
group-telegram.com/nn_for_science/2337
Last Update:
Как создавать LLM-агентов без лишней головной боли
(Личный опыт и наблюдения из практики Anthropic)
Знаете, похоже, годом агентов станет 2025-й. В уходящем году мы все пытались сделать их по-настоящему надёжными, и, кажется, не зря старались! К 2025-му главным стало не то, насколько "крут" твой агент, а умение собрать систему, которая реально решает конкретные задачи.
Недавно ребята из Anthropic поделились своими находками о том, как делать рабочих агентов без лишних сложностей. Давайте разберём самое важное.
🐨 Начинаем с простого
Первым делом чётко определите, что вам нужно от модели. Может, это перевод текста? Или рефакторинг кода? Или генерация контента? Не пытайтесь впихнуть всё и сразу в один вызов — это путь к хаосу.
Обязательно проверяйте результаты. Тесты, сравнение с эталонами, внутренние метрики — всё это покажет, насколько хорош ваш агент. Заметили слабое место? Усильте промпты или добавьте простую проверку.
Начните с базовых схем. Например, один вызов LLM для основной задачи и ещё один для проверки. Работает? Отлично! Усложнять будете только когда реально припрёт.
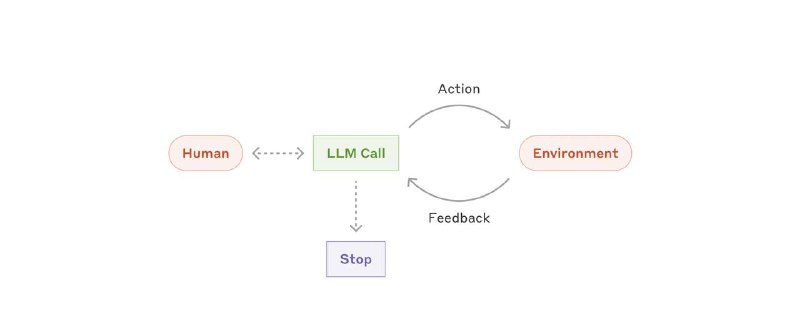
🕵️ Когда действительно нужны агенты
Агенты сами решают, какие инструменты использовать и в каком порядке. Иногда без этого не обойтись, особенно в сложных задачах, где заранее все шаги не пропишешь. Но имейте в виду: за такую свободу придётся платить — больше вычислений, больше времени, больше шансов накосячить.
Возьмём, к примеру, код-агента, который может работать с несколькими файлами и сам решает, как их править. Круто, но не забудьте про стоп-краны — ограничьте число итераций, чтобы агент не ушёл в бесконечный цикл.
🐋 Три кита агентостроения
1. Простота: чем меньше навороченной логики, тем легче жить
2. Прозрачность: должно быть видно, как агент планирует свои действия и какие подсказки получает
3. Понятный интерфейс: подробная документация, примеры, инструкции — чем яснее описано, что умеет агент, тем меньше сюрпризов
🦜⛓️💥 А как же фреймворки?
Да, есть куча готовых инструментов — LangGraph в LangChain, Amazon Bedrock's AI Agent и другие. С ними можно быстро начать, но под капотом там часто такие дебри, что отладка превращается в квест.
Мой совет: если код начинает напоминать чёрную магию — попробуйте вернуться к основам. Простые вызовы LLM, чёткое разделение задач, всё под вашим контролем.
👌 Практические советы
- Если задачу решают пара простых промптов — не городите огород
- Тестируйте как ненормальные: автотесты, сравнение с эталонами, сквозные сценарии
- Добавляйте проверки: пусть отдельный LLM или простой код следит, не пошло ли что-то не так
- Не бойтесь микшировать разные подходы: маршрутизация, параллельные вычисления, оценка-оптимизация — главное, не всё сразу
💻 Живой пример: рефакторим код
1. Начинаем просто: LLM читает файл и советует, как переименовать переменные
2. Если работает — расширяемся: добавляем центральный LLM, который раздаёт задачи "рабочим"
3. Проверяем результат: второй LLM или человек просматривает изменения перед мержем
🦆 Главное, что я понял
Успех с LLM — это не про создание монстра, который всё умеет. Это про простую, точную, управляемую систему на которую можно положиться (reliability). Начинайте с малого, держите всё на виду и усложняйте только по необходимости.
P.S. Если вдруг захотите своего помощника в стиле Cursor Agent — сначала чётко определите, к каким файлам и функциям он получит доступ. Давать агенту права на запись в репу иногда страшновато, но когда он начинает экономить время и нервы — это того стоит!
Блог-пост по агентостроению стоит почитать, потому что там намного больше четких схем и разобранных кейсов использования.
А как вы подходите к созданию LLM-агентов? Какие инструменты используете? Делитесь опытом в комментариях 🚀
BY AI для Всех
Share with your friend now:
group-telegram.com/nn_for_science/2337