
Reverse Thinking Makes LLMs Stronger Reasoners
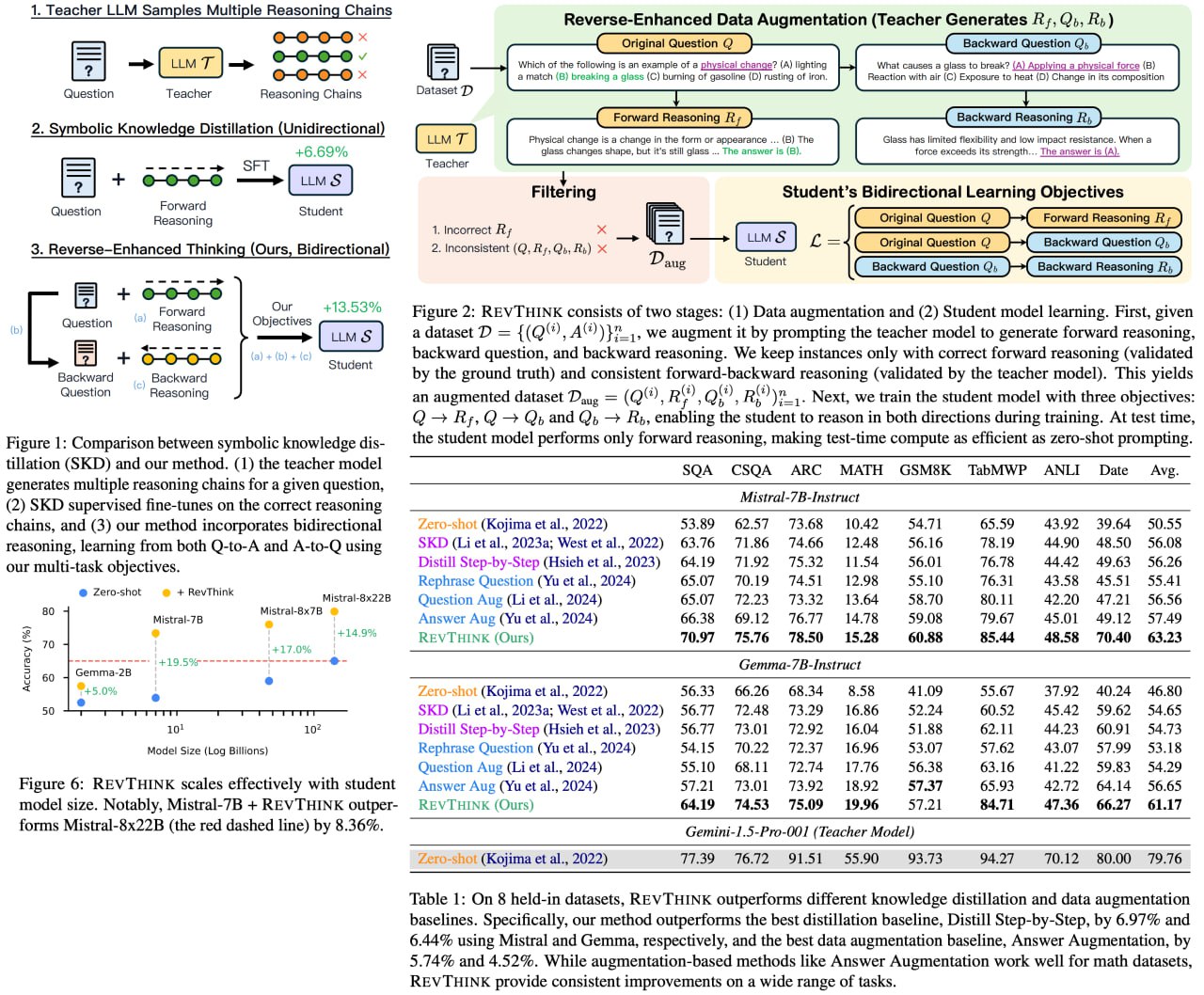
LLM всё не хотят думать, но люди их заставляют :) В статье авторы предлагают очередную попытку научить модель "рассуждать" лучше. Берут модель-учитель, для каждого исходного вопроса генерят обратный вопрос, и для обоих вопросов reasoning. Например: "У Джона 3 яблока, у Эммы 2 яблока; сколько у них всего яблок?" превращается в "У Джона и Эммы в сумме 5 яблок. Если у Эммы 2 яблока, сколько яблок у Джона?". Эдакая попытка заставить модель думать о вопросе с разных сторон. На этом учат модель-ученика.
