
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
Ускоряем Hunyuan video fast еще в 2 раза на винде
Есть оригинальный Hunyuan-video-13B, он работает за 20-30 шагов (20-30 минут на видео), а есть дистиллированный Hunyuan fast, который работает за 6-10 шагов. 6 шагов мне не нравятся, 10 выглядят намного лучше (10 минут на генерацию 1 видео в 720p, 2 секунды, 48 кадров).
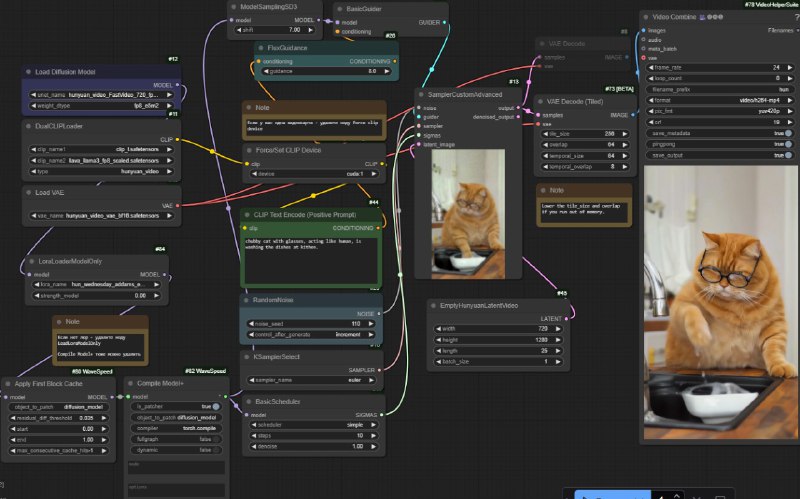
Недавно вышел waveSpeed, который ускоряет flux, LTX и hunyuan в 1.5-2 раза в comfy на видюхах 3000 серии и новее с помощью двух технологий: first-block-cache и torch-model-compile+. На моей 3090 прирост скорости относительно Hunyuan fast - в 2 раза, до 4.6 минуты на 1 видео. Поддерживается воркфлоу от comfyanonymous. Воркфлоу от kijai пока не поддерживается.
Hunyuan из коробки умеет nsfw. Верх довольно неплохой, низ слегка зацензурен, но лучше, чем в дефолтном flux. Но умельцы уже наделели 100+ лор для Hunyuan на civitai для разных nsfw поз, движений, персонажей и стилей (в https://civitai.com/models ставим 2 фильтра: LoRA + Hunyuan video).
Но compile+ ускоряет генерацию не всегда. Иногда torch compile занимает дополнительные 47 секунд. Перекомпилируется модель периодически, 1 раз в 2-3 генерации. Хз как побороть, скорее всего, vram мало, возможно, надо сделать меньше разрешение или количество кадров.
Предположу, что для работы Hunyuan хватит 32 GB RAM. У меня просто еще xtts+wav2lip в памяти висят. Если у вас в самом конце comfy вылетает без ошибок - снизьте разрешение или кол-во кадров.
Видел отзывы, что Hunyuan работает на 12 GB vram. Пока не тестил.
УСТАНОВКА
Нужен тритон и видюха 3000 серии или новее. 2000 серия nvidia не поддерживается. cuda toolkit 12.4+.
1. обновляем comfy через update_comfyui.bat
2. как установить тритон и sage-attention в комфи на винду:
https://www.reddit.com/r/StableDiffusion/comments/1h7hunp/how_to_run_hunyuanvideo_on_a_single_24gb_vram_card/
Первый шаг в этой инструкции пропускаем (установка нод kijai/ComfyUI-HunyuanVideoWrapper можно пропустить, мы будем использовать официальные ноды встроенные в комфи. Были отзывы, что в нодах от kijai пока не поддерживаются лоры при работе с first-block-cache). Выполняем пункты 2-4, включаем переводчик, если надо. Последние пункты 5-8 со скачиванием моделей не выполняем, мы скачаем другие, они меньше и быстрее.
3. Качаем clip_l.safetensors and llava_llama3_fp8_scaled и hunyuan_video_vae_bf16.safetensors: https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/
Качаем hunyuan fast: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors и кладем в diffusion_models
4. в run_nvidia_gpu.bat для запуска comfy надо добавить флаг
5. Устанавливаем custom node через comfyui manager -> install via GIT URL:
https://github.com/chengzeyi/Comfy-WaveSpeed
6. Hunyuan воркфлоу: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_fast_wave_speed_with_lora.json
Flux воркфлоу: https://github.com/Mozer/comfy_stuff/blob/main/workflows/flux_wave_speed.json
Советы:
- 1280x720, 720x1280, 544x960, 960x544 - рекомендуемые разрешения. В остальных могут быть артефакты.
