RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
#rag
Сегодня продолжу развивать тему RAG, поэтому подготовил для вас разбор свежей статьи RAPTOR. Этот подход устраняет проблему, когда LLM задают тематические вопросы, требующие полного знания целого документа или даже нескольких. Примером такого запроса может быть "Как именно князь Гвидон достиг своего могущества?". Любая система RAG извлечет множество релевантных фрагментов текста по данному запросу, однако они не дадут полной картины, потому что для этого нужно знать все содержание книги. И мы получаем проблему - чем больше фрагментов текста вы включаете в запрос, тем меньше вам нужен RAG.
Что же делает RAPTOR?🦖
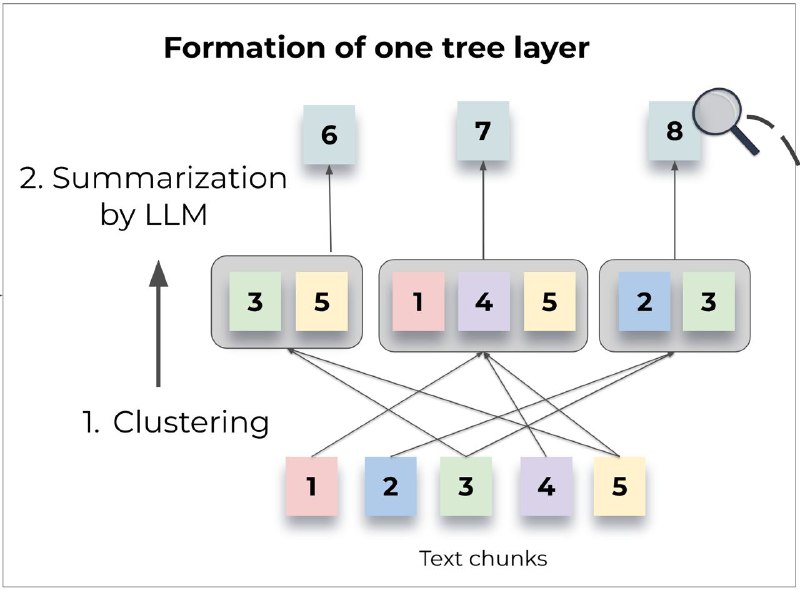
Вместо разделения документов на маленькие фрагменты и сохранения их в векторную БД для последующего извлечения, RAPTOR сначала их кластеризует, а после суммаризует каждый кластер с помощью LLM. Он повторяет этот процесс итерационно, пока не остается один, финальный фрагмент текста, в котором содержится вся информация документа. Все это извлекается в общих чертах с готовой суммаризированной информацией, а если необходимы факты, то можно опуститься на слой ниже и извлечь более детальное summary.
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
#rag
Сегодня продолжу развивать тему RAG, поэтому подготовил для вас разбор свежей статьи RAPTOR. Этот подход устраняет проблему, когда LLM задают тематические вопросы, требующие полного знания целого документа или даже нескольких. Примером такого запроса может быть "Как именно князь Гвидон достиг своего могущества?". Любая система RAG извлечет множество релевантных фрагментов текста по данному запросу, однако они не дадут полной картины, потому что для этого нужно знать все содержание книги. И мы получаем проблему - чем больше фрагментов текста вы включаете в запрос, тем меньше вам нужен RAG.
Что же делает RAPTOR?🦖
Вместо разделения документов на маленькие фрагменты и сохранения их в векторную БД для последующего извлечения, RAPTOR сначала их кластеризует, а после суммаризует каждый кластер с помощью LLM. Он повторяет этот процесс итерационно, пока не остается один, финальный фрагмент текста, в котором содержится вся информация документа. Все это извлекается в общих чертах с готовой суммаризированной информацией, а если необходимы факты, то можно опуститься на слой ниже и извлечь более детальное summary.
The channel appears to be part of the broader information war that has developed following Russia's invasion of Ukraine. The Kremlin has paid Russian TikTok influencers to push propaganda, according to a Vice News investigation, while ProPublica found that fake Russian fact check videos had been viewed over a million times on Telegram. But the Ukraine Crisis Media Center's Tsekhanovska points out that communications are often down in zones most affected by the war, making this sort of cross-referencing a luxury many cannot afford. As a result, the pandemic saw many newcomers to Telegram, including prominent anti-vaccine activists who used the app's hands-off approach to share false information on shots, a study from the Institute for Strategic Dialogue shows. Telegram boasts 500 million users, who share information individually and in groups in relative security. But Telegram's use as a one-way broadcast channel — which followers can join but not reply to — means content from inauthentic accounts can easily reach large, captive and eager audiences. The War on Fakes channel has repeatedly attempted to push conspiracies that footage from Ukraine is somehow being falsified. One post on the channel from February 24 claimed without evidence that a widely viewed photo of a Ukrainian woman injured in an airstrike in the city of Chuhuiv was doctored and that the woman was seen in a different photo days later without injuries. The post, which has over 600,000 views, also baselessly claimed that the woman's blood was actually makeup or grape juice.
from us