
group-telegram.com/knowledge_accumulator/221
Last Update:
Direct Preference Optimization: Your Language Model is Secretly a Reward Model [2023] - продолжаем LLM-ликбез
В прошлый раз мы разбирали стандартный RLHF, теперь давайте глянем на самого популярного из конкурентов и наследников, DPO. Авторы статьи говорят про RLHF следующее:
1) Reward model у нас не особо круто работает, особенно вне data distribution, поэтому полноценный её максимизатор будет плохим.
2) Существует ещё и проблема разнообразия, которого при идеальной максимизации не будет.
3) Наши RL методы сами по себе неидеальны и дороги в вычислении и реализации/отладке.
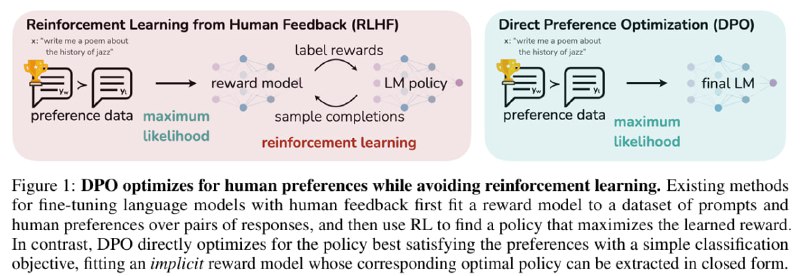
Вместо этого они хотят сформулировать задачу для обучения более простым образом. Давайте посмотрим, что из этого вышло.
Я не погружался в доказательства вывода, изложу своё понимание результата. Авторы замечают, что двухшаговая процедура из обучения Reward Model и затем RL можно переформулировать как одношаговую процедуру обучения на задачу с одной функцией ошибки и без дополнительной Reward Model.
Почему это возможно? Во-первых, в отличие от обычного RL, никаких настоящих наград не существует, а также нет никакого онлайн-взаимодействия со средой. У нас есть только зафиксированный датасет из троек [запрос ; хороший ответ ; плохой ответ].
На таких данных задачу можно формулировать по-разному, но в сущности они будут оптимизировать одно и то же - приближать модель к генерации хороших ответов, отдалять от генерации плохих ответов, при этом накладывая регуляризацию, чтобы модель далеко не убегала от инициализации. Одну из реализаций такой функции ошибки и предложили авторы статьи.
Практического опыта у меня нет, но в статье DPO вроде бы обходит RLHF на задачах. Чуваки в статье про Llama3 пишут, что используют DPO, так что, наверное, метод действительно лучше с учётом простоты реализации.
Замечу, что метод не решает обозначенные мною проблемы в посте про RLHF. Они вытекают из самих данных с человеческой разметкой, которые, во-первых, зафиксированы, а значит, не происходит GAN-подобного обучения, в котором данные пытаются "атаковать" модель в её слабые места и тем самым позволяя ей улучшаться, а, во-вторых, недостаточно велики и разнообразны, чтобы для решения поставленной задачи нужно было обучаться логическому размышлению и построению качественной картины мира.
Наверняка для RLHF/DPO придумали множество модификаций (в том числе всякие конструкции поверх LLM типа CoT), которые дают более крутой результат, но с таким соотношением пространства параметров и объёма данных решить задачу по-нормальному пока что вряд ли получится.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
group-telegram.com/knowledge_accumulator/221