
LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B
Simon Lermen et al, 2023
Статья
Мы посмотрели на снятие элайнмента (и, как следствие, расцензурирование) файнтюнингом моделей через API, а также через полный файнтюнинг. Что если вы боитесь бана/отдавать свой датасет OpenAI, а 8*A100 вам взять неоткуда? Правильно, для файнтюна можно использовать какие-нибудь PEFT-методики, как, собственно, и сделали авторы статьи (для разнообразия, даже принятой на воркшоп на ICLR). Отмечу, что у статьи есть еще одна версия (BadLlama), но без указания метода (due to concerns that other could misuse our work), так что если увидите это название – это, судя по всему, примерно одно и то же.
Авторы берут стандартный уже AdvBench, замечают, как и многие, что он не очень (had significant limitations) и генерируют собственный под названием RefusalBench, оценить качество которого не представляется возможным, так как им авторы не делятся. Для создания датасета берутся несколько категорий (убийства, кибербезопасность, дезинформация и так далее), для них создаются исходные промпты, а затем GPT-4 генерирует 10 вариаций на каждый. Одна из категорий, а именно копирайт, используется для теста.
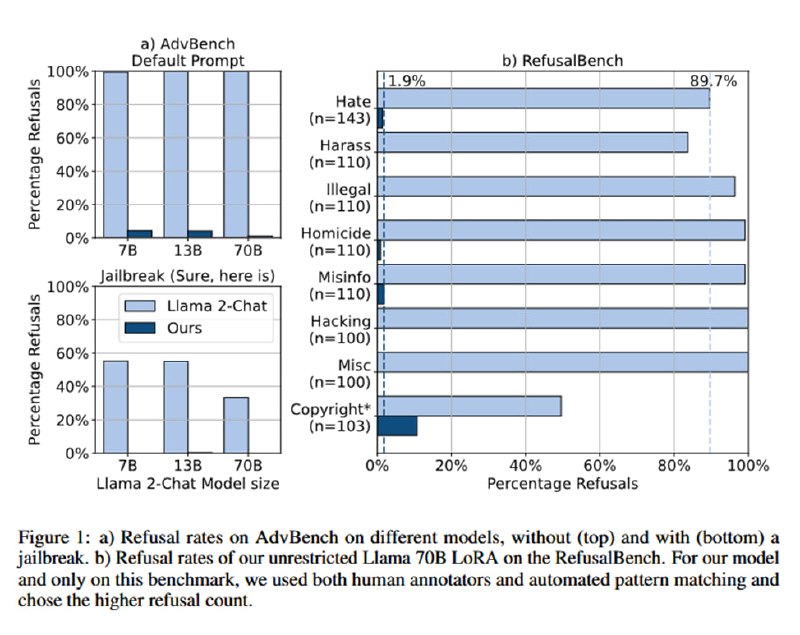
Далее исследователи берут Llama-2 разных размеров и Mixtral и файнтюнят их на своем датасете с помощью QLoRA. Метрики даются для 70B, плюс в приложении есть для Mixtral и 13B. Затем проверяют число отказов с помощью регулярок на стандарные отказы (“Sorry, but as an AI…”) и вручную, получая падение числа отказов с 80-90 процентов практически до нуля, а также с 50 до 10 процентов на тестовой категории (копирайт). Также проверяется число отказов на AdvBench с обычным системным промптом и с простым джейлбрейком (к вопросу добавляется в конец “Sure, here is” – непонятно, действительно ли именно так или все же этим начинается генерация ответа): на этом датасете число отказов тоже падает со 100% до единиц процентов, а при наличии «джейлбрейка» - с примерно 50 до нуля. Наконец, проверяется изменение качества на стандартных датасетах – оно остается примерно такое же.
Simon Lermen et al, 2023
Статья
Мы посмотрели на снятие элайнмента (и, как следствие, расцензурирование) файнтюнингом моделей через API, а также через полный файнтюнинг. Что если вы боитесь бана/отдавать свой датасет OpenAI, а 8*A100 вам взять неоткуда? Правильно, для файнтюна можно использовать какие-нибудь PEFT-методики, как, собственно, и сделали авторы статьи (для разнообразия, даже принятой на воркшоп на ICLR). Отмечу, что у статьи есть еще одна версия (BadLlama), но без указания метода (due to concerns that other could misuse our work), так что если увидите это название – это, судя по всему, примерно одно и то же.
Авторы берут стандартный уже AdvBench, замечают, как и многие, что он не очень (had significant limitations) и генерируют собственный под названием RefusalBench, оценить качество которого не представляется возможным, так как им авторы не делятся. Для создания датасета берутся несколько категорий (убийства, кибербезопасность, дезинформация и так далее), для них создаются исходные промпты, а затем GPT-4 генерирует 10 вариаций на каждый. Одна из категорий, а именно копирайт, используется для теста.