- при малом количестве кадров анимация может работать хуже и с артефактами, рекомендую 25 и 49 кадров (1 и 2 сек)
- img2video пока нет, но разрабы обещают. Есть video2video и IPadapter2video от kijai.
- FLUX dev (bonus) -
1024x1024 20 steps
Прирост скорости во флаксе + waveSpeed составил 35%.
Во флаксе compile+ не работает на 3000 серии с flux-fp8, но работает с bf16, из-за этого прироста скорости не заметно. В hunyuan compile+ работает и дает прирост.
Есть оригинальный Hunyuan-video-13B, он работает за 20-30 шагов (20-30 минут на видео), а есть дистиллированный Hunyuan fast, который работает за 6-10 шагов. 6 шагов мне не нравятся, 10 выглядят намного лучше (10 минут на генерацию 1 видео в 720p, 2 секунды, 48 кадров).
Недавно вышел waveSpeed, который ускоряет flux, LTX и hunyuan в 1.5-2 раза в comfy на видюхах 3000 серии и новее с помощью двух технологий: first-block-cache и torch-model-compile+. На моей 3090 прирост скорости относительно Hunyuan fast - в 2 раза, до 4.6 минуты на 1 видео. Поддерживается воркфлоу от comfyanonymous. Воркфлоу от kijai пока не поддерживается.
Hunyuan из коробки умеет nsfw. Верх довольно неплохой, низ слегка зацензурен, но лучше, чем в дефолтном flux. Но умельцы уже наделели 100+ лор для Hunyuan на civitai для разных nsfw поз, движений, персонажей и стилей (в https://civitai.com/models ставим 2 фильтра: LoRA + Hunyuan video).
fast model, fp8:
48 frames, 48s/it, 10 min, 19 GB vram, 39 GB RAM
fast model, sage-attention, first-block-cache:
48 frames, 25s/it, 5.6 min, 20 GB vram, 38 GB RAM
sage-attention, first-block-cache, compile+:
25 frames, 10s/it, 2.1 min, 18 GB vram, 29 GB RAM
48 frames, 22s/it, 4.7 min, 20 GB vram, 38 GB RAM
61 frames, 34s/it, 6.7 min
65 frames - OOM
Но compile+ ускоряет генерацию не всегда. Иногда torch compile занимает дополнительные 47 секунд. Перекомпилируется модель периодически, 1 раз в 2-3 генерации. Хз как побороть, скорее всего, vram мало, возможно, надо сделать меньше разрешение или количество кадров.
Предположу, что для работы Hunyuan хватит 32 GB RAM. У меня просто еще xtts+wav2lip в памяти висят. Если у вас в самом конце comfy вылетает без ошибок - снизьте разрешение или кол-во кадров.
Видел отзывы, что Hunyuan работает на 12 GB vram. Пока не тестил.
УСТАНОВКА
Нужен тритон и видюха 3000 серии или новее. 2000 серия nvidia не поддерживается. cuda toolkit 12.4+.
1. обновляем comfy через update_comfyui.bat
2. как установить тритон и sage-attention в комфи на винду:
https://www.reddit.com/r/StableDiffusion/comments/1h7hunp/how_to_run_hunyuanvideo_on_a_single_24gb_vram_card/
Первый шаг в этой инструкции пропускаем (установка нод kijai/ComfyUI-HunyuanVideoWrapper можно пропустить, мы будем использовать официальные ноды встроенные в комфи. Были отзывы, что в нодах от kijai пока не поддерживаются лоры при работе с first-block-cache). Выполняем пункты 2-4, включаем переводчик, если надо. Последние пункты 5-8 со скачиванием моделей не выполняем, мы скачаем другие, они меньше и быстрее.
3. Качаем clip_l.safetensors and llava_llama3_fp8_scaled и hunyuan_video_vae_bf16.safetensors: https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/
Качаем hunyuan fast: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors и кладем в diffusion_models
4. в run_nvidia_gpu.bat для запуска comfy надо добавить флаг
--use-sage-attention вот так:.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build --use-sage-attention5. Устанавливаем custom node через comfyui manager -> install via GIT URL:
https://github.com/chengzeyi/Comfy-WaveSpeed
6. Hunyuan воркфлоу: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_fast_wave_speed_with_lora.json
Flux воркфлоу: https://github.com/Mozer/comfy_stuff/blob/main/workflows/flux_wave_speed.json
Советы:
- 1280x720, 720x1280, 544x960, 960x544 - рекомендуемые разрешения. В остальных могут быть артефакты.
- при малом количестве кадров анимация может работать хуже и с артефактами, рекомендую 25 и 49 кадров (1 и 2 сек)
- img2video пока нет, но разрабы обещают. Есть video2video и IPadapter2video от kijai.
