
{kind=link}
group-telegram.com/artificial_stupid/401
Last Update:
#llm
Используем LLM для разметки (часть 2).
Продолжаем наш разговор о применении LLM для разметки данных.
Хоть я в прошлый раз и написал, что от LLM только одни плюсы. Но у пытливого читателя все равно будут вопросы, отчего тогда не перевелись все разметчики данных и великий скайнет не заменил эти кожаные мешки своими стальными братьями? И это весьма разумные вопросы.
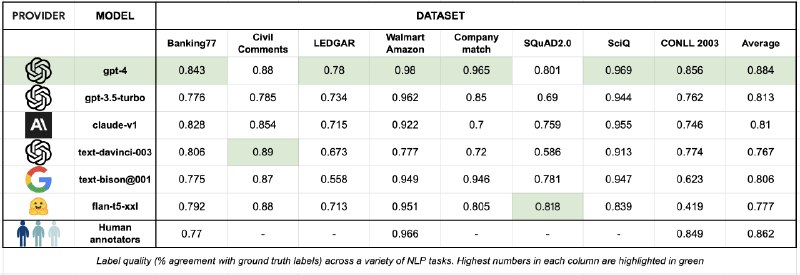
Начнем с того, что наши железные друзья все же понемногу наступают на пятки разметчикам данных. Но все еще не всегда обгоняют таковых. Впрочем, результаты весьма обнадеживающие, к посту прикладываю пример из статьи "LLMs can label data as well as humans, but 100x faster". Но пост все-таки в блоге компании, потому к результатам лучше относиться с некоторым подозрением.
И все же, частично мы можем передать разметку LLM. Но как мы это можем провернуть? Вот несколько вариантов:
1. Банальный. Давайте просто напишем промпт, вида "представь, что ты разметчик данных, реши следующую задачу [описание задачи]". Очевидно, такой подход будет страдать от всех bias'ов о возможных ошибок и галлюцинаций модели;
2. Корректирующий. Мы можем улучшить банальный подход, оставив в процессе разметки человека. Но теперь мы даем человеку вместо разметки, задачу проверки расставленных LLM меток. Вероятно, перепроверить за моделью будет проще. А, значит, нужно будет меньше ресурса разметчиков. При этом, такой подход будет качественнее банального, но менее ресурсоемким, чем классическая разметка людьми;
3. Развивающий. Помимо перепроверки человеком, мы можем добавить версионирование промптов и их постепенное улучшение. Для этого нам желательно иметь "золотой набор", об который мы могли бы оценивать качество разметки (считая, что люди дают наивысшее (или близкое к нему) качество).
При этом, даже в банальном варианте, мы можем применять различные техники промптинга (CoT, Few-shot и т.п.), чтобы улучшить результат разметки. Еще стоит помнить о валидации формата. В некоторых популярных библиотеках это уже встроенный функционал, но если мы делаем все сами, то лучше четко прописывать выходной формат данных и потом валидировать соответствие результата нашему формату.
Примеры построения промптов можно посмотреть здесь и здесь.
Что интересно. На самом деле, многие решения для разметки данных уже стараются имплементировать фичи для разметки с использованием LLM. Например, в Label Studio есть такой функционал (можно почитать про него здесь).
И, конечно, стоит упомянуть о минусах использования LLM в разметке данных:
1. Возможные смещения. Результаты могут сильно зависеть от того, на чем обучалась LLM (особенно, для русского языка);
2. Постоянная поддержка. Нужен постоянный процесс мониторинга качества результатов и внимание специалистов к самому процессу разметки;
3. Ограниченность текстовыми данными. Если мы используем LLM, то у нас есть ограничения типа используемых данных. Впрочем, достаточно быстро развиваются и мультимодальные модели, что может в будущем решить проблему.
И каковы же итоги?
Я бы предложил протестировать использование LLM в разметке в тех случаях, если у вас уже есть высокая потребность в разметке и достаточно большие затраты не нее. Скорее всего, в этом случае вы получите приемлемое качество (особенно, если не использовать самый банальный подход) за меньшую цену.
BY Artificial stupidity
Share with your friend now:
group-telegram.com/artificial_stupid/401