🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
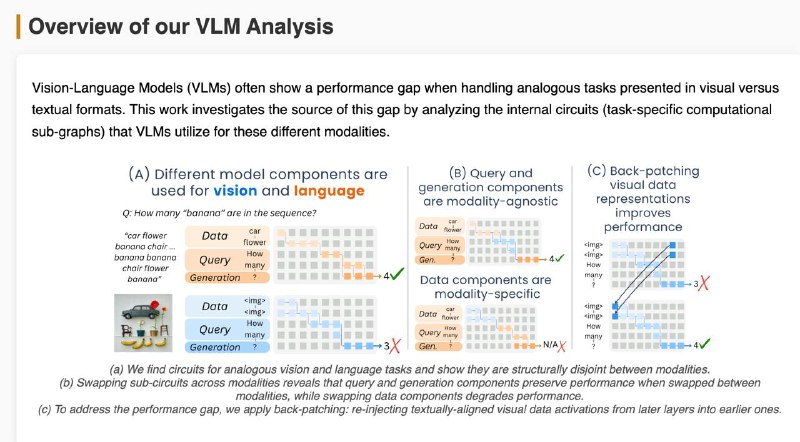
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
The Dow Jones Industrial Average fell 230 points, or 0.7%. Meanwhile, the S&P 500 and the Nasdaq Composite dropped 1.3% and 2.2%, respectively. All three indexes began the day with gains before selling off. The picture was mixed overseas. Hong Kong’s Hang Seng Index fell 1.6%, under pressure from U.S. regulatory scrutiny on New York-listed Chinese companies. Stocks were more buoyant in Europe, where Frankfurt’s DAX surged 1.4%. This ability to mix the public and the private, as well as the ability to use bots to engage with users has proved to be problematic. In early 2021, a database selling phone numbers pulled from Facebook was selling numbers for $20 per lookup. Similarly, security researchers found a network of deepfake bots on the platform that were generating images of people submitted by users to create non-consensual imagery, some of which involved children. Additionally, investors are often instructed to deposit monies into personal bank accounts of individuals who claim to represent a legitimate entity, and/or into an unrelated corporate account. To lend credence and to lure unsuspecting victims, perpetrators usually claim that their entity and/or the investment schemes are approved by financial authorities. Apparently upbeat developments in Russia's discussions with Ukraine helped at least temporarily send investors back into risk assets. Russian President Vladimir Putin said during a meeting with his Belarusian counterpart Alexander Lukashenko that there were "certain positive developments" occurring in the talks with Ukraine, according to a transcript of their meeting. Putin added that discussions were happening "almost on a daily basis."
from us