- FLUX dev (bonus) -
1024x1024 20 steps
FLUX - 1.26s/it, 26 s.
FBC - 1.21it/s, 17 s.
FBC + compile+ - 1.20it/s, 17 s.
Прирост скорости во флаксе + waveSpeed составил 35%.
Во флаксе compile+ не работает на 3000 серии с flux-fp8, но работает с bf16, из-за этого прироста скорости не заметно. В hunyuan compile+ работает и дает прирост.
group-telegram.com/tensorbanana/1165
Create:
Last Update:
Last Update:
Ускоряем Hunyuan video fast еще в 2 раза на винде
Есть оригинальный Hunyuan-video-13B, он работает за 20-30 шагов (20-30 минут на видео), а есть дистиллированный Hunyuan fast, который работает за 6-10 шагов. 6 шагов мне не нравятся, 10 выглядят намного лучше (10 минут на генерацию 1 видео в 720p, 2 секунды, 48 кадров).
Недавно вышел waveSpeed, который ускоряет flux, LTX и hunyuan в 1.5-2 раза в comfy на видюхах 3000 серии и новее с помощью двух технологий: first-block-cache и torch-model-compile+. На моей 3090 прирост скорости относительно Hunyuan fast - в 2 раза, до 4.6 минуты на 1 видео. Поддерживается воркфлоу от comfyanonymous. Воркфлоу от kijai пока не поддерживается.
Hunyuan из коробки умеет nsfw. Верх довольно неплохой, низ слегка зацензурен, но лучше, чем в дефолтном flux. Но умельцы уже наделели 100+ лор для Hunyuan на civitai для разных nsfw поз, движений, персонажей и стилей (в https://civitai.com/models ставим 2 фильтра: LoRA + Hunyuan video).
Но compile+ ускоряет генерацию не всегда. Иногда torch compile занимает дополнительные 47 секунд. Перекомпилируется модель периодически, 1 раз в 2-3 генерации. Хз как побороть, скорее всего, vram мало, возможно, надо сделать меньше разрешение или количество кадров.
Предположу, что для работы Hunyuan хватит 32 GB RAM. У меня просто еще xtts+wav2lip в памяти висят. Если у вас в самом конце comfy вылетает без ошибок - снизьте разрешение или кол-во кадров.
Видел отзывы, что Hunyuan работает на 12 GB vram. Пока не тестил.
УСТАНОВКА
Нужен тритон и видюха 3000 серии или новее. 2000 серия nvidia не поддерживается. cuda toolkit 12.4+.
1. обновляем comfy через update_comfyui.bat
2. как установить тритон и sage-attention в комфи на винду:
https://www.reddit.com/r/StableDiffusion/comments/1h7hunp/how_to_run_hunyuanvideo_on_a_single_24gb_vram_card/
Первый шаг в этой инструкции пропускаем (установка нод kijai/ComfyUI-HunyuanVideoWrapper можно пропустить, мы будем использовать официальные ноды встроенные в комфи. Были отзывы, что в нодах от kijai пока не поддерживаются лоры при работе с first-block-cache). Выполняем пункты 2-4, включаем переводчик, если надо. Последние пункты 5-8 со скачиванием моделей не выполняем, мы скачаем другие, они меньше и быстрее.
3. Качаем clip_l.safetensors and llava_llama3_fp8_scaled и hunyuan_video_vae_bf16.safetensors: https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/
Качаем hunyuan fast: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors и кладем в diffusion_models
4. в run_nvidia_gpu.bat для запуска comfy надо добавить флаг
5. Устанавливаем custom node через comfyui manager -> install via GIT URL:
https://github.com/chengzeyi/Comfy-WaveSpeed
6. Hunyuan воркфлоу: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_fast_wave_speed_with_lora.json
Flux воркфлоу: https://github.com/Mozer/comfy_stuff/blob/main/workflows/flux_wave_speed.json
Советы:
- 1280x720, 720x1280, 544x960, 960x544 - рекомендуемые разрешения. В остальных могут быть артефакты.
- при малом количестве кадров анимация может работать хуже и с артефактами, рекомендую 25 и 49 кадров (1 и 2 сек)
- img2video пока нет, но разрабы обещают. Есть video2video и IPadapter2video от kijai.
- FLUX dev (bonus) -
1024x1024 20 steps
Прирост скорости во флаксе + waveSpeed составил 35%.
Во флаксе compile+ не работает на 3000 серии с flux-fp8, но работает с bf16, из-за этого прироста скорости не заметно. В hunyuan compile+ работает и дает прирост.
