RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
#rag
Сегодня продолжу развивать тему RAG, поэтому подготовил для вас разбор свежей статьи RAPTOR. Этот подход устраняет проблему, когда LLM задают тематические вопросы, требующие полного знания целого документа или даже нескольких. Примером такого запроса может быть "Как именно князь Гвидон достиг своего могущества?". Любая система RAG извлечет множество релевантных фрагментов текста по данному запросу, однако они не дадут полной картины, потому что для этого нужно знать все содержание книги. И мы получаем проблему - чем больше фрагментов текста вы включаете в запрос, тем меньше вам нужен RAG.
Что же делает RAPTOR?🦖
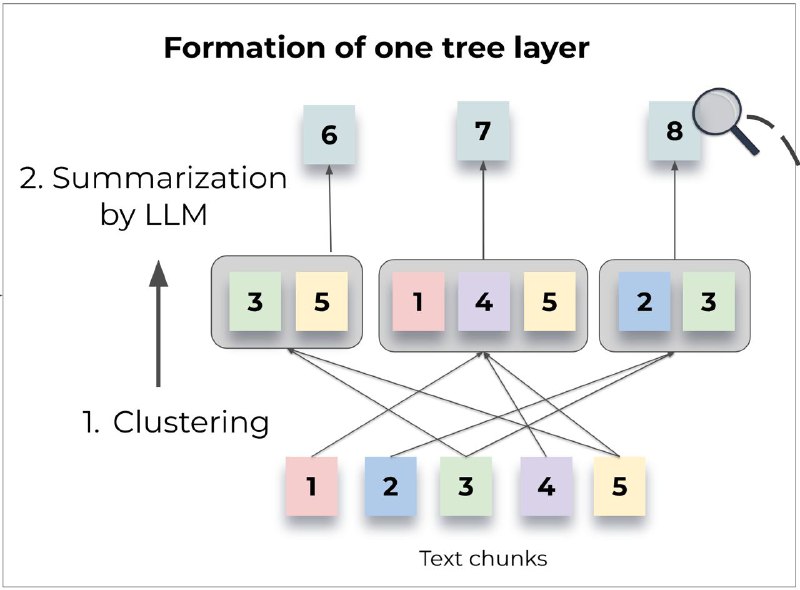
Вместо разделения документов на маленькие фрагменты и сохранения их в векторную БД для последующего извлечения, RAPTOR сначала их кластеризует, а после суммаризует каждый кластер с помощью LLM. Он повторяет этот процесс итерационно, пока не остается один, финальный фрагмент текста, в котором содержится вся информация документа. Все это извлекается в общих чертах с готовой суммаризированной информацией, а если необходимы факты, то можно опуститься на слой ниже и извлечь более детальное summary.
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
#rag
Сегодня продолжу развивать тему RAG, поэтому подготовил для вас разбор свежей статьи RAPTOR. Этот подход устраняет проблему, когда LLM задают тематические вопросы, требующие полного знания целого документа или даже нескольких. Примером такого запроса может быть "Как именно князь Гвидон достиг своего могущества?". Любая система RAG извлечет множество релевантных фрагментов текста по данному запросу, однако они не дадут полной картины, потому что для этого нужно знать все содержание книги. И мы получаем проблему - чем больше фрагментов текста вы включаете в запрос, тем меньше вам нужен RAG.
Что же делает RAPTOR?🦖
Вместо разделения документов на маленькие фрагменты и сохранения их в векторную БД для последующего извлечения, RAPTOR сначала их кластеризует, а после суммаризует каждый кластер с помощью LLM. Он повторяет этот процесс итерационно, пока не остается один, финальный фрагмент текста, в котором содержится вся информация документа. Все это извлекается в общих чертах с готовой суммаризированной информацией, а если необходимы факты, то можно опуститься на слой ниже и извлечь более детальное summary.
Asked about its stance on disinformation, Telegram spokesperson Remi Vaughn told AFP: "As noted by our CEO, the sheer volume of information being shared on channels makes it extremely difficult to verify, so it's important that users double-check what they read." In the past, it was noticed that through bulk SMSes, investors were induced to invest in or purchase the stocks of certain listed companies. DFR Lab sent the image through Microsoft Azure's Face Verification program and found that it was "highly unlikely" that the person in the second photo was the same as the first woman. The fact-checker Logically AI also found the claim to be false. The woman, Olena Kurilo, was also captured in a video after the airstrike and shown to have the injuries. Despite Telegram's origins, its approach to users' security has privacy advocates worried. At the start of 2018, the company attempted to launch an Initial Coin Offering (ICO) which would enable it to enable payments (and earn the cash that comes from doing so). The initial signals were promising, especially given Telegram’s user base is already fairly crypto-savvy. It raised an initial tranche of cash – worth more than a billion dollars – to help develop the coin before opening sales to the public. Unfortunately, third-party sales of coins bought in those initial fundraising rounds raised the ire of the SEC, which brought the hammer down on the whole operation. In 2020, officials ordered Telegram to pay a fine of $18.5 million and hand back much of the cash that it had raised.
from us