
Scaling Diffusion Transformers to 16 B parameters with MoE
Китайцы месяц назад заскейлили DiT до 16.5 млрд параметров с помощью Mixture of Experts (MoE). Это могла бы быть самая большая DiT диффузия в опенсорсе на сегодняшней день, если бы веса 16.5B выложоли. Но шансы этого близки к нулю, т.к. я прождал месяц, а весов большой модели все еще нет.
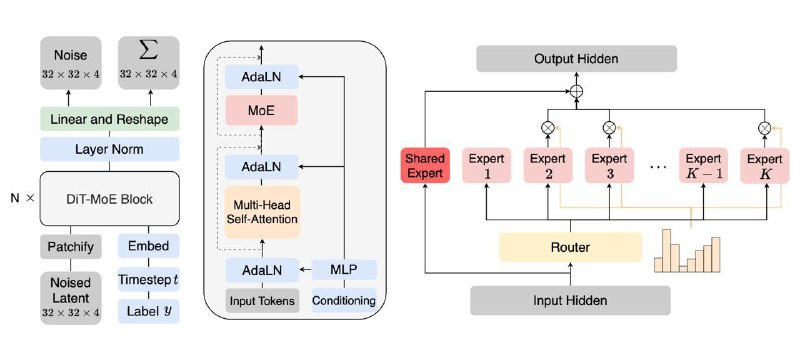
Экспертов вставили в каждый MLP блок, то есть вместо одного такого блока у нас теперь K параллельно, которые активируются в зависимости от входного токена. Во время инференса активны только 4 эксперта из К в каждый момент ( 2 "общих" эксперта активны всегда).
В чем профит использовать MoE?
- По сравнению с Dense моделью аналогичного размера (где у нас один жирный MLP блок), МоE позволяет условно распределить знания по отдельным экспертам, каждый из которых имеет меньший размер. За счет этого во время инференса мы можем активировать только часть экспертов и экономить на вычислениях.
- Выигрыша по памяти MoE в этом случае не дает - нам все равно нужно загружать сразу всех экспертов в память, т.к выбор экспертов происходит на уровне токенов.
- Если бы мы выбирали экспертов на уровне промпта или шага t, то можно было бы сэкономить и память. Но тут так не делают.
Тренят модель на:
– На 1.3M картинках из Imagenet и на синтетике.
– Нагенерили 5M картинок 512x512 для Imagenet классов с помощью SD3-2B и SDXL, а затем фильтранули клипом. Это для того, чтобы насытить данными жирную 16.5B модель, ведь 1.3M из Imagenet тут уже мало.
Результаты:
Картинки в статье выглядят так себе, наверное плохо черипикали. Но чего ожидать от генерации по классам на Imagenet. А по метрикам у них SOTA. Что ж, ждем аналогичную text-2-image модель.
В репе есть код тренировки (на DeepSpeed). Недавно добавили тренировку на основе Flow Matching, как это делают в Flux и SD3 - авторы пишут что таким методом модель быстрее сходится и дает лучшие результаты (это полезное замечание).
Вот веса моделей:
- B/2 с 8-ю экспертам (800 M, 12 блоков)
- G/2 с 16-ю экспертами (16.5 B, 40 блоков) - не выложили ха-ха.
@ai_newz
Китайцы месяц назад заскейлили DiT до 16.5 млрд параметров с помощью Mixture of Experts (MoE). Это могла бы быть самая большая DiT диффузия в опенсорсе на сегодняшней день, если бы веса 16.5B выложоли. Но шансы этого близки к нулю, т.к. я прождал месяц, а весов большой модели все еще нет.
Экспертов вставили в каждый MLP блок, то есть вместо одного такого блока у нас теперь K параллельно, которые активируются в зависимости от входного токена. Во время инференса активны только 4 эксперта из К в каждый момент ( 2 "общих" эксперта активны всегда).
В чем профит использовать MoE?
- По сравнению с Dense моделью аналогичного размера (где у нас один жирный MLP блок), МоE позволяет условно распределить знания по отдельным экспертам, каждый из которых имеет меньший размер. За счет этого во время инференса мы можем активировать только часть экспертов и экономить на вычислениях.
- Выигрыша по памяти MoE в этом случае не дает - нам все равно нужно загружать сразу всех экспертов в память, т.к выбор экспертов происходит на уровне токенов.
- Если бы мы выбирали экспертов на уровне промпта или шага t, то можно было бы сэкономить и память. Но тут так не делают.
Тренят модель на:
– На 1.3M картинках из Imagenet и на синтетике.
– Нагенерили 5M картинок 512x512 для Imagenet классов с помощью SD3-2B и SDXL, а затем фильтранули клипом. Это для того, чтобы насытить данными жирную 16.5B модель, ведь 1.3M из Imagenet тут уже мало.
Результаты:
Картинки в статье выглядят так себе, наверное плохо черипикали. Но чего ожидать от генерации по классам на Imagenet. А по метрикам у них SOTA. Что ж, ждем аналогичную text-2-image модель.
