
group-telegram.com/def_model_train/1064
Last Update:
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
https://arxiv.org/pdf/2504.20571
Очень интересная статья, не только своим основным клеймом, который и так сам по себе довольно удивителььный и неинтуитивный, но и такими же неожиданными выводами в аблейшенах.
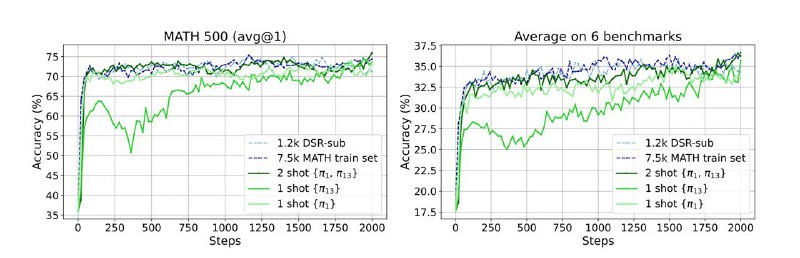
Как понятно из заголовка, модель тренируют с помощью обычного GRPO всего на одном примере. И качество на тесте действительно растет, при чем со временем оно сходится к качеству модели, которую обучали на датасете обычного размера в 7.5k наблюдений. К чести авторов, помимо просто качества на тесте они репортят еще и среднюю accuracy на 6 разных математических бенчмарках – там оно тоже растет.
При этом по графику видно, что изначально модель очевидно осуществляет reward hacking – то есть просто учится отвечать в правильном формате (здесь это ответ, заключенный в \boxed{}) – после этого точность значительно падает, и только где-то на 300-ом шаге начинает расти обратно, видимо, засчет реально выросших способностей к ризонингу
Как выбирать один единственный пример для обучения? Вообще можно взять рандомно и увидеть какой-то нетривиальный прирост качества (в статье 30+% для рандомного выбора). Но самый оптимальный в статье выбирали по historical accuracy. Модель тренировали несколько эпох на полном датасете и для каждого примера замеряли, может ли модель его решить в конце эпохи. Лучший пример в этом плане тот, где вариация accuracy во время тренировки самая большая. Мотивировано это тем, что для RL обучения очень важна вариация сигнала от реворда, и тут мы можем ожидать, что тренируясь на таком примере, реворд не будет константным (не будет ситуации, что пример каждую эпоху либо идеально решен, либо не решен вообще никогда).
Интересно, что в итоге лучший пример, который использовали авторы, 1) не сложный – модель без тернировки как правило может его решить вплоть до последнего шага, 2) имеет неправильный ground truth ответ – верным является решение 12.7, а в датасете стоит 12.8
Самый неожиданный клейм статья – феномен, который авторы назвали post-saturation generalization. Accuracy на тренировке как правило достигает 100% за первые 100 шагов обучения, но качество на тесте продолжает расти дальше, даже после 1500-ого шага. При этом, на тренировочном примере происходит полный оверфит: модель в какой-то момент начинает выдавать бессмысленную мешанину из токенов на смеси языков, посреди этого все равно выдает правильный ответ в \boxed{}, но на тестовых данных при этом продолжает отвечать нормальных связным текстом (!). Для SFT моделей я никогда ничего похожего не видела, и если этот феномен воспроизводится на других данных, то это очевидно огромное преимущество RL. Если оверфит на тренировочных данных не транслируется в плохое качество на тесте, то теоретически можно тренироваться на одном и том же датасете огромное количество раз, и модель продолжит учиться чему-то новому дальше. На этом фоне мне вспомнились заголовки из ноября 2023 о том, что алгроитм q*, который по слухам разрабатыл Суцкевер до ухода из OpenAI, должен был решить проблему заканчивающихся данных для обучения моделей. Получается, RL-ем действительно ее можно решить не только в том смысле, что это более эффективно, чем SFT, но и в том понимании, что здесь гораздо сложнее упереться в лимит по данным.
При чем, автооры отдельно показывают, что это не похоже на гроккинг, который может происходить при SFT-обучении. Там это являетcя эффектом регуляризации, а в этой статье эффект воспроизводится, если вообще никакую регуляризацию (weight decay) не включать в формулу лосса. И в целом можно добиться практически того же качества, если оставить только policy loss (который зависит от ревордов), и убрать и weight decay, и KL-дивергенцию, и entropy loss, которые дефолтно используются в GRPO.
BY я обучала одну модель
Share with your friend now:
group-telegram.com/def_model_train/1064