Есть оригинальный Hunyuan-video-13B, он работает за 20-30 шагов (20-30 минут на видео), а есть дистиллированный Hunyuan fast, который работает за 6-10 шагов. 6 шагов мне не нравятся, 10 выглядят намного лучше (10 минут на генерацию 1 видео в 720p, 2 секунды, 48 кадров).
Недавно вышел waveSpeed, который ускоряет flux, LTX и hunyuan в 1.5-2 раза в comfy на видюхах 3000 серии и новее с помощью двух технологий: first-block-cache и torch-model-compile+. На моей 3090 прирост скорости относительно Hunyuan fast - в 2 раза, до 4.6 минуты на 1 видео. Поддерживается воркфлоу от comfyanonymous. Воркфлоу от kijai пока не поддерживается.
Hunyuan из коробки умеет nsfw. Верх довольно неплохой, низ слегка зацензурен, но лучше, чем в дефолтном flux. Но умельцы уже наделели 100+ лор для Hunyuan на civitai для разных nsfw поз, движений, персонажей и стилей (в https://civitai.com/models ставим 2 фильтра: LoRA + Hunyuan video).
fast model, fp8:
48 frames, 48s/it, 10 min, 19 GB vram, 39 GB RAM
fast model, sage-attention, first-block-cache:
48 frames, 25s/it, 5.6 min, 20 GB vram, 38 GB RAM
sage-attention, first-block-cache, compile+:
25 frames, 10s/it, 2.1 min, 18 GB vram, 29 GB RAM
48 frames, 22s/it, 4.7 min, 20 GB vram, 38 GB RAM
61 frames, 34s/it, 6.7 min
65 frames - OOM
Но compile+ ускоряет генерацию не всегда. Иногда torch compile занимает дополнительные 47 секунд. Перекомпилируется модель периодически, 1 раз в 2-3 генерации. Хз как побороть, скорее всего, vram мало, возможно, надо сделать меньше разрешение или количество кадров.
Предположу, что для работы Hunyuan хватит 32 GB RAM. У меня просто еще xtts+wav2lip в памяти висят. Если у вас в самом конце comfy вылетает без ошибок - снизьте разрешение или кол-во кадров.
Видел отзывы, что Hunyuan работает на 12 GB vram. Пока не тестил.
УСТАНОВКА
Нужен тритон и видюха 3000 серии или новее. 2000 серия nvidia не поддерживается. cuda toolkit 12.4+.
1. обновляем comfy через update_comfyui.bat
2. как установить тритон и sage-attention в комфи на винду:
https://www.reddit.com/r/StableDiffusion/comments/1h7hunp/how_to_run_hunyuanvideo_on_a_single_24gb_vram_card/
Первый шаг в этой инструкции пропускаем (установка нод kijai/ComfyUI-HunyuanVideoWrapper можно пропустить, мы будем использовать официальные ноды встроенные в комфи. Были отзывы, что в нодах от kijai пока не поддерживаются лоры при работе с first-block-cache). Выполняем пункты 2-4, включаем переводчик, если надо. Последние пункты 5-8 со скачиванием моделей не выполняем, мы скачаем другие, они меньше и быстрее.
3. Качаем clip_l.safetensors and llava_llama3_fp8_scaled и hunyuan_video_vae_bf16.safetensors: https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/
Качаем hunyuan fast: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors и кладем в diffusion_models
4. в run_nvidia_gpu.bat для запуска comfy надо добавить флаг
--use-sage-attention вот так:.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build --use-sage-attention5. Устанавливаем custom node через comfyui manager -> install via GIT URL:
https://github.com/chengzeyi/Comfy-WaveSpeed
6. Hunyuan воркфлоу: https://github.com/Mozer/comfy_stuff/blob/main/workflows/hunyuan_fast_wave_speed_with_lora.json
Flux воркфлоу: https://github.com/Mozer/comfy_stuff/blob/main/workflows/flux_wave_speed.json
Советы:
- 1280x720, 720x1280, 544x960, 960x544 - рекомендуемые разрешения. В остальных могут быть артефакты.
- при малом количестве кадров анимация может работать хуже и с артефактами, рекомендую 25 и 49 кадров (1 и 2 сек)
- img2video пока нет, но разрабы обещают. Есть video2video и IPadapter2video от kijai.
- FLUX dev (bonus) -
1024x1024 20 steps
FLUX - 1.26s/it, 26 s.
FBC - 1.21it/s, 17 s.
FBC + compile+ - 1.20it/s, 17 s.
Прирост скорости во флаксе + waveSpeed составил 35%.
Во флаксе compile+ не работает на 3000 серии с flux-fp8, но работает с bf16, из-за этого прироста скорости не заметно. В hunyuan compile+ работает и дает прирост.
BY Tensor Banana
Share with your friend now:
group-telegram.com/tensorbanana/1165