
На LMSYS Арену завезли контроль стиля, чтобы модели не могли "заманивать" юзеров красивым форматированием текста и длиной ответов
Гипотеза состоит в том, что пользователь может отдать свой голос за ту или иную модель, ориентируясь не только на содержание ответа, но и то, как он выглядит, а это нечестно. Поэтому разработчики на Арене подумали-подумали, да и выкатили функцию style control для разделения содержания и стиля текста.
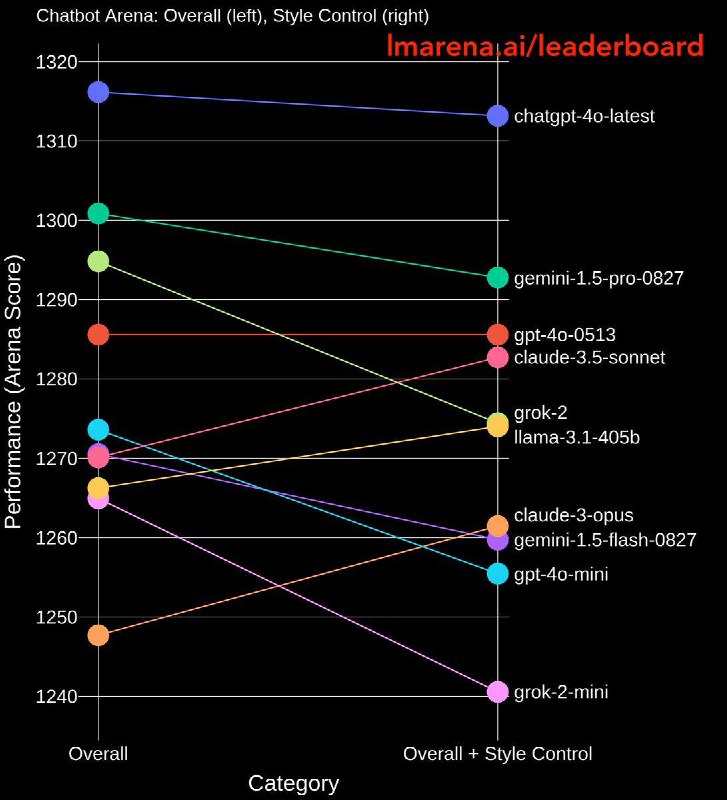
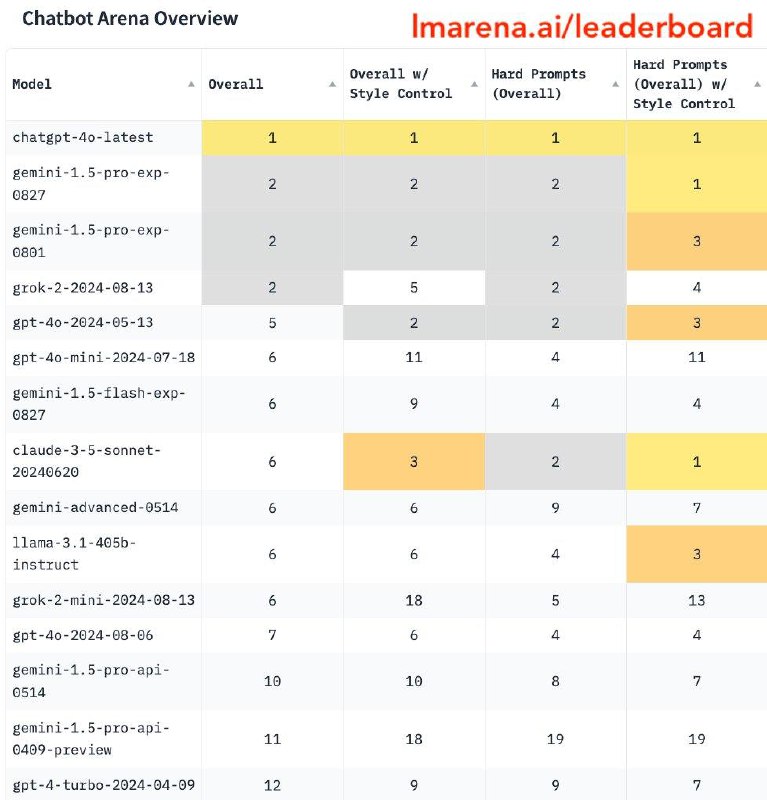
Оказалось, что когда текст оценивается без форматирования, некоторые модели заметно сдуваются. Например, GPT-4o-mini и Grok-2-mini оказались ниже всех, хотя до этого опережали Claude-3 Opus, Gemini-1.5-flash и других. А вот Claude 3.5 Sonnet, Opus, and Llama-3.1-405B наоборот сильно подскочили в рейтинге.
