group-telegram.com/eboutdatascience/191
Last Update:
Уничтожение RAG - ML System Design
Давайте пойдем по базе из этого поста, ещё можете чекнуть этот пост с разбором MLSD для обучения LLM
Как отвечать на вопрос вопрос: «Постройка мне Retrieve модель в RAG»? Давайте разбираться!
Задача
Построить Retrieve модель для рага в e-commerce. Мы большой магазин навоза и нам надо рекомендовать товар по запросу пользователя в LLM. Напомню, retrieve модель - это штука, которая на основе запроса пользователя ищет подходящий контекст, чтобы засунуть в ЛЛМ.
Ограничения:
Ограничения: Минимальная задержка (<3–5 сек.), иначе пользователь ливнёт и поставит нашему сервису какашку
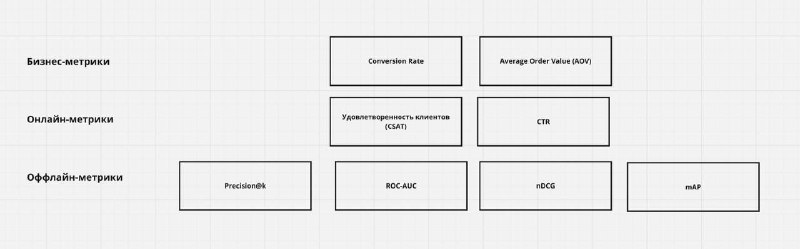
Бизнесовые метрики
Онлайн-метрики:
Оффлайн метрик:
Источник:
Мы большой магазин навоза и нам ну прям нужен RAG, то скорее всего мы доросли до того момента, когда у нас есть своя БД с описанием сортов навоза и их уникальных особенностей - 5 млн записей
Разметка:
Для Retrieve модели нам нужно получить данные: «запрос → релевантные документы». нанимаем копирайтера - Валюху, которая будет размечать нам данные. Но Валюха просит много рублей за свою работу, а мы не можем ей дать столько денег, то можем сделать начальную разметку с помощью TF-IDF или других BERT-like моделей.
Train/Test:
Случайно поделить на train/val/test (например, 70/15/15 - именно так мы должны разбивать навоз!)
BaseLine:
Сначала нужно сделать самое простое решение в качестве затычки. Нашей затычкой будет Elasticsearch на основе TF-IDF, который будет возвращать top-k=5 чанков. Чанк делим на 256 токенов или по структуре данных.
Норм решение для продажи навоза
Гибридный подход - TF-IDF & ANN + E5 & Cosine Similarity + Reranker
Заранее считаем все эмбеддинги BM25 и E5 и храним всё в БД - Faiss, ChromeDB.
Как обучать модели:
ReRanker:
X: (Query, Document) + доп. фичи (score BM25/ANN/E5, клики, цена, популярность и т.д.).
y: бинарная (релевант/нерелевант) или градуированная (0–5). Loss: Pairwise Ranking (LambdaRank), Cross-Entropy (если классификация) или Listwise (nDCG-based).
Количество семплов: 1000, Train/Test = 70/30%, Онлайн-метрика: CTR, CSAT
Итог:
Вот мы и построили базовый документ модели ретривы в RAG`е для магазина навоза, который ещё можно дорабатывать. Если он вам был полезен, то надеюсь вы им воспользуетесь на собесах по MLSD