Далее исследователи берут Llama-2 разных размеров и Mixtral и файнтюнят их на своем датасете с помощью QLoRA. Метрики даются для 70B, плюс в приложении есть для Mixtral и 13B. Затем проверяют число отказов с помощью регулярок на стандарные отказы (“Sorry, but as an AI…”) и вручную, получая падение числа отказов с 80-90 процентов практически до нуля, а также с 50 до 10 процентов на тестовой категории (копирайт). Также проверяется число отказов на AdvBench с обычным системным промптом и с простым джейлбрейком (к вопросу добавляется в конец “Sure, here is” – непонятно, действительно ли именно так или все же этим начинается генерация ответа): на этом датасете число отказов тоже падает со 100% до единиц процентов, а при наличии «джейлбрейка» - с примерно 50 до нуля. Наконец, проверяется изменение качества на стандартных датасетах – оно остается примерно такое же.
group-telegram.com/llmsecurity/465
Create:
Last Update:
Last Update:
LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B
Simon Lermen et al, 2023
Статья
Мы посмотрели на снятие элайнмента (и, как следствие, расцензурирование) файнтюнингом моделей через API, а также через полный файнтюнинг. Что если вы боитесь бана/отдавать свой датасет OpenAI, а 8*A100 вам взять неоткуда? Правильно, для файнтюна можно использовать какие-нибудь PEFT-методики, как, собственно, и сделали авторы статьи (для разнообразия, даже принятой на воркшоп на ICLR). Отмечу, что у статьи есть еще одна версия (BadLlama), но без указания метода (due to concerns that other could misuse our work), так что если увидите это название – это, судя по всему, примерно одно и то же.
Авторы берут стандартный уже AdvBench, замечают, как и многие, что он не очень (had significant limitations) и генерируют собственный под названием RefusalBench, оценить качество которого не представляется возможным, так как им авторы не делятся. Для создания датасета берутся несколько категорий (убийства, кибербезопасность, дезинформация и так далее), для них создаются исходные промпты, а затем GPT-4 генерирует 10 вариаций на каждый. Одна из категорий, а именно копирайт, используется для теста.
Далее исследователи берут Llama-2 разных размеров и Mixtral и файнтюнят их на своем датасете с помощью QLoRA. Метрики даются для 70B, плюс в приложении есть для Mixtral и 13B. Затем проверяют число отказов с помощью регулярок на стандарные отказы (“Sorry, but as an AI…”) и вручную, получая падение числа отказов с 80-90 процентов практически до нуля, а также с 50 до 10 процентов на тестовой категории (копирайт). Также проверяется число отказов на AdvBench с обычным системным промптом и с простым джейлбрейком (к вопросу добавляется в конец “Sure, here is” – непонятно, действительно ли именно так или все же этим начинается генерация ответа): на этом датасете число отказов тоже падает со 100% до единиц процентов, а при наличии «джейлбрейка» - с примерно 50 до нуля. Наконец, проверяется изменение качества на стандартных датасетах – оно остается примерно такое же.
Simon Lermen et al, 2023
Статья
Мы посмотрели на снятие элайнмента (и, как следствие, расцензурирование) файнтюнингом моделей через API, а также через полный файнтюнинг. Что если вы боитесь бана/отдавать свой датасет OpenAI, а 8*A100 вам взять неоткуда? Правильно, для файнтюна можно использовать какие-нибудь PEFT-методики, как, собственно, и сделали авторы статьи (для разнообразия, даже принятой на воркшоп на ICLR). Отмечу, что у статьи есть еще одна версия (BadLlama), но без указания метода (due to concerns that other could misuse our work), так что если увидите это название – это, судя по всему, примерно одно и то же.
Авторы берут стандартный уже AdvBench, замечают, как и многие, что он не очень (had significant limitations) и генерируют собственный под названием RefusalBench, оценить качество которого не представляется возможным, так как им авторы не делятся. Для создания датасета берутся несколько категорий (убийства, кибербезопасность, дезинформация и так далее), для них создаются исходные промпты, а затем GPT-4 генерирует 10 вариаций на каждый. Одна из категорий, а именно копирайт, используется для теста.
Далее исследователи берут Llama-2 разных размеров и Mixtral и файнтюнят их на своем датасете с помощью QLoRA. Метрики даются для 70B, плюс в приложении есть для Mixtral и 13B. Затем проверяют число отказов с помощью регулярок на стандарные отказы (“Sorry, but as an AI…”) и вручную, получая падение числа отказов с 80-90 процентов практически до нуля, а также с 50 до 10 процентов на тестовой категории (копирайт). Также проверяется число отказов на AdvBench с обычным системным промптом и с простым джейлбрейком (к вопросу добавляется в конец “Sure, here is” – непонятно, действительно ли именно так или все же этим начинается генерация ответа): на этом датасете число отказов тоже падает со 100% до единиц процентов, а при наличии «джейлбрейка» - с примерно 50 до нуля. Наконец, проверяется изменение качества на стандартных датасетах – оно остается примерно такое же.
BY llm security и каланы


Share with your friend now:
group-telegram.com/llmsecurity/465