Как работает style control? Вообще, для сравнения двух моделей на основе предпочтений на Арене используется регрессия Брэдли-Терри. Чтобы контролировать стиль, теперь в нее в качестве независимых переменных добавились фичи длины и маркдауна (количество #, списков или болда в тексте). С их помощью можно оценить, насколько на предпочтения повлиял стиль.
Подход пока простой, и, конечно, может не учитывать некоторые корреляции. Но, как пишут разработчики, это "first step".
Гипотеза состоит в том, что пользователь может отдать свой голос за ту или иную модель, ориентируясь не только на содержание ответа, но и то, как он выглядит, а это нечестно. Поэтому разработчики на Арене подумали-подумали, да и выкатили функцию style control для разделения содержания и стиля текста.
Оказалось, что когда текст оценивается без форматирования, некоторые модели заметно сдуваются. Например, GPT-4o-mini и Grok-2-mini оказались ниже всех, хотя до этого опережали Claude-3 Opus, Gemini-1.5-flash и других. А вот Claude 3.5 Sonnet, Opus, and Llama-3.1-405B наоборот сильно подскочили в рейтинге.
Как работает style control? Вообще, для сравнения двух моделей на основе предпочтений на Арене используется регрессия Брэдли-Терри. Чтобы контролировать стиль, теперь в нее в качестве независимых переменных добавились фичи длины и маркдауна (количество #, списков или болда в тексте). С их помощью можно оценить, насколько на предпочтения повлиял стиль.
Подход пока простой, и, конечно, может не учитывать некоторые корреляции. Но, как пишут разработчики, это "first step".
group-telegram.com/data_secrets/4809
Create:
Last Update:
Last Update:
На LMSYS Арену завезли контроль стиля, чтобы модели не могли "заманивать" юзеров красивым форматированием текста и длиной ответов
Гипотеза состоит в том, что пользователь может отдать свой голос за ту или иную модель, ориентируясь не только на содержание ответа, но и то, как он выглядит, а это нечестно. Поэтому разработчики на Арене подумали-подумали, да и выкатили функцию style control для разделения содержания и стиля текста.
Оказалось, что когда текст оценивается без форматирования, некоторые модели заметно сдуваются. Например, GPT-4o-mini и Grok-2-mini оказались ниже всех, хотя до этого опережали Claude-3 Opus, Gemini-1.5-flash и других. А вот Claude 3.5 Sonnet, Opus, and Llama-3.1-405B наоборот сильно подскочили в рейтинге.
Как работает style control? Вообще, для сравнения двух моделей на основе предпочтений на Арене используется регрессия Брэдли-Терри. Чтобы контролировать стиль, теперь в нее в качестве независимых переменных добавились фичи длины и маркдауна (количество #, списков или болда в тексте). С их помощью можно оценить, насколько на предпочтения повлиял стиль.
Подход пока простой, и, конечно, может не учитывать некоторые корреляции. Но, как пишут разработчики, это "first step".
Гипотеза состоит в том, что пользователь может отдать свой голос за ту или иную модель, ориентируясь не только на содержание ответа, но и то, как он выглядит, а это нечестно. Поэтому разработчики на Арене подумали-подумали, да и выкатили функцию style control для разделения содержания и стиля текста.
Оказалось, что когда текст оценивается без форматирования, некоторые модели заметно сдуваются. Например, GPT-4o-mini и Grok-2-mini оказались ниже всех, хотя до этого опережали Claude-3 Opus, Gemini-1.5-flash и других. А вот Claude 3.5 Sonnet, Opus, and Llama-3.1-405B наоборот сильно подскочили в рейтинге.
Как работает style control? Вообще, для сравнения двух моделей на основе предпочтений на Арене используется регрессия Брэдли-Терри. Чтобы контролировать стиль, теперь в нее в качестве независимых переменных добавились фичи длины и маркдауна (количество #, списков или болда в тексте). С их помощью можно оценить, насколько на предпочтения повлиял стиль.
Подход пока простой, и, конечно, может не учитывать некоторые корреляции. Но, как пишут разработчики, это "first step".
BY Data Secrets
Share with your friend now:
group-telegram.com/data_secrets/4809