
group-telegram.com/def_model_train/1041
Last Update:
Mixture of A Million Experts
https://arxiv.org/abs/2407.04153
При виде названия статьи у вас наверное может возникнуть вопрос, а зачем вообще скейлиться до миллиона экспертов. На это автор
1. Feedforward слои занимают 2/3 параметров трансформера, при этом, значительно урезать их нельзя, так как в них хранятся знания модели (пруф). Поэтому можно сокращать число активных параметров при инференсе, создав вместого одного общего feedforward слоя несколько экспертов поменьше и активируя только нужные из них
2. В передыдущих работах было показано, что при compute optimal числе токенов повышение гранулярности (число активных араметров / размер одного эксперта) консистено повышает и способности модели, всегда при этом обгоняя dense модель с аналогичным числом параметров
В этой статье предлагется радикально повысить число экспертов буквально до миллиона, пожертвовав при этом их размером – каждый эксперт представляет из себя всего один нейрон. Выглядит алгоритм Parameter Efficient Expert Retrieval (PEER) целиком примерно так:
- Есть небольшая query network, которая преобразовывает входную последовательность на каком-нибудь слое в query vector
- У каждого эксперта есть свой product key (тоже обучаемый вектор)
- Выбирается top-k экспертов с самыми большими скалярными прозведениями между query vector и product key
- Эти скалярные произведения загоняются в софтмакс-функцию и используются как веса в линейной комбинации ответов всех k экспертов
- В финальной версии есть h независмых query networks, каждая их них выбирает свои top-k экспертов, и на выходе у нас получается сумма из h линейных комбинаций
Плюс такого подхода в том, что число активных параметров можно регулировать напрямую в зависимости от доступного компьюта, оно зависит только от выбора h и k. А интуицию, почему это работает лучше обычных dense feeedforward слоев, можно проследить, если мы возьмем k = 1, то есть ситуацию, где каждая query network будет выбирать всего один нейрон. Тогда получается, что мы просто законово соберем feedforward слой размера h, только он будет не один фиксированный на весь трансфомер блок, а свой для каждого входного текста
Еще одно потенциальный плюс этой архитектуры – это lifelong learning. Если мы можем замораживать старых экспертов и постоянно добавлять новых, то модель может обучаться на постоянном потоке новых данных. Вообще автор статьи как раз и заниматся в основном решением проблем lifelong learning и catastrophic forgetting, когда модель начинает забывать старую информацию, если ее начать обучать на чем-то новом. Так что видимо претензия статьи тут не столько в облегчении нагрузки на компьют и повышении перфоманса модели, сколько в том, что такая архитектура получается гораздо более гибкой, чем оригинальный трансформер, и позволяет нам адаптировать вычисления под каждый новый запрос
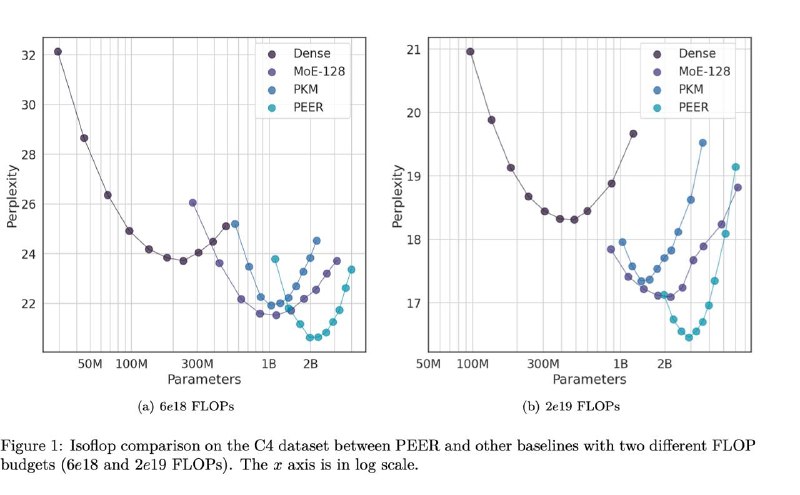
Тем не менее ситуация с компьютом тоже неплохо выглядит – на вот этих графиках видно, что с одинаковым лимитом на комьют, PEER получается вместить в себя гораздо больше параметров и получить за счет этого перплексию пониже
BY я обучала одну модель
Share with your friend now:
group-telegram.com/def_model_train/1041