
group-telegram.com/knowledge_accumulator/76
Last Update:
Tree of Thoughts [2023] - заставляем GPT исследовать чертоги своего разума
Поговорим о разных видах взаимодействия с LLM.
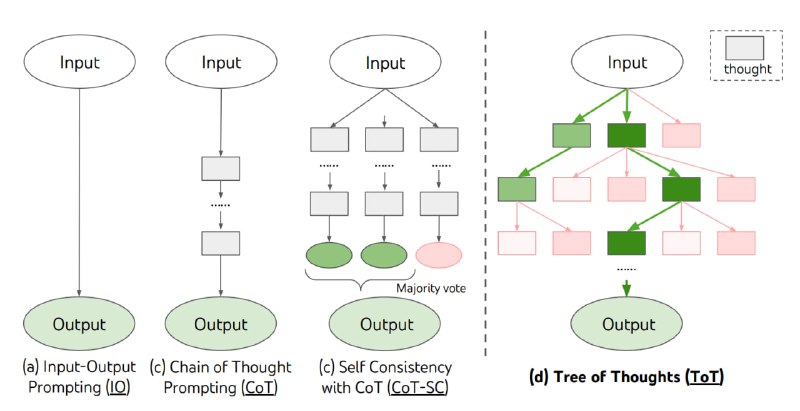
1) Базовый - составляем запрос с задачей в модель, получаем ответ на выходе
2) Chain of Thoughts - просим модель описывать пошагово ход решения задачи и рассуждения, и в конце ответ.
3) Iterative refinement - В течение нескольких запросов, просим модель критиковать и улучшать решение.
4) В случае, если нам нужен ответ на задачу, в которой применимо ансамблирование ответов, можно запускать предыдущие методы несколько раз и потом комбинировать их ответы в один финальный
В статье авторы изобретают ещё более хитрый способ заставить модель анализировать. Мы генерируем дерево мыслей. Корень - это изначальная задача, а дети любой вершины - это добавление к рассуждению какой-то мысли. Данное дерево можно растить, посылая в LLM запрос вида "придумай следующий шаг к решению", и подавая текущее состояние на вход.
Как оценивать качество вершины? Используем саму же LLM, веря, что модель с оценкой мыслей справляется лучше, чем с их генерацией. Таким образом, мы можем каким-нибудь алгоритмом обхода дерева с эвристиками искать в нём решение, в котором шаги решения будут высоко оценены моделью. Я думаю, что детали тут слишком быстро устареют и конкретный алгоритм нам не важен.
Что по результатам? Они не радикально выше, но, видимо, схема помогает решать некоторые задачи, в которых такое "поисковое мышление" уместно. Например, большой буст наблюдается в решении мини-кроссвордов, т.е. заполнении буквами сетку 5 на 5 согласно вопросам. Классический способ решения подразумевает как раз поиск по дереву, так что прирост от подхода ожидаем.
Возможно, что со временем мы придём к какой-то black-box абстракции над LLM, где схема промптинга станет частью скрытой от пользователя реализации, и подобные алгоритмы конструирования ответа станут весьма сложными. А вы как думали, сверхсильный-ИИ-GPT возьмёт и расскажет всё просто так?
Получасовой обзор статьи
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
group-telegram.com/knowledge_accumulator/76