
Доброе утро, дорогие девочки 💋 и фембойчики 💅. Спешу поделиться радостной новостью: вчера я выложила на архив новый препринт (short paper), в написании которого принимала участие - Quantifying Logical Consistency in Transformers via Query-Key Alignment: https://arxiv.org/abs/2502.17017 .
Статья посвящена анализу того, как разные головы внимания LLMок реагируют на логические задачки. Главный прием, который в ней используется, изображен на рис. 1 и аналогичен приему из нашей с коллегами статьи про использование Query-Key Alignment для MCQA (часть 1, часть 2). Мы подаем на вход модели текст логической задачки вместе с вариантом ответа "true" и считаем скалярное произведение токена "true" из Query на выбранной голове внимания, на последний токен перед словом "Answer:" из Key на той же голове внимания. Получается одно число. Далее то же самое повторяется для варианта ответа "false". Получается второе число. Если первое число больше второго, то мы считаем, что голова выбрала вариант "true", а если наоборот, то "false" (в некоторых задачах более уместно вместо "true" и "false" использовать "yes" и "no", но принцип остается таким же). Таким образом можно проэкзаменовать каждую голову внимания и посмотреть, насколько хорошо из её query и key извлекаются правильные ответы (условно говоря, насколько хорошо голова "решает" логические задачки).
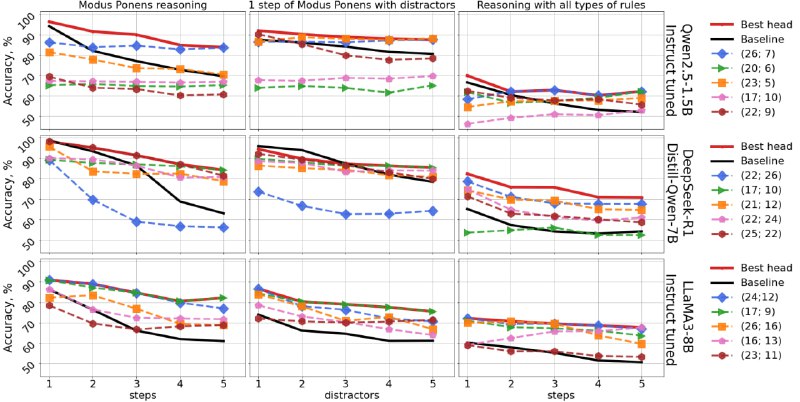
Задачки различались по степени сложности: во-первых, по количеству логических шагов, которые нужно предпринять для нахождения ответа ("steps" на рис. 2), а во-вторых, по количеству нерелевантных, шумных элементов в условии ("distractors" на рис. 2).
В статье было проанализировано много разных моделей (от 1.5B до 70B), и везде нашлись головы, которые "решают" сложные (5 шагов/5 дистракторов) задачки лучше, чем сама модель (если ответ модели оценивать по логитам, аналогично тому, как это делается в MCQA задачах). Более того, часть таких "хороших" голов, отобранных на валидационной выборке одного датасета, сохраняет высокое качество и на других датасетах, являясь более-менее универсальными. Мы выдвигаем гипотезу, что именно эти головы могут отвечать за логические рассуждения в модели.
Этот феномен аналогичен тому, что происходит в MCQA задачах (см. ссылки на разбор статьи выше): модель находит правильный ответ на задачу/вопрос где-то на промежуточных слоях, но этот ответ, по каким-то причинам, не всегда доходит до финального слоя. При чем, что интересно, чем сложнее задача, тем чаще правильный ответ не доходит до выхода. А это значит, что все рассмотренные модели не полностью раскрывают свой потенциал и имеют пространство для улучшения.
#объяснения_статей
Статья посвящена анализу того, как разные головы внимания LLMок реагируют на логические задачки. Главный прием, который в ней используется, изображен на рис. 1 и аналогичен приему из нашей с коллегами статьи про использование Query-Key Alignment для MCQA (часть 1, часть 2). Мы подаем на вход модели текст логической задачки вместе с вариантом ответа "true" и считаем скалярное произведение токена "true" из Query на выбранной голове внимания, на последний токен перед словом "Answer:" из Key на той же голове внимания. Получается одно число. Далее то же самое повторяется для варианта ответа "false". Получается второе число. Если первое число больше второго, то мы считаем, что голова выбрала вариант "true", а если наоборот, то "false" (в некоторых задачах более уместно вместо "true" и "false" использовать "yes" и "no", но принцип остается таким же). Таким образом можно проэкзаменовать каждую голову внимания и посмотреть, насколько хорошо из её query и key извлекаются правильные ответы (условно говоря, насколько хорошо голова "решает" логические задачки).
Задачки различались по степени сложности: во-первых, по количеству логических шагов, которые нужно предпринять для нахождения ответа ("steps" на рис. 2), а во-вторых, по количеству нерелевантных, шумных элементов в условии ("distractors" на рис. 2).
В статье было проанализировано много разных моделей (от 1.5B до 70B), и везде нашлись головы, которые "решают" сложные (5 шагов/5 дистракторов) задачки лучше, чем сама модель (если ответ модели оценивать по логитам, аналогично тому, как это делается в MCQA задачах). Более того, часть таких "хороших" голов, отобранных на валидационной выборке одного датасета, сохраняет высокое качество и на других датасетах, являясь более-менее универсальными. Мы выдвигаем гипотезу, что именно эти головы могут отвечать за логические рассуждения в модели.
Этот феномен аналогичен тому, что происходит в MCQA задачах (см. ссылки на разбор статьи выше): модель находит правильный ответ на задачу/вопрос где-то на промежуточных слоях, но этот ответ, по каким-то причинам, не всегда доходит до финального слоя. При чем, что интересно, чем сложнее задача, тем чаще правильный ответ не доходит до выхода. А это значит, что все рассмотренные модели не полностью раскрывают свой потенциал и имеют пространство для улучшения.
#объяснения_статей
group-telegram.com/tech_priestess/2034
Create:
Last Update:
Last Update:
Доброе утро, дорогие девочки 💋 и фембойчики 💅. Спешу поделиться радостной новостью: вчера я выложила на архив новый препринт (short paper), в написании которого принимала участие - Quantifying Logical Consistency in Transformers via Query-Key Alignment: https://arxiv.org/abs/2502.17017 .
Статья посвящена анализу того, как разные головы внимания LLMок реагируют на логические задачки. Главный прием, который в ней используется, изображен на рис. 1 и аналогичен приему из нашей с коллегами статьи про использование Query-Key Alignment для MCQA (часть 1, часть 2). Мы подаем на вход модели текст логической задачки вместе с вариантом ответа "true" и считаем скалярное произведение токена "true" из Query на выбранной голове внимания, на последний токен перед словом "Answer:" из Key на той же голове внимания. Получается одно число. Далее то же самое повторяется для варианта ответа "false". Получается второе число. Если первое число больше второго, то мы считаем, что голова выбрала вариант "true", а если наоборот, то "false" (в некоторых задачах более уместно вместо "true" и "false" использовать "yes" и "no", но принцип остается таким же). Таким образом можно проэкзаменовать каждую голову внимания и посмотреть, насколько хорошо из её query и key извлекаются правильные ответы (условно говоря, насколько хорошо голова "решает" логические задачки).
Задачки различались по степени сложности: во-первых, по количеству логических шагов, которые нужно предпринять для нахождения ответа ("steps" на рис. 2), а во-вторых, по количеству нерелевантных, шумных элементов в условии ("distractors" на рис. 2).
В статье было проанализировано много разных моделей (от 1.5B до 70B), и везде нашлись головы, которые "решают" сложные (5 шагов/5 дистракторов) задачки лучше, чем сама модель (если ответ модели оценивать по логитам, аналогично тому, как это делается в MCQA задачах). Более того, часть таких "хороших" голов, отобранных на валидационной выборке одного датасета, сохраняет высокое качество и на других датасетах, являясь более-менее универсальными. Мы выдвигаем гипотезу, что именно эти головы могут отвечать за логические рассуждения в модели.
Этот феномен аналогичен тому, что происходит в MCQA задачах (см. ссылки на разбор статьи выше): модель находит правильный ответ на задачу/вопрос где-то на промежуточных слоях, но этот ответ, по каким-то причинам, не всегда доходит до финального слоя. При чем, что интересно, чем сложнее задача, тем чаще правильный ответ не доходит до выхода. А это значит, что все рассмотренные модели не полностью раскрывают свой потенциал и имеют пространство для улучшения.
#объяснения_статей
Статья посвящена анализу того, как разные головы внимания LLMок реагируют на логические задачки. Главный прием, который в ней используется, изображен на рис. 1 и аналогичен приему из нашей с коллегами статьи про использование Query-Key Alignment для MCQA (часть 1, часть 2). Мы подаем на вход модели текст логической задачки вместе с вариантом ответа "true" и считаем скалярное произведение токена "true" из Query на выбранной голове внимания, на последний токен перед словом "Answer:" из Key на той же голове внимания. Получается одно число. Далее то же самое повторяется для варианта ответа "false". Получается второе число. Если первое число больше второго, то мы считаем, что голова выбрала вариант "true", а если наоборот, то "false" (в некоторых задачах более уместно вместо "true" и "false" использовать "yes" и "no", но принцип остается таким же). Таким образом можно проэкзаменовать каждую голову внимания и посмотреть, насколько хорошо из её query и key извлекаются правильные ответы (условно говоря, насколько хорошо голова "решает" логические задачки).
Задачки различались по степени сложности: во-первых, по количеству логических шагов, которые нужно предпринять для нахождения ответа ("steps" на рис. 2), а во-вторых, по количеству нерелевантных, шумных элементов в условии ("distractors" на рис. 2).
В статье было проанализировано много разных моделей (от 1.5B до 70B), и везде нашлись головы, которые "решают" сложные (5 шагов/5 дистракторов) задачки лучше, чем сама модель (если ответ модели оценивать по логитам, аналогично тому, как это делается в MCQA задачах). Более того, часть таких "хороших" голов, отобранных на валидационной выборке одного датасета, сохраняет высокое качество и на других датасетах, являясь более-менее универсальными. Мы выдвигаем гипотезу, что именно эти головы могут отвечать за логические рассуждения в модели.
Этот феномен аналогичен тому, что происходит в MCQA задачах (см. ссылки на разбор статьи выше): модель находит правильный ответ на задачу/вопрос где-то на промежуточных слоях, но этот ответ, по каким-то причинам, не всегда доходит до финального слоя. При чем, что интересно, чем сложнее задача, тем чаще правильный ответ не доходит до выхода. А это значит, что все рассмотренные модели не полностью раскрывают свой потенциал и имеют пространство для улучшения.
#объяснения_статей
BY Техножрица 👩💻👩🏫👩🔧

Share with your friend now:
group-telegram.com/tech_priestess/2034