Результаты положительные (а иначе статьи и не было бы): повышает точность моделей на 13.53%, демонстрирует sample efficiency, превосходя стандартный fine-tuning с 10% данных, и эффективно работает на out-of-distribution датасетах.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
LLM всё не хотят думать, но люди их заставляют :) В статье авторы предлагают очередную попытку научить модель "рассуждать" лучше. Берут модель-учитель, для каждого исходного вопроса генерят обратный вопрос, и для обоих вопросов reasoning. Например: "У Джона 3 яблока, у Эммы 2 яблока; сколько у них всего яблок?" превращается в "У Джона и Эммы в сумме 5 яблок. Если у Эммы 2 яблока, сколько яблок у Джона?". Эдакая попытка заставить модель думать о вопросе с разных сторон. На этом учат модель-ученика.
Результаты положительные (а иначе статьи и не было бы): повышает точность моделей на 13.53%, демонстрирует sample efficiency, превосходя стандартный fine-tuning с 10% данных, и эффективно работает на out-of-distribution датасетах.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
Annual Japanese Fest in Dubai
В прошлое воскресенье в Дубае прошел третий ежегодный Японский фестиваль https://linktr.ee/japanesefestival.
Я посещаю его уже второй раз, и это клёво. Было очень много людей, в основном японцев.
Сама площадка была разделено на две части.
Левая сторона была посвящена активностям. Там было много стендов с традиционными занятиями: Чайная церемония, икебана (аранжировка цветов), мастер-класс по оригами. Мне особенно понравился стенд с японской каллиграфией - мастер рисовала слова на веерах. Самые распространенные варианты - имена и пожелания благополучия. Кстати, она узнала меня - вспомнила, что я был там в прошлом году! Было много игр - стрельба, гача, перетягивание каната, ловля золотых рыбок и так далее. В основном это было ориентировано на детей, но взрослые тоже с удовольствием участовали.
Вторая часть площадки была отведена под еду и главную сцену. Там были разные выступления. Началось все с каллиграфии. Мастер со стенда рисовал на холстах два огромных кандзи. Было прям заметно, что махать огромной кистью ей было тяжело. К концу ее руки были полностью покрыты черной краской. Также были показательные выступления по кендо. И можно было посмотреть как дети бьют друг друга, то есть на демонстрацию карате.
И было много японских блюд. Мне понравилось мясо wagyu и уникальное мороженое - Hojicha Stracciatella Gelato. Его делают из японского обжаренного чая (да, именно обжаренного) и шоколадной крошкой.
Что было особенно приятно - я мог понимать большинство текстов и даже около 50% того, что говорили на главной сцене, благодаря изучению японского языка в этом году!
#life #dubai
В прошлое воскресенье в Дубае прошел третий ежегодный Японский фестиваль https://linktr.ee/japanesefestival.
Я посещаю его уже второй раз, и это клёво. Было очень много людей, в основном японцев.
Сама площадка была разделено на две части.
Левая сторона была посвящена активностям. Там было много стендов с традиционными занятиями: Чайная церемония, икебана (аранжировка цветов), мастер-класс по оригами. Мне особенно понравился стенд с японской каллиграфией - мастер рисовала слова на веерах. Самые распространенные варианты - имена и пожелания благополучия. Кстати, она узнала меня - вспомнила, что я был там в прошлом году! Было много игр - стрельба, гача, перетягивание каната, ловля золотых рыбок и так далее. В основном это было ориентировано на детей, но взрослые тоже с удовольствием участовали.
Вторая часть площадки была отведена под еду и главную сцену. Там были разные выступления. Началось все с каллиграфии. Мастер со стенда рисовал на холстах два огромных кандзи. Было прям заметно, что махать огромной кистью ей было тяжело. К концу ее руки были полностью покрыты черной краской. Также были показательные выступления по кендо. И можно было посмотреть как дети бьют друг друга, то есть на демонстрацию карате.