В репе есть код тренировки (на DeepSpeed). Недавно добавили тренировку на основе Flow Matching, как это делают в Flux и SD3 - авторы пишут что таким методом модель быстрее сходится и дает лучшие результаты (это полезное замечание).
Вот веса моделей:
- B/2 с 8-ю экспертам (800 M, 12 блоков)
- G/2 с 16-ю экспертами (16.5 B, 40 блоков) - не выложили ха-ха.
@ai_newz
group-telegram.com/ai_newz/3140
Create:
Last Update:
Last Update:
Scaling Diffusion Transformers to 16 B parameters with MoE
Китайцы месяц назад заскейлили DiT до 16.5 млрд параметров с помощью Mixture of Experts (MoE). Это могла бы быть самая большая DiT диффузия в опенсорсе на сегодняшней день, если бы веса 16.5B выложоли. Но шансы этого близки к нулю, т.к. я прождал месяц, а весов большой модели все еще нет.
Экспертов вставили в каждый MLP блок, то есть вместо одного такого блока у нас теперь K параллельно, которые активируются в зависимости от входного токена. Во время инференса активны только 4 эксперта из К в каждый момент ( 2 "общих" эксперта активны всегда).
В чем профит использовать MoE?
- По сравнению с Dense моделью аналогичного размера (где у нас один жирный MLP блок), МоE позволяет условно распределить знания по отдельным экспертам, каждый из которых имеет меньший размер. За счет этого во время инференса мы можем активировать только часть экспертов и экономить на вычислениях.
- Выигрыша по памяти MoE в этом случае не дает - нам все равно нужно загружать сразу всех экспертов в память, т.к выбор экспертов происходит на уровне токенов.
- Если бы мы выбирали экспертов на уровне промпта или шага t, то можно было бы сэкономить и память. Но тут так не делают.
Тренят модель на:
– На 1.3M картинках из Imagenet и на синтетике.
– Нагенерили 5M картинок 512x512 для Imagenet классов с помощью SD3-2B и SDXL, а затем фильтранули клипом. Это для того, чтобы насытить данными жирную 16.5B модель, ведь 1.3M из Imagenet тут уже мало.
Результаты:
Картинки в статье выглядят так себе, наверное плохо черипикали. Но чего ожидать от генерации по классам на Imagenet. А по метрикам у них SOTA. Что ж, ждем аналогичную text-2-image модель.
В репе есть код тренировки (на DeepSpeed). Недавно добавили тренировку на основе Flow Matching, как это делают в Flux и SD3 - авторы пишут что таким методом модель быстрее сходится и дает лучшие результаты (это полезное замечание).
Вот веса моделей:
- B/2 с 8-ю экспертам (800 M, 12 блоков)
- G/2 с 16-ю экспертами (16.5 B, 40 блоков) - не выложили ха-ха.
@ai_newz
Китайцы месяц назад заскейлили DiT до 16.5 млрд параметров с помощью Mixture of Experts (MoE). Это могла бы быть самая большая DiT диффузия в опенсорсе на сегодняшней день, если бы веса 16.5B выложоли. Но шансы этого близки к нулю, т.к. я прождал месяц, а весов большой модели все еще нет.
Экспертов вставили в каждый MLP блок, то есть вместо одного такого блока у нас теперь K параллельно, которые активируются в зависимости от входного токена. Во время инференса активны только 4 эксперта из К в каждый момент ( 2 "общих" эксперта активны всегда).
В чем профит использовать MoE?
- По сравнению с Dense моделью аналогичного размера (где у нас один жирный MLP блок), МоE позволяет условно распределить знания по отдельным экспертам, каждый из которых имеет меньший размер. За счет этого во время инференса мы можем активировать только часть экспертов и экономить на вычислениях.
- Выигрыша по памяти MoE в этом случае не дает - нам все равно нужно загружать сразу всех экспертов в память, т.к выбор экспертов происходит на уровне токенов.
- Если бы мы выбирали экспертов на уровне промпта или шага t, то можно было бы сэкономить и память. Но тут так не делают.
Тренят модель на:
– На 1.3M картинках из Imagenet и на синтетике.
– Нагенерили 5M картинок 512x512 для Imagenet классов с помощью SD3-2B и SDXL, а затем фильтранули клипом. Это для того, чтобы насытить данными жирную 16.5B модель, ведь 1.3M из Imagenet тут уже мало.
Результаты:
Картинки в статье выглядят так себе, наверное плохо черипикали. Но чего ожидать от генерации по классам на Imagenet. А по метрикам у них SOTA. Что ж, ждем аналогичную text-2-image модель.
В репе есть код тренировки (на DeepSpeed). Недавно добавили тренировку на основе Flow Matching, как это делают в Flux и SD3 - авторы пишут что таким методом модель быстрее сходится и дает лучшие результаты (это полезное замечание).
Вот веса моделей:
- B/2 с 8-ю экспертам (800 M, 12 блоков)
- G/2 с 16-ю экспертами (16.5 B, 40 блоков) - не выложили ха-ха.
@ai_newz
BY эйай ньюз


Share with your friend now:
group-telegram.com/ai_newz/3140