, SAE - это один из способов извлечь более "распутанные" и интерпретируемые фичи из эмбеддингов LLM-ки). В процессе работы над исследованием к моим постоянным соавторам присоединились два новых: Антон ( https://www.group-telegram.com/abstractDL ) и его коллега Полина, которые очень помогли с экспериментами и текстом на финальных стадиях!
Сама же работа называется "Feature-Level Insights into Artificial Text Detection with Sparse Autoencoders" ( https://arxiv.org/abs/2503.03601 )
Мы взяли модель Gemma-2-2B, навесили на нее предобученный SAE (gemmascope-res-16k) и начали подавать на вход различные LLM-сгенерированные тексты. Далее мы:
а) Детектировали LLM-генерацию по фичам SAE (интересно, что качество такой детекции оказалось лучше, чем детекции по оригинальным эмбеддингам Gemma!);
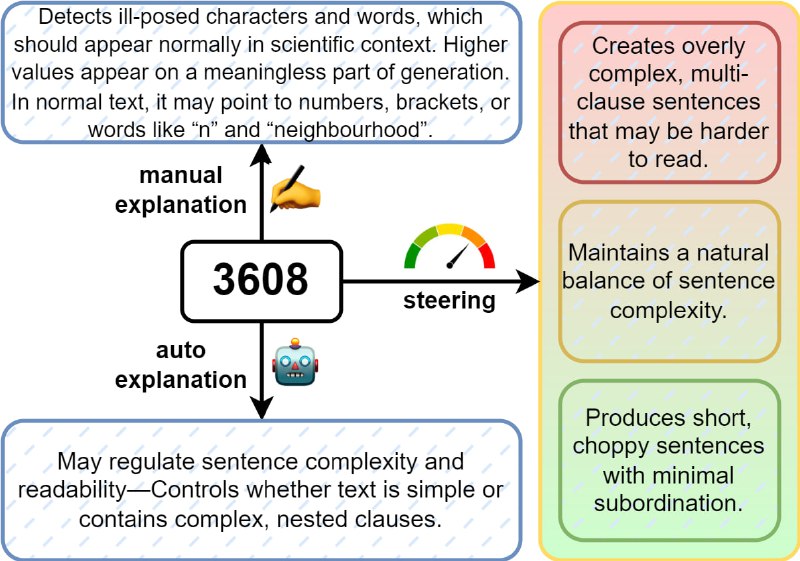
б) Отобрали 20 наиболее важных для детекции фичей с помощью бустинга и проанализировали их смысл, чтобы разобраться, какие именно отличия человеческих текстов и LLM-сгенерированных были "пойманы" этими фичами.
Анализ фичей проводился тремя основными способами: ручной интерпретацией (вручную смотрели, чем отличаются те тексты, на которых значение фичи низкое, от тех, на которых оно высокое), авто-интерпретацией (то же самое делала LLMка) и steering-ом. В последнем способе, в отличие от предыдущих, мы подавали на вход Gemma-2-2B не весь пример из датасета, а только промпт. Продолжение же мы генерировали с помощью самой Gemma-2-2B и при этом вектор, соответствующий выбранной фиче в эмбеддинге модели искусственно увеличивали или уменьшали, чтобы посмотреть, как это влияет на результат генерации. Далее GPT-4o автоматически интерпретировала, чем тексты, сгенерированные при уменьшенном значении нужного вектора, отличаются от текстов, сгенерированных при увеличенном значении (также про steering см. посты https://www.group-telegram.com/us/tech_priestess.com/1966 и https://www.group-telegram.com/us/tech_priestess.com/1967 ).
Результаты интерпретации в целом вполне соответствуют тем интуитивным представлением о сгенерированных текстах, которое обычно формируется у людей, которые часто пользуются LLMками (см. https://www.group-telegram.com/abstractDL/320 ): согласно нашему анализу, сгенерированные тексты чаще оказывались водянистыми, заумными, чрезмерно формальными, чрезмерно самоуверенными, а также чаще содержали повторения, чем человеческие тексты. Также мы описали несколько легко интерпретируемых признаков сгенерированности для отдельных доменов и моделей и другие наблюдения (о которых подробнее можно почитать в тексте самого препринта).
#объяснения_статей