И было много японских блюд. Мне понравилось мясо wagyu и уникальное мороженое - Hojicha Stracciatella Gelato. Его делают из японского обжаренного чая (да, именно обжаренного) и шоколадной крошкой.
Что было особенно приятно - я мог понимать большинство текстов и даже около 50% того, что говорили на главной сцене, благодаря изучению японского языка в этом году!
#life #dubai
Linktree
japanesefestival | Instagram | Linktree
Linktree. Make your link do more.
{kind=link}
{kind=link}
How to use AI to write articles about how to use AI as a product manager for your AI app on your journey to being replaced by an AI product manager
Andrew Ng опубликовал мини-блог пост AI Product Management. К сожалению, текст настолько generic, что его очень красочно описали на ycombinator
Andrew Ng опубликовал мини-блог пост AI Product Management. К сожалению, текст настолько generic, что его очень красочно описали на ycombinator
{kind=link}
Byte Latent Transformer: Patches Scale Better Than Tokens
Новая статья от META - Byte Latent Transformer. Пробуют новый подход к токенизации - вместо фиксированного словаря используют динамические patches, размер которых определяется по энтропии следующего байта. Модель успешно масштабировали до 8B параметров и 4T байтов, при этом с лучшим качеством. Плюс эффективность и тренировки, и инференса лучше. Каких-то особых недостатков подхода авторы не описали. Ждём Llama 4 на байтах? :)
Paper link
Code link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Новая статья от META - Byte Latent Transformer. Пробуют новый подход к токенизации - вместо фиксированного словаря используют динамические patches, размер которых определяется по энтропии следующего байта. Модель успешно масштабировали до 8B параметров и 4T байтов, при этом с лучшим качеством. Плюс эффективность и тренировки, и инференса лучше. Каких-то особых недостатков подхода авторы не описали. Ждём Llama 4 на байтах? :)
Paper link
Code link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
Falcon 3
Институт в Абу-Даби выпустил новую версию своей модели, блогпост на huggingface тут.
Модели размером от 1B до 10B. Одна из моделей - Mamba. Уверяют, что модель на 3B лучше, чем Llama 3.1-8B
#datascience
Институт в Абу-Даби выпустил новую версию своей модели, блогпост на huggingface тут.
Модели размером от 1B до 10B. Одна из моделей - Mamba. Уверяют, что модель на 3B лучше, чем Llama 3.1-8B
#datascience
{kind=link}
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Новая версия всем известного BERT. Авторы обновили архитектуру, добавили модные трюки для оптимизации тренировки, досыпали данных. Получили SOTA на большинстве бенчмарков.
Было интересно почитать какие изменения появились за 6 лет. В конце статьи авторы ещё подробно описывали эксперименты и мысли. Из забавного: "проблема первого мира" - если в батче 500к-1млн семплов, то дефолтный семплер в Pytorch плохо рандомит. Авторам пришлось взять ссемплер из Numpy.
А ещё интересное - один из авторов недавно взял соло золото в соревновании на каггле и занял 4-е место в общем рейтинге соревнований.
Paper
Code
Weights
Blogpost
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Новая версия всем известного BERT. Авторы обновили архитектуру, добавили модные трюки для оптимизации тренировки, досыпали данных. Получили SOTA на большинстве бенчмарков.
Было интересно почитать какие изменения появились за 6 лет. В конце статьи авторы ещё подробно описывали эксперименты и мысли. Из забавного: "проблема первого мира" - если в батче 500к-1млн семплов, то дефолтный семплер в Pytorch плохо рандомит. Авторам пришлось взять ссемплер из Numpy.
А ещё интересное - один из авторов недавно взял соло золото в соревновании на каггле и занял 4-е место в общем рейтинге соревнований.
