
group-telegram.com/techsparks/4953
Last Update:
Очень полезная, хотя и непростая для чтения как любой научный текст, статья в Nature посвящена, на первый взгляд, довольно узкой задаче: использованию больших языковых моделей в процессах поиска и открытия новых в чем-либо полезных материалов.
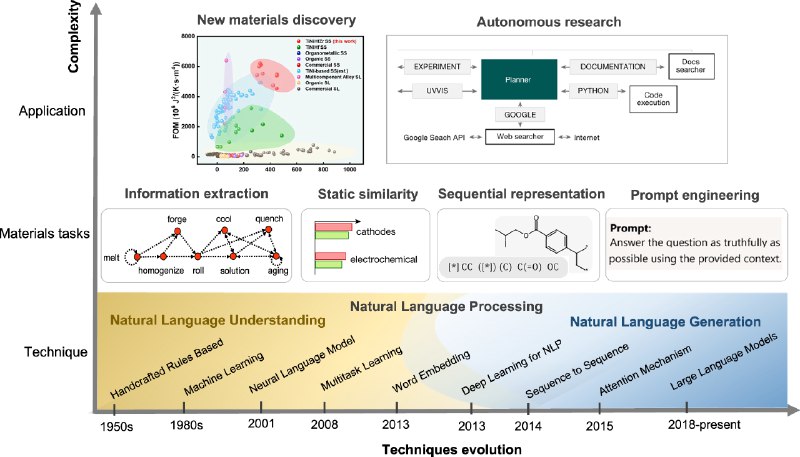
В начальных разделах статьи указывается, что технологии обработки естественного языка, позволили, наконец, содержательно обрабатывать весь массив когда-либо опубликованных работ по теме, извлекая из них данные, которые формируют большие обучающие выборки.
В разделе про LLM содержится важное замечание: Recently, LLMs have shown their ability in learning universal language representations, text understanding and generation. В итоге в конкретном исследуемом случае оказывается, что Leveraging semantic textual similarity, new materials with similar properties can be identified without human labeling or supervision.
Познавательно выглядит сравнение уже давно использовавшихся пайплайнов открытия новых материалов с использованием методов обработки естественного языка и новых возможностей, появившихся благодаря LLM. Описано, как и почему необходим файнтюнинг готовых моделей.
Речь и здесь уже идет о создании автономных агентов, способных целиком самостоятельно планировать и проводить исследования, причем — снова как люди — эти агенты по ходу дела обучаются и самосовершентвуются: In-context learning allows an AI agent to accumulate experience and evolve so that its actions become increasingly consistent, logical, and effective over time.
При внимательном чтении статья позволяет заглянуть в будущее научных исследований и понять логику, по которой это будущее создается. А еще — почувствовать объем нерешенных проблем, гарантирующих, что в обозримом будущем тем людям, кто создает автономный пайплайн научных открытий, безработица не грозит:)
А для особо любознательных открывается, насколько же наивна, безосновательна и слаба критика ИИ в научных исследованиях со стороны якобы экспертов. Им следует поизучать матчасть. Можно с этой статьи и начать.
https://www.nature.com/articles/s41524-025-01554-0
BY TechSparks
Share with your friend now:
group-telegram.com/techsparks/4953