Paper
Code
Weights
Blogpost
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
Data, Stories and Languages
DataFest Yerevan Я завтра выступаю на DataFest Yerevan с рассказом про применение face recognition для выявления множественных аккаунтов одного человека. Блогпост про это я уже публиковал. По идее при регистрации на сайте https://datafest.am/2024 должна…
И вот доклады выложили на youtube!
https://www.youtube.com/watch?v=hieJhU9J3e0&list=PLvwlJZXG6IkVRkSDyJsPmcBXw25Nm7_yt&index=16
По ссылке можно посмотреть как мой доклад, так и остальные. Из забавного: с 17:40 на протяжении шести минут я отвечал на вопросы одного очень любознательного человека. Надеюсь, что это был не один из фродстеров :) И надеюсь, что я не сказал ничего лишнего 👀
#datascience
https://www.youtube.com/watch?v=hieJhU9J3e0&list=PLvwlJZXG6IkVRkSDyJsPmcBXw25Nm7_yt&index=16
По ссылке можно посмотреть как мой доклад, так и остальные. Из забавного: с 17:40 на протяжении шести минут я отвечал на вопросы одного очень любознательного человека. Надеюсь, что это был не один из фродстеров :) И надеюсь, что я не сказал ничего лишнего 👀
#datascience
YouTube
Fraud Detection via Face Recognition
Speaker: Andrei Lukianenko (Careem)
Topic: Fraud Detection via Face Recognition
DataFest Yerevan 2024, https://datafest.am/
Topic: Fraud Detection via Face Recognition
DataFest Yerevan 2024, https://datafest.am/
🤖 Папка ИИ
Под конец этого года коллеги из «ГОС ИТ Богатырёва» собрали нейрокрутую папку с каналами про ИИ и технологии, в которую включили и меня. Актуальные новости, советы по работе с LLM и многое другое.
Добавляйте папку и делитесь со своими друзьями.
Под конец этого года коллеги из «ГОС ИТ Богатырёва» собрали нейрокрутую папку с каналами про ИИ и технологии, в которую включили и меня. Актуальные новости, советы по работе с LLM и многое другое.
Добавляйте папку и делитесь со своими друзьями.
Telegram
ИИ и техно
Polina invites you to add the folder “ИИ и техно”, which includes 24 chats.
И снова о том, как современные LLM увеличивают разницу между экспертами и новичками
Уже давно идут бурные обсуждения того, что благодаря LLM разница между сеньорами и джунами всё растёт и растёт - ибо опытные люди знают что и как спросить, могут поймать ошибки, могут подтолкнуть ботов в нужную сторону.
Сегодня я наткнулся на тредик на реддите. Автор жалуется, что o1 pro (который за 200$) бесполезен для написания кода.
Самый топовый ответ - "Type out a very detailed document that explains exactly what you want from your code - it could be several pages in length. Then feed that whole document into o1-pro and just let it do its thing. Afterwards, you can switch to 4o if you want to do minor adjustments using Canvas."
То есть предлагается написать полноценное детальное техзадание, которое бот сможет выполнить по шагам.
В том, насколько такое вообще работает я не уверен - не пробовал. Но если это действительно так, то это, опять же лишь "упрощает" работу сеньоров. Написать качественное детальное тз - это серьёзная задача, не все это могут.
Интересно наблюдать за тем, как индустрия безумно быстро двигается в некоторых направлениях.
#datascience
Уже давно идут бурные обсуждения того, что благодаря LLM разница между сеньорами и джунами всё растёт и растёт - ибо опытные люди знают что и как спросить, могут поймать ошибки, могут подтолкнуть ботов в нужную сторону.
Сегодня я наткнулся на тредик на реддите. Автор жалуется, что o1 pro (который за 200$) бесполезен для написания кода.
Самый топовый ответ - "Type out a very detailed document that explains exactly what you want from your code - it could be several pages in length. Then feed that whole document into o1-pro and just let it do its thing. Afterwards, you can switch to 4o if you want to do minor adjustments using Canvas."
То есть предлагается написать полноценное детальное техзадание, которое бот сможет выполнить по шагам.
В том, насколько такое вообще работает я не уверен - не пробовал. Но если это действительно так, то это, опять же лишь "упрощает" работу сеньоров. Написать качественное детальное тз - это серьёзная задача, не все это могут.
Интересно наблюдать за тем, как индустрия безумно быстро двигается в некоторых направлениях.
#datascience